Panoramica
- Comprendi Spark Streaming e come funziona.
- Scopri Windows su Spark Streaming con un esempio.
introduzione
Secondo IBM, il 60% di tutte le informazioni sensoriali perde valore in pochi millisecondi se non si agisce. Tenendo conto che il mercato dei Big Data e dell'analytics ha raggiunto il $ 125 miliardi e gran parte di questo sarà attribuito all'IoT in futuro, l'incapacità di sfruttare le informazioni in tempo reale si tradurrà in miliardi di dollari di perdite.
Esempi di alcune di queste applicazioni includono una società di telecomunicazioni, che calcola quanti dei suoi utenti hanno utilizzato WhatsApp negli ultimi 30 minuti, un rivenditore che tiene traccia del numero di persone che oggi hanno detto cose positive sui propri prodotti sui social media, o un'agenzia delle forze dell'ordine che cerca un sospetto utilizzando i dati sul traffico CCTV.
Esta es la razón principal por la que los sistemas de procesamiento de flujos como Spark Streaming definirán el futuro de la analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche.... in tempo reale. C'è anche una crescente necessità di analizzare sia i dati a riposo che i dati in movimento per alimentare le applicazioni., cosa rende i sistemi come Spark, possono fare entrambe le cose, essere ancora più attraente e potente. È un sistema per tutte le stagioni dei Big Data.
Imparerai come Spark Streaming non solo mantiene intatta la familiare API Spark, ma anche, underhood, utilizza RDD per l'archiviazione e la tolleranza ai guasti. Ciò consente ai professionisti di Spark di entrare nel mondo dello streaming fin dall'inizio.. Con quello in mente, andiamo subito al dunque.
Introducción a Spark Streaming | de Harshit Agarwal | Metà
Sommario
- Apache SparkApache Spark è un motore di elaborazione dati open source che consente l'analisi di grandi volumi di informazioni in modo rapido ed efficiente. Il suo design si basa sulla memoria, che ottimizza le prestazioni rispetto ad altri strumenti di elaborazione batch. Spark è ampiamente utilizzato nelle applicazioni di big data, Apprendimento automatico e analisi in tempo reale, grazie alla sua facilità d'uso e...
- Ecosistema Apache Spark
- Spark in streaming: DStreams
- Spark in streaming: contesto di trasmissione
- Esempio: conteggio delle parole
- Spark in streaming: Finestra
- Una finestra basata su: conteggio delle parole
- un (più efficiente) basato su finestre: conteggio delle parole
- Spark in streaming: operazioni di uscita
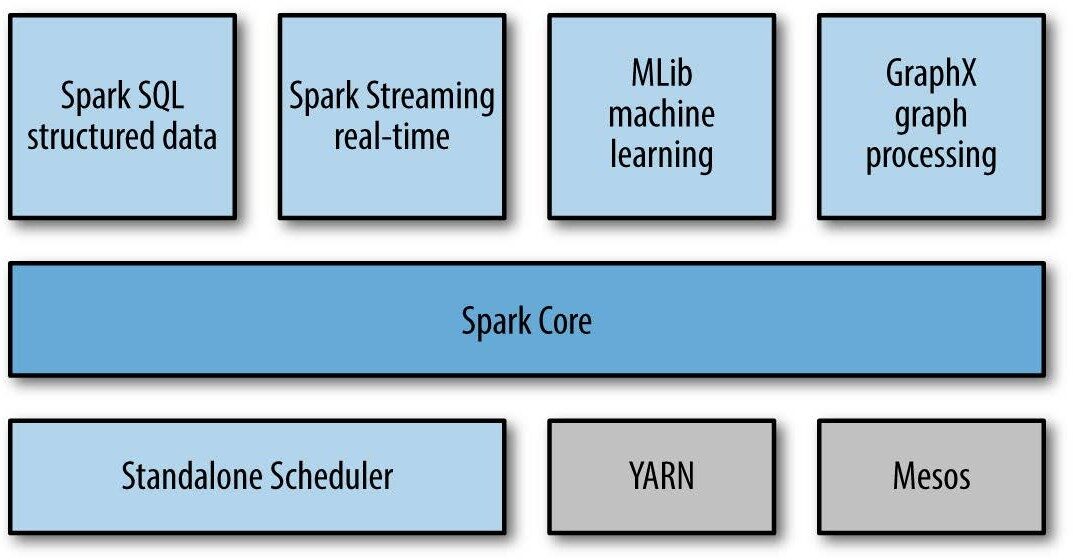
Apache Spark
Apache Spark è un motore di elaborazione unificato e un set di librerie per l'elaborazione parallela dei dati su cluster di computer. Al momento di scrivere questo articolo, Spark è il motore open source più sviluppato per questo compito, rendendolo uno strumento standard per qualsiasi sviluppatore o data scientist interessato ai big data.
