introduzione
Teoria della stima e Verifica di ipotesi sono i concetti molto importanti di Statistica che sono ampiamente utilizzati da Statistiche, Ingegneri dell'apprendimento automatico, e Scienziati dei dati.
Quindi, in questo post, discuteremo gli stimatori puntuali nella teoria della stima della statistica.
Sommario
1. Stimatori e stimatori
2. Cosa sono gli stimatori di punti??
3. Qual è il campione casuale e la statistica??
4. Due statistiche comuni utilizzate:
- Campione medio
- Varianza di campionamento
5. Proprietà degli stimatori puntuali
- Imparzialità
- Efficiente
- coerente
- Basta
6. Metodi comuni per trovare stime puntuali
7. Stima del punto rispetto alla stima dell'intervallo
Stima e stimatori
Sia X uno variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... casuale con distribuzione FX(X; ?), dove è un parametro sconosciuto. Un campione casuale, X1, X2, –, XNord, di dimensione n presa a X.
Il problema della stima puntuale è la selezione di una statistica, G (X1, X2, —, XNord), che meglio stima il parametro θ.
Una volta osservato, il valore numerico di G (X1, X2, —, XNord) si chiama stima e statistica G (X1, X2, —, XNord) è chiamato stimatoreIl "Estimatore" è uno strumento statistico utilizzato per dedurre le caratteristiche di una popolazione da un campione. Si basa su metodi matematici per fornire stime accurate e affidabili. Esistono diversi tipi di stimatori, come l'imparzialità e la coerenza, che vengono scelti in base al contesto e all'obiettivo dello studio. Il suo corretto utilizzo è essenziale nella ricerca scientifica, Sondaggi e analisi dei dati.....
Cosa sono gli stimatori di punti??
Gli stimatori puntuali sono definiti come le funzioni utilizzate per trovare un valore approssimativo di un parametro di popolazione da campioni casuali della popolazione.. Prendono l'aiuto di dati campione da una popolazione per stabilire una stima puntuale o statistica che serva come la migliore stima di un parametro sconosciuto di una popolazione.
Fonte immagine: Google Immagini
Molto spesso, metodi esistenti per individuare il parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... di grandi popolazioni non sono realistiche.
Come esempio, quando vogliamo trovare l'altezza media delle persone che partecipano a una conferenza, sarà impossibile raccogliere l'altezza esatta di tutte le città congressuali del mondo. Anziché, uno statistico può utilizzare lo stimatore puntuale per stimare il parametro della popolazione.
Campione casuale e statistiche
Campione aleatorio: Un insieme di IID (distribuito in modo indipendente e identico) variabili casuali, X1, X2, X3, —, XNord stabilito nello stesso spazio campionario è detto campione casuale di dimensione n.
Statistiche: Una funzione di un campione casuale è chiamata statistica (se non dipende da alcuna entità sconosciuta)
Come esempio, X1+ X2+ —— + XNord, X12X2+ eX3, X1– XNord
Media campionaria e varianza campionaria
Due statistiche importanti:
Sia x1, X2, X3, —, XNord essere un campione casuale, poi:
La media campionaria è indicata con X, e la varianza campionaria è indicata da S2
Qui x̄ y2 si chiamano parametri di esempio.
I parametri della popolazione sono indicati tramite:
?2 = varianza della popolazione e µ = media della popolazione

Fig. Popolazione e media campionaria
Fonte immagine: Google Immagini

Fig. Popolazione campione e varianza
Fonte immagine: Google Immagini
Caratteristiche della media campionaria:
E (X) = 1 / n (E (Xio)) = 1 / n (nµ) = µ
In cui si (X) = 1 / n2(Var (Xio)) = 1 / n2 (nσ2) =2/Nord
Caratteristiche della varianza campionaria:
S2 = 1 / (n-1) (? (Xio– X )2 ) = 1 / (n-1) (xio2 – 2x̄ Σ xio + nx̄2 ) = 1 / (n-1) (xio2 – nx̄2 )
Ora, Prendiamo le aspettative da entrambe le parti, otteniamo:
E (S2) = 1 / (n-1) (E (Xio2) – n E (X2)) = 1 / (n-1) (? (µ2+ ?2) – n (µ2+ ?2/ n)) = 1 / (n-1) ((n-1) ?2) =2.
