Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
La scienza dei dati è un campo emergente con numerose opportunità di lavoro. Dobbiamo tutti aver sentito parlare delle migliori competenze nella scienza dei dati. per iniziare, l'abilità più semplice ed essenziale che ogni aspirante di data science dovrebbe acquisire è SQL.
Oggi, La maggior parte delle aziende sono basate sui dati. Estos datos se almacenan en una Banca datiUn database è un insieme organizzato di informazioni che consente di archiviare, Gestisci e recupera i dati in modo efficiente. Utilizzato in varie applicazioni, Dai sistemi aziendali alle piattaforme online, I database possono essere relazionali o non relazionali. Una progettazione corretta è fondamentale per ottimizzare le prestazioni e garantire l'integrità delle informazioni, facilitando così il processo decisionale informato in diversi contesti.... Y se gestionan y procesan a través de un sistema de gestión de bases de datos. DBMS rende il nostro lavoro così facile e organizzato. Perciò, è essenziale integrare il linguaggio di programmazione più popolare con lo straordinario strumento DBMS.
SQL è il linguaggio di programmazione più utilizzato quando si lavora con i database ed è compatibile con vari sistemi di database relazionali, come MySQL, SQL Server e Oracle. tuttavia, Lo standard SQL ha alcune funzionalità che vengono implementate in modo diverso nei diversi sistemi di database. Perciò, SQL diventa uno dei concetti più importanti da apprendere in questo campo della scienza dei dati.
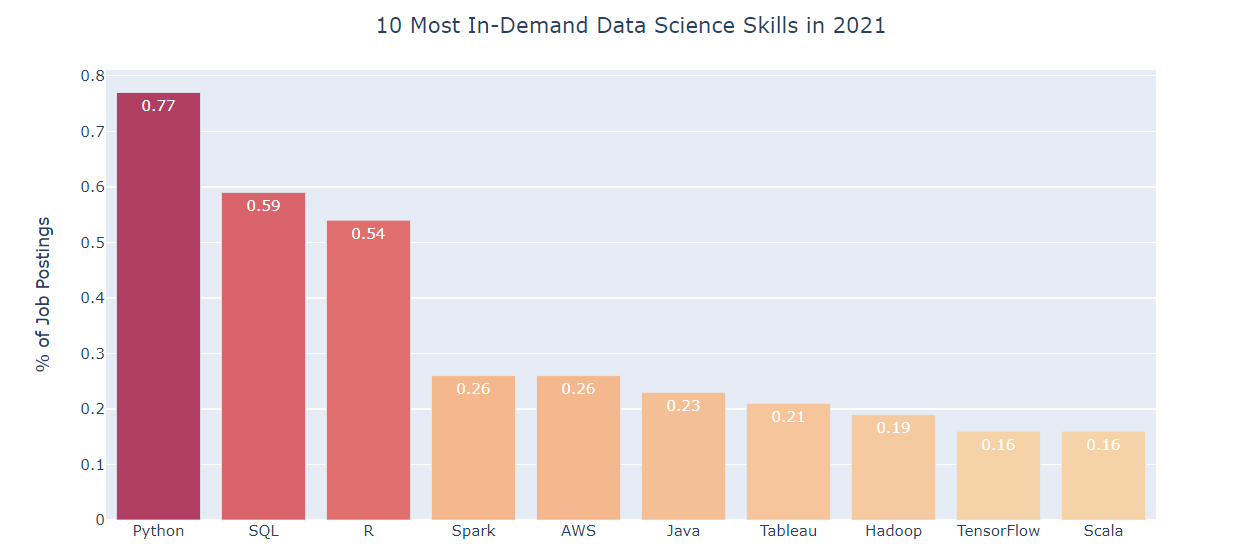
Fonte immagine: KDnuggets
Necessità di SQL nell'analisi scientifica dei dati
SQL (Linguaggio di query strutturato) Utilizzato per eseguire varie operazioni sui dati memorizzati nei database, Come aggiornare i record, Eliminazione di record, Creare e modificare tabelle, Visualizzazioni, eccetera. SQL è anche lo standard per le piattaforme Big Data odierne che utilizzano SQL come API chiave per i loro database relazionali..