Spark supporta diversi linguaggi di programmazione ampiamente utilizzati (Pitone, Giava, Scala y R), include librerie per varie attività che vanno da SQL allo streaming al machine learning, e corre ovunque, da un laptop a un grappoloUn cluster è un insieme di aziende e organizzazioni interconnesse che operano nello stesso settore o area geografica, e che collaborano per migliorare la loro competitività. Questi raggruppamenti consentono la condivisione delle risorse, Conoscenze e tecnologie, promuovere l'innovazione e la crescita economica. I cluster possono coprire una varietà di settori, Dalla tecnologia all'agricoltura, e sono fondamentali per lo sviluppo regionale e la creazione di posti di lavoro.... de miles de servidores. Ciò lo rende un sistema facile da avviare e scalare fino all'elaborazione di big data o su scala incredibilmente ampia.. Di seguito sono riportate alcune delle caratteristiche di Spark:
-
Motore veloce e multiuso per l'elaborazione di dati su larga scala
-
Spark può supportare in modo efficiente più tipi di calcoli
-
Può leggere / scrivere su qualsiasi sistema compatibile con Hadoop (ad esempio, HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni..)
- Velocità: archiviazione dei dati in memoria per query iterative molto veloci
-
el sistema también es más eficiente que Riduci mappaMapReduce è un modello di programmazione progettato per elaborare e generare in modo efficiente set di dati di grandi dimensioni. Sviluppato da Google, Questo approccio suddivide il lavoro in attività più piccole, che sono distribuiti tra più nodi in un cluster. Ogni nodo elabora la sua parte e poi i risultati vengono combinati. Questo metodo consente di scalare le applicazioni e gestire enormi volumi di informazioni, essere fondamentali nel mondo dei Big Data.... para aplicaciones complejas que se ejecutan en el disco
-
fino a 40 volte più veloce di Hadoop
-
Acquisisci dati da molte fonti: Kafka, Twitter, HDFS, socket TCP
-
I risultati possono essere inviati ai file system, banche dati, pannelli dal vivo, ma non solo
-

Ecosistema Apache Spark
Di seguito sono riportati i componenti dell'ecosistema Apache Spark:
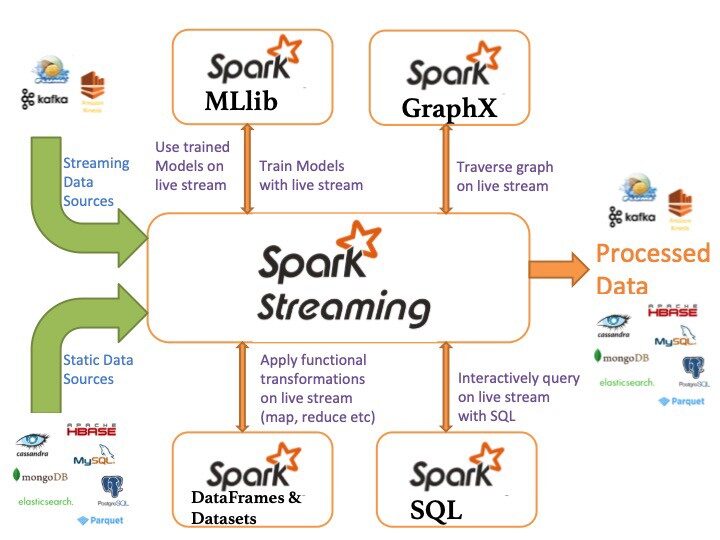
- Nucleo Scintilla: funzionalità di base di Spark (pianificazione delle attività, gestione della memoria, ripristino dei guasti, interazione con i sistemi di archiviazione).