Proprietà degli stimatori puntuali
In ogni dato problema di stima, possiamo avere una classe infinita di stimatori appropriati da selezionare. Il problema è trovare uno stimatore G (X1, X2, —, XNord), per un parametro sconosciuto o la sua funzione ? (?), che ha proprietà “simpatico”.
Essenzialmente, vorremmo che lo stimatore g fosse “vicino” a Ψ.
Le seguenti sono le principali proprietà degli stimatori puntuali:
1. imparzialità:
Capiamo prima il significato del termine “Pregiudizio”
La differenza tra il valore atteso dello stimatore e il valore del parametro stimato è chiamata distorsione di uno stimatore puntuale..
Perché, lo stimatore è considerato imparziale quando il valore stimato del parametro e il valore del parametro da stimare sono uguali.
Allo stesso tempo, quanto più il valore atteso di un parametro è vicino al valore del parametro da misurare, più basso è il valore di bias.
Matematicamente,
uno stimatore G (X1, X2, —, XNord) si dice che sia uno stimatore imparziale di se
E (G (X1, X2, —, XNord)) =
In altre parole, in media, ci aspettiamo che g sia vicino al parametro vero θ. Abbiamo visto che se X1, X2, —, XNord essere un campione casuale di una popolazione con media µ e varianza σ2, dopo
E (X) = µ y E (S2) =2
Perché, x̄ e s2 sono stimatori imparziali per µ e σ2
2. Efficiente:
Lo stimatore puntuale più efficiente è quello con la varianza più piccola di tutti gli stimatori imparziali e coerenti.. La varianza rappresenta il livello di dispersione della stima, e la variazione più piccola dovrebbe variare meno da campione a campione.
In genere, l'efficienza dello stimatore dipende dalla distribuzione della popolazione.
Matematicamente,
uno stimatore grammo1(X1, X2, —, XNord) è più efficiente di grammo2(X1, X2, —, XNord), per si
In cui si (G1(X1, X2, —, XNord)) <= Var (g2(X1, X2, —, XNord))
3. coerente:
La coerenza descrive quanto lo stimatore di punti rimane vicino al valore del parametro a misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... Aumento di dimensioni. Per renderlo più coerente e preciso, lo stimatore puntuale ha bisogno di una grande dimensione del campione.
Possiamo anche verificare se uno stimatore puntuale è coerente osservando il rispettivo valore atteso e varianza.
Affinché lo stimatore puntuale sia coerente, il valore atteso dovrebbe spostarsi verso il valore effettivo del parametro.
Matematicamente,
Lascia che g1, G2, G3, ——- essere una sequenza di stimatori, la successione si dice consistente se converge a in probabilità, In altre parole,
P (| GMetro(X1, X2, —, XNord) – ? | >) -> 0 quando m-> ∞
Se X1, X2, —, XNord è una sequenza di variabili casuali IID tale che E (Xio) = µ, più tardi da WLLN (Legge debole dei grandi numeri):
XNord‘—–> µ di probabilità
Dove XNord'È la media di X1, X2, X3, —, XNord
4. Basta:
Sii un campione di X ~ f (X; ?). e Y = g (X1, X2, —, XNord) è una statistica tale che per qualsiasi altra statistica Z = h (X1, X2, —, XNord), la distribuzione condizionata di Z, poiché Y = y non dipende da θ, allora Y si dice statistica sufficiente per.
Metodi comuni per trovare stime puntuali
La procedura di stima puntuale prevede l'utilizzo del valore di una statistica ottenuta con l'ausilio di dati campionari per stabilire la migliore stima del rispettivo parametro sconosciuto della popolazione.. Vari metodi possono essere utilizzati per calcolare o determinare gli stimatori puntuali, e ogni tecnica ha proprietà diverse. Alcuni dei metodi sono i seguenti:
1. Metodo dei momenti (MAMMA)
Inizia considerando tutti i fatti noti su una popolazione e quindi applicando tali fatti a un campione della popolazione.. Primo, deriva equazioni che mettono in relazione i momenti della popolazione con i parametri incogniti.
Il passo successivo è estrarre un campione dalla popolazione che verrà utilizzato per stimare i momenti della popolazione. Le equazioni generate nel primo passaggio vengono quindi risolte con l'aiuto della media campionaria dei momenti della popolazione. Questo fornisce la migliore stima dei parametri della popolazione sconosciuti.
Matematicamente,
Considera un campione X1, X2, X3, —, XNord a partire dal F (X; ?1, ?2, —–, ?Metro) .L'obiettivo è stimare i parametri θ1, ?2, —–, ?Metro.