La scienza dei dati è lo studio completo dei dati. Per lavorare con i dati, Dobbiamo estrarli dal database. È qui che entra in scena SQL. La gestione dei database relazionali è una parte cruciale della scienza dei dati. Un data scientist può controllare, definire, manipolare, creare ed eseguire query sul database utilizzando i comandi SQL.
Molte industrie moderne hanno dotato la gestione dei dati dei loro prodotti con la tecnologia NoSQL., ma SQL è ancora la scelta ideale per molti strumenti di business intelligence e operazioni d'ufficio.
Molte delle piattaforme di database sono basate su SQL. Ecco perché è diventato uno standard per molti sistemi di database.. Sistemi Big Data moderni come Hadoop, Spark utilizza anche SQL solo per mantenere i sistemi di database relazionali ed elaborare i dati strutturati.
Possiamo dire che:
1. Un data scientist ha bisogno di SQL per gestire i dati strutturati. Come vengono archiviati i dati strutturati nei database relazionali. Perciò, Per eseguire query su questi database, un data scientist deve avere una buona conoscenza dei comandi SQL.
Le piattaforme Big Data come Hadoop e Spark forniscono un'estensione per eseguire query utilizzando comandi SQL per manipolare.
3.SQL è lo strumento standard per sperimentare con i dati creando ambienti di test.
4. Per eseguire operazioni analitiche con dati archiviati in database relazionali come Oracle, Microsoft SQL, MySQL, abbiamo bisogno di SQL.
5. SQL è anche uno strumento essenziale per la preparazione e l'elaborazione dei dati. Perciò, quando si ha a che fare con vari strumenti Big Data, usiamo SQL.