-
Spark SQL: pacchetto per lavorare con dati strutturati interrogati tramite SQL e HiveQL
-
Spark in streaming: un componente che consente l'elaborazione di flussi di dati in tempo reale (ad esempio, log files, messaggi di aggiornamento di stato)
- MLLib: MLLib è una libreria di apprendimento automatico come Mahout. È basato su Spark e ha la capacità di supportare molti algoritmi di apprendimento automatico.
- GraficoX: Per grafici e calcoli grafici, Spark ha il proprio motore di calcolo grafico, chiamato GraphX. È simile ad altri strumenti di elaborazione grafica o database ampiamente utilizzati, come Neo4j, Giraffe e molti altri database grafici distribuiti.
Spark in streaming: astrazioni
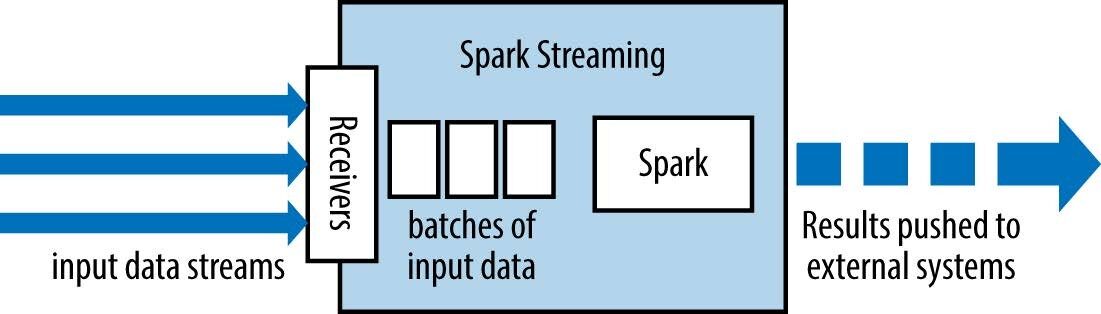
Spark Streaming ha un architettura micro batch come segue:
-
tratta la trasmissione come una serie di batch di dati
-
Nuovi batch vengono creati a intervalli di tempo regolari.
-
la dimensione degli intervalli di tempo è chiamata lotto rottura
-
l'intervallo batch è solitamente compreso tra 500 ms e diversi secondi
Il valore di riduzione di ogni finestra viene calcolato in modo incrementale.
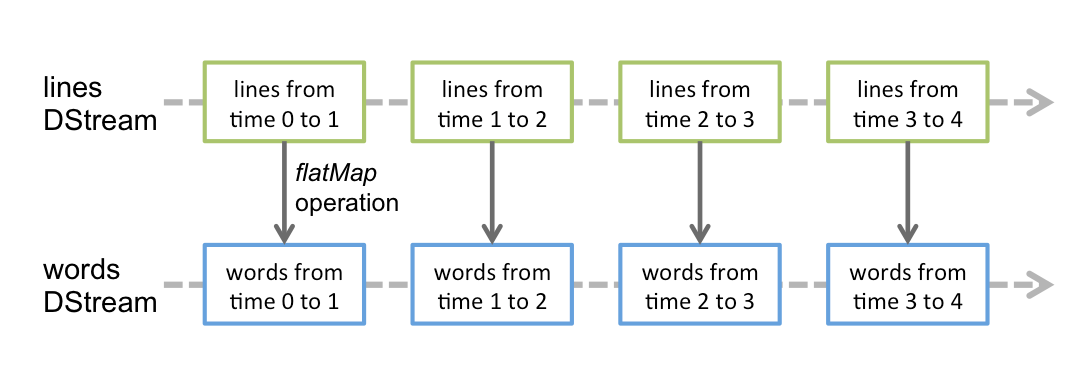
Sequenza discretizzata (DStream)
Corrente discretizzata oh DStream è l'astrazione di base fornita da Spark Streaming. Rappresenta un flusso continuo di dati, o il flusso di dati di input ricevuto dalla sorgente o il flusso di dati elaborati generato trasformando il flusso di input. Internamente, un DStream è rappresentato da una serie continua di RDD, che è l'astrazione di Spark di un set di dati distribuito e immutabile (guarda Guida alla programmazione Spark per ulteriori dettagli). Ogni RDD in un DStream contiene dati di un certo intervallo.