Elementi chiave di SQL per la data science
Di seguito sono riportati gli aspetti chiave di SQL più utili per l'analisi scientifica dei dati. Tutti gli aspiranti data scientist dovrebbero essere consapevoli di queste necessarie competenze e funzionalità SQL..
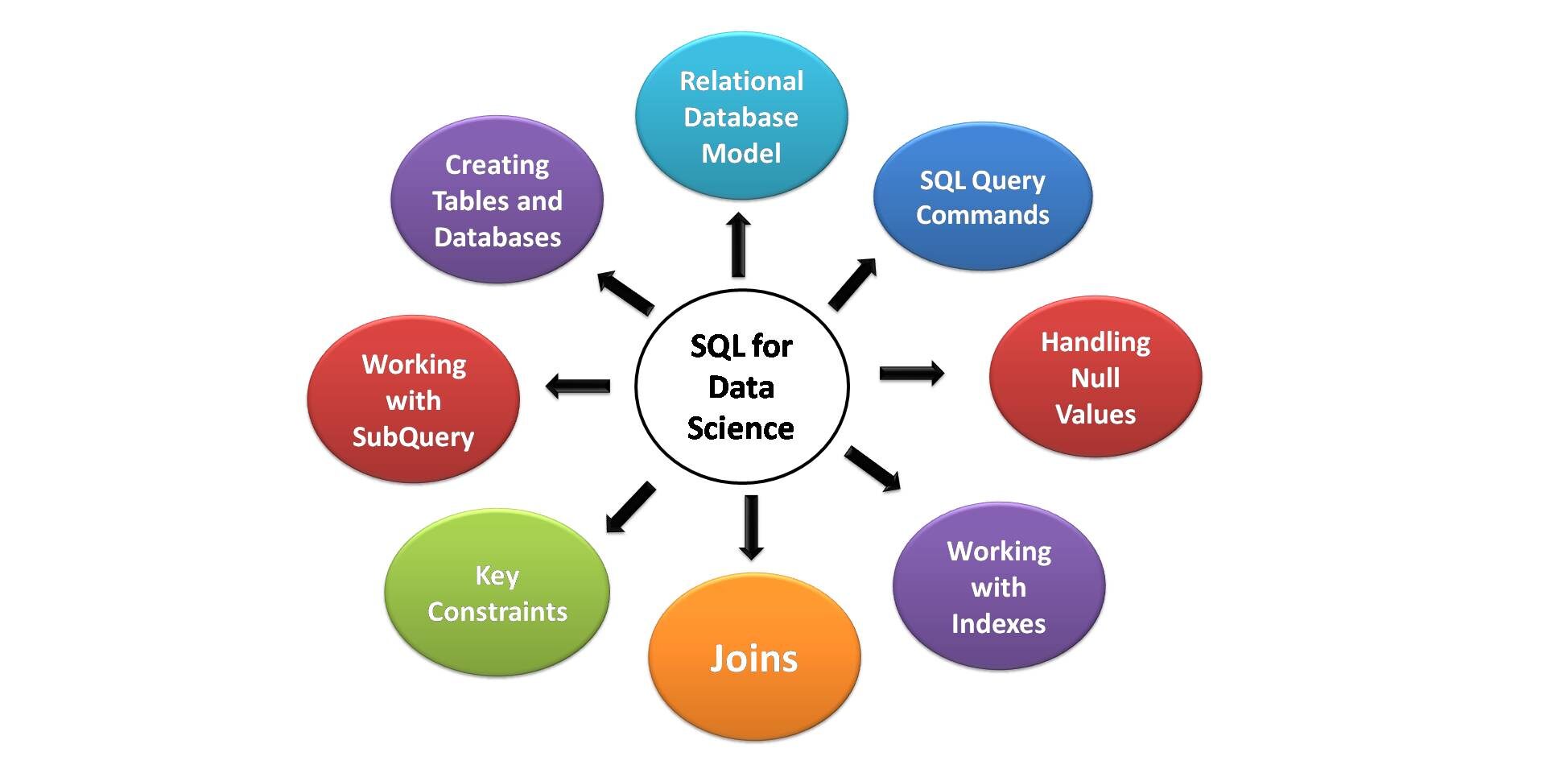
Fonte immagine: Per me
Introduzione a SQL con Python
Come sappiamo tutti, SQL è lo strumento di gestione dei database più utilizzato e Python è il linguaggio di data science più diffuso per la sua flessibilità e l'ampia gamma di librerie. Esistono diversi modi per usare SQL con Python. Python fornisce diverse librerie che sono sviluppate e possono essere utilizzate per questo scopo. SQLite, PostgreSQL, e MySQL sono esempi di queste librerie.
Perché usare SQL con Python
Esistono molti casi d'uso in cui i data scientist vogliono connettere Python a SQL. I data scientist devono connettere un database SQL per archiviare i dati provenienti dall'applicazione web. Aiuta anche a comunicare tra diverse fonti di dati.
Non è necessario passare da un linguaggio di programmazione all'altro per la gestione dei dati. Rende più comodo il lavoro dei data scientist. Saranno in grado di utilizzare le loro competenze Python per manipolare i dati memorizzati in un database SQL. Non hanno bisogno di un file CSV.
MySQL con Python
MySQL è un sistema di gestione di database basato su server. Un server MySQL può avere più database. Un database MySQL è un processo in due fasi per la creazione di un database:
1. Stabilire una connessione a un server MySQL.
2. Eseguire query separate per creare il database ed elaborare i dati.
Iniziamo con MySQL con Python
Primo, creeremo una connessione tra il server MySQL e il DB MySQL. Per questo, definiremo una funzione che stabilirà una connessione al server del database MySQL e restituirà l'oggetto connessione:
!pip install mysql-connector-python
import mysql.connector
from mysql.connector import Error
def create_connection(host_name, user_name, user_password):
connection = None
try:
connessione = mysql.connector.connect(
host=host_name,
utente=user_name,
passwd=user_password
)
Stampa("Connessione a MySQL DB riuscita")
tranne Errore come e:
Stampa(F"L'errore '{e}' si è verificato")
return connection
connection = create_connection("localhost", "radice", "")
Nel codice sopra, Abbiamo definito una funzione create_connection () que acepta los siguientes tres parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto....:
1. nombre_host
2. Nome utente
3. Password utente
Mysql.connector è un modulo SQL Python che contiene un metodo .connect () utilizzato per connettersi a un server di database MySQL. Quando viene stabilita la connessione, L'oggetto connessione creato verrà restituito alla funzione chiamante.
Fino ad ora, La connessione è stata stabilita con successo, Ora creiamo un database.
#we have created a function to create database that contions two parameters #connection and query defcreate_database(connessione,interrogazione): #ora stiamo creando un cursore oggetto per eseguire il cursore delle query SQL=connection.cursor() Tentativo: #La query da eseguire verrà passata in cursor.execute() in forma di stringa cursor.execute(interrogazione) Stampa("Database creato correttamente") tranneErrorecomee: Stampa(F"L'errore '{e}' si è verificato")
#now we are creating a database named example_app create_database_query="CREARE UN DATABASE example_app" create_database(connessione,create_database_query)
#now will create database example_app on database server #and also cretae connection between database and server defcreate_connection(host_name,user_name,user_password,db_name): connessione=Nessuno prova: connessione=mysql.connector.connect( host=host_name, utente=user_name, passwd=user_password, database=db_name ) Stampa("Connessione a MySQL DB riuscita") tranneErrorecomee: Stampa(F"L'errore '{e}' si è verificato") Restituzioneconnessione
#chiamando ilcreate_connection()e si collega alexample_appBanca dati. connessione=create_connection("localhost","radice","","example_app")
SQLite
SQLite è probabilmente il database più semplice che possiamo connettere a un'applicazione Python, in quanto è un modulo integrato, non abbiamo bisogno di installare alcun modulo SQL Python esterno. Per impostazione predefinita, L'installazione di Python contiene una libreria SQL Python denominata SQLITE3 che può essere utilizzata per interagire con un database SQLite.
SQLite è un database serverless. Legge e scrive dati in un file. Ciò significa che non abbiamo nemmeno bisogno di installare ed eseguire un server SQLite per eseguire operazioni di database come MySQL e PostgreSQL!!
Usiamo sqlite3 per connettersi a un database SQLite in Python:
importaresqlite3 dasqlite3importareErrore
defcreate_connection(il percorso): connessione=Nessuno prova: connessione=sqlite3.connect(il percorso) Stampa("Connessione a SQLite DB riuscita")
tranneErrorecomee: Stampa(F"L'errore '{e}' si è verificato") Restituzioneconnessione
Nel codice sopra, Abbiamo importato sqlite3 e la classe di errore del modulo. Quindi definire una funzione chiamata .create_connection () che accetterà il percorso del database SQLite. Quindi .connect () del modulo SQLite3 prenderà il percorso del database SQLite come parametro. Se il database esiste nel percorso specificato in .connect, Verrà stabilita una connessione al database. Altrimenti, Viene creato un nuovo database nel percorso specificato e quindi viene stabilita una connessione.
sqlite3.connect (rotta) restituirà un oggetto connessione, che è stato anche restituito da create_connection (). Questo oggetto connessione verrà utilizzato per eseguire query SQL su un database SQLite. La seguente riga di codice creerà una connessione al database SQLite:
connessione=create_connection("E:example_app.sqlite")
Una volta stabilita la connessione, possiamo vedere che il file di database viene creato nella directory principale e se vogliamo, Possiamo anche cambiare la posizione del file.
In questo articolo, abbiamo discusso di come SQL sia essenziale per la scienza dei dati e anche di come possiamo lavorare con SQL usando Python. Grazie per aver letto. Fammi sapere i tuoi commenti e suggerimenti nella sezione commenti.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