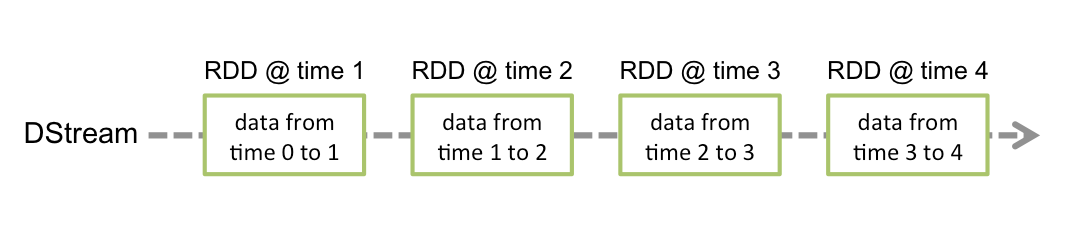
- Le trasformazioni RDD sono calcolate dal motore Spark
-
Le operazioni DStream nascondono la maggior parte di questi dettagli
-
Qualsiasi operazione applicata in un DStream si traduce in operazioni negli RDD sottostanti.
-
Il valore di riduzione di ogni finestra viene calcolato in modo incrementale.
Spark in streaming: contesto di trasmissione
È il punto di ingresso principale per la funzionalità di Spark Streaming. Fornisce i metodi utilizzati per creare DStreams da varie sorgenti di ingresso. Streaming Spark può essere creato fornendo un URL Spark Master e il nome dell'applicazione, o da una configurazione org.apache.spark.SparkConf, o desde un org.apache.spark.SparkContext esistente. È possibile accedere allo SparkContext associato utilizzando context.sparkContext.
Dopo aver creato e trasformato DStreams, lo streaming computing può essere avviato e interrotto utilizzando context.start() e, rispettivamente. context.awaitTermination() consente al thread corrente di attendere la terminazione del contesto entro stop() o per un'eccezione.
Per eseguire un'applicazione SparkStreaming, dobbiamo definire StreamingContext. SparkContext è specializzato per le applicazioni di streaming.
Il contesto di streaming in Java può essere definito come segue:
JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, batchInterval);
dove:
-
Maestro è un URL del cluster Spark, Mesos o FILATOYARN è un gestore di pacchetti per JavaScript che consente l'installazione e la gestione efficiente delle dipendenze nei progetti di sviluppo. Sviluppato da Facebook, Si caratterizza per la sua velocità e sicurezza rispetto ad altri gestori. YARN utilizza un sistema di cache per ottimizzare le installazioni e fornisce un file di blocco per garantire la coerenza delle versioni delle dipendenze tra i diversi ambienti di sviluppo....; per eseguire il codice in modalità locale, utilizzo “Locale[K]"Dove K> = 2 rappresenta il parallelismo
-
nome dell'applicazione è il nome della tua applicazione
-
intervallo batch Intervallo di tempo (in secondi) di ogni lotto
Una volta costruito, offrire due tipi di operazioni:
Alcuni esempi sono: carta geografica (), filtro () y riduciByKey ()
-
-
trasformazioni stateful: utilizza i dati dei lotti precedenti per calcolare i risultati del lotto corrente. Includi finestre scorrevoli, monitoraggio dello stato nel tempo, eccetera.
-
Nota che un contesto di streaming può essere avviato solo una volta e deve essere avviato dopo aver configurato tutti i DStream e le operazioni di output.
Fonti di dati di base
Le origini dati di base di Spark Streaming sono elencate di seguito:
- Stream di file: Utilizzato per leggere dati da file su qualsiasi file system compatibile con HDFS API (vale a dire, HDFS, S3, NFS, eccetera.), puoi creare un DStream come:
... = streamingContext.fileStream<...>(directory);
- Stream basati su ricevitori personalizzati: I DStream possono essere creati con flussi di dati ricevuti tramite ricevitori personalizzati, estendendo la classe del ricevitore
... = streamingContext.queueStream(coda di RDD)
- Coda RDD come flusso: Per testare un'applicazione Spark Streaming con dati di test, puoi anche creare un DStream basato su una coda RDD, usando
... = streamingContext.queueStream(coda di RDD)
La maggior parte delle trasformazioni ha la stessa sintassi applicata agli RDD
-
Trasformazione
Senso
Carta geografica (funzione)
Restituisce un nuovo DStream passando ogni elemento del DStream sorgente attraverso una funzione func.
mappa piatta (funzione)
Simile alla mappa, ma ogni elemento di input può essere assegnato a 0 o più elementi di output.
filtro (funzione)
Restituisce un nuovo DStream selezionando solo i record dal DStream di origine dove func restituisce true.
Unione (altroStream)
Restituisce un nuovo DStream che contiene l'unione degli elementi del DStream sorgente e di otherDStream.
aderire (un altro flusso)
Quando vengono chiamati due DStream a due coppie (K, V) e (K, W), restituisce un nuovo DStream di (K, (V, W)) si accoppia con tutte le coppie di elementi per ogni chiave.
Esempio: conteggio delle parole
SparkConf sparkConf = nuova SparkConf()
.setMaster("Locale[2]").setAppName("WordCount");
JavaStreamingContext ssc = ...
JavaReceiverInputDStream<Corda> righe = ssc.socketTextStream( ... );
JavaDStream<Corda> parole = lines.flatMap(...);
Metodo JavaPairdStream<Corda, Numero intero> wordCounts = words
.mapToPair(s -> nuovo Tuple2<>(S, 1))
.reduceByKey((i1, i2) -> i1 + i2);
wordCounts.print();
Spark in streaming: Finestra
La funzione finestra più semplice è una finestra, che consente di creare un nuovo DStream, calculado aplicando los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... de ventana al antiguo DStream. È possibile utilizzare qualsiasi operazione DSTREAM nel nuovo flusso, in modo da ottenere tutta la flessibilità che desideri.
I calcoli nelle finestre consentono di applicare trasformazioni su una finestra di dati scorrevole. Qualsiasi operazione di finestra deve specificare due parametri:
- finestra lungo
- La durata della finestra in secondi.
- slittamento rottura
- Intervallo in cui l'operazione della finestra viene eseguita in secondi.
- Questi parametri devono essere multipli dell'intervallo batch.
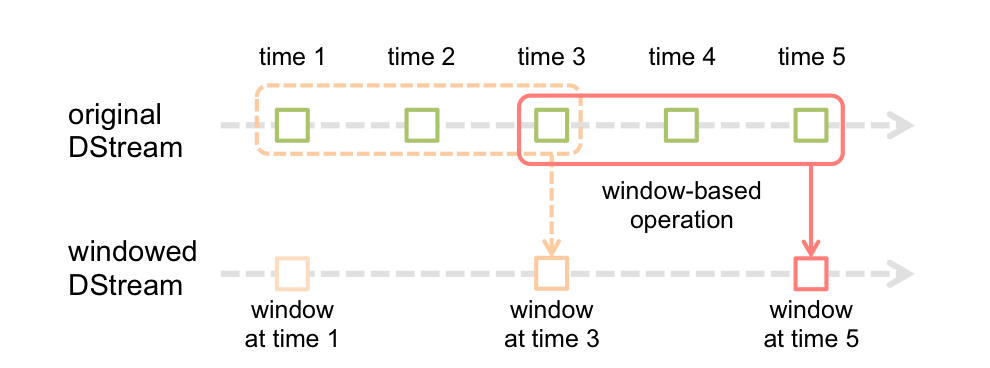
finestra(finestraLunghezza, slideInterval)
Restituisce un nuovo DStream calcolato in base ai batch nella finestra.
...
JavaStreamingContext ssc = ...
JavaReceiverInputDStream<Corda> linee = ...
JavaDStream<Corda> linesInWindow =
lines.window(WINDOW_SIZE, SLIDING_INTERVAL);
Metodo JavaPairdStream<Corda, Numero intero> wordCounts = linesInWindow.flatMap(SPLIT_LINE)
.mapToPair(s -> nuovo Tuple2<>(S, 1))
.reduceByKey((i1, i2) -> i1 + i2);
- reduceByWindow (funzione, InvFunc, finestraLunghezza, slideInterval)
- Restituisce una nuova sequenza di un singolo elemento, creato aggiungendo elementi nella sequenza durante un intervallo di scorrimento utilizzando funzione (che deve essere associativo).
- Il valore di riduzione di ogni finestra viene calcolato in modo incrementale.
- reduceByKeyAndWindow (funzione, InvFunc, finestraLunghezza, slideInterval)
- Quando si chiama in un DStream di (K, V) Coppie, restituisce un nuovo DStream di (K, V) coppie in cui i valori per ogni chiave vengono aggiunti utilizzando la funzione di riduzione specificata funzione su lotti in una finestra scorrevole.
Per eseguire queste trasformazioni, dobbiamo definire una directory di checkpoint
Basato su finestre: conteggio delle parole
...
Metodo JavaPairdStream<Corda, Numero intero> wordCountPairs = ssc.socketTextStream(...)
.mappa piatta(x -> Arrays.asList(SPAZIO.SPLIT(X)).Iteratore())
.mapToPair(s -> nuovo Tuple2<>(S, 1));
Metodo JavaPairdStream<Corda, Numero intero> wordCounts = wordCountPairs
.reduceByKeyAndWindow((i1, i2) -> i1 + i2, WINDOW_SIZE, SLIDING_INTERVAL);
wordCounts.print();
wordCounts.foreachRDD(nuovo SaveAsLocalFile());
un (più efficiente) basato su finestre: conteggio delle parole
In una versione più efficiente, Il valore di riduzione di ogni finestra viene calcolato in modo incrementale.
Si noti che i checkpoint devono essere abilitati per utilizzare questa operazione.
... ssc.checkpoint(LOCAL_CHECKPOINT_DIR); ... Metodo JavaPairdStream<Corda, Numero intero> wordCounts = wordCountPairs.reduceByKeyAndWindow( (i1, i2) -> i1 + i2, (i1, i2) -> i1 - i2, WINDOW_SIZE, SLIDING_INTERVAL);
Spark in streaming: operazioni di uscita
Las operaciones de salida permiten que los datos de DStream se envíen a sistemas externos como una Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... o un sistema de archivos
-
Esci dall'operazione
Senso
Stampa()
Imprime los primeros diez elementos de cada lote de datos en un DStream en el nodoNodo è una piattaforma digitale che facilita la connessione tra professionisti e aziende alla ricerca di talenti. Attraverso un sistema intuitivo, Consente agli utenti di creare profili, condividere esperienze e accedere a opportunità di lavoro. La sua attenzione alla collaborazione e al networking rende Nodo uno strumento prezioso per chi vuole ampliare la propria rete professionale e trovare progetti in linea con le proprie competenze e obiettivi.... del controlador que ejecuta la aplicación.
salva come file di testo (prefisso, [suffisso])
Salva il contenuto di questo DStream come file di testo. Il nome del file in ogni intervallo batch viene generato in base al prefisso.
salva come file Hadoop (prefisso, [suffisso])
Salva il contenuto di questo DStream come file Hadoop.
salva come file oggetto (prefisso, [suffisso])
Salva il contenuto di questo DStream come SequenceFiles di oggetti Java serializzati.
foreachRDD (funzione)
Operatore di output generico che applica una funzione, funzione, ad ogni RDD generato dalla sequenza.
Riferimenti in linea
• Documentazione Spark
• Documentazione Spark
conclusione
Dovrebbe essere chiaro che Spark Streaming rappresenta un modo potente di scrivere applicazioni di streaming. Prendere un lavoro batch che stai già eseguendo e convertirlo in un lavoro di streaming senza quasi nessuna modifica al codice è semplice ed estremamente utile da un punto di vista ingegneristico se hai bisogno che questo lavoro interagisca strettamente con il resto della tua applicazione di elaborazione..
Ti consiglio di consultare le seguenti risorse di ingegneria dei dati per migliorare le tue conoscenze:
Se ti è piaciuto l'articolo, lascia un commento nella sezione commenti qui sotto.