Lascia che siano i momenti della popolazione (teorici) un1, un2, ——–, unR, che sono funzioni di parametri sconosciuti θ1, ?2, —–, ?Metro.
Uguagliando i momenti del campione e i momenti della popolazione, otteniamo gli stimatori di1, ?2, —–, ?Metro.
2. Stimatore di massima verosimiglianza (MLE)
Questo metodo per trovare stimatori puntuali tenta di trovare i parametri sconosciuti che massimizzano la funzione di verosimiglianza. Prendi un modello noto e usa i valori per confrontare i set di dati e trovare la migliore corrispondenza per i dati.
Matematicamente,
Considera un campione X1, X2, X3, —, XNord spento (X; ?). L'obiettivo è stimare i parametri θ (scalare o vettoriale).
La funzione di verosimiglianza è impostata come:
l (?; X1, X2, —, XNord) = f (X1, X2, —, XNord; ?)
Un MLE di θ è il valore θ '(una funzione di esempio) che massimizza la funzione di verosimiglianza
Se L è una funzione differenziabile di, quindi la successiva equazione di verosimiglianza viene utilizzata per ottenere la MLE ('):
D / dθ (ln (l (?; X1, X2, —, XNord) = 0
Se è un vettore, allora si considera che le derivate parziali ottengano le equazioni di verosimiglianza.
Stima del punto rispetto alla stima dell'intervallo
Semplicemente, ci sono due tipi principali di stimatori in statistica:
- Stimatori di punti
- Stimatori di intervallo
La stima puntuale è l'opposto della stima per intervallo.
La stima del punto genera un valore univoco, mentre la stima dell'intervallo genera un intervallo di valori.
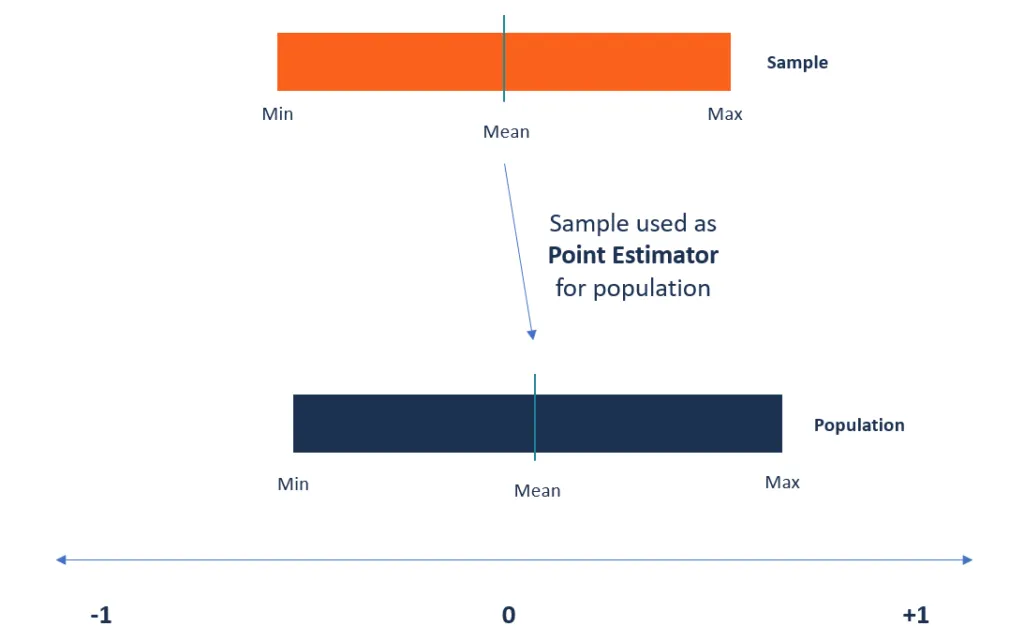
Uno stimatore puntuale è una statistica utilizzata per stimare il valore di un parametro sconosciuto in una popolazione. Utilizza i dati del campione della popolazione durante il calcolo di una singola statistica che sarà considerata la migliore stima per il parametro sconosciuto della popolazione.

Fonte immagine: Google Immagini
al contrario, la stima dell'intervallo prende dati campione per stabilire l'intervallo di possibili valori di un parametro sconosciuto in una popolazione. L'intervallo del parametro è selezionato per essere compreso tra a 95% o più probabilmente, conosciuto anche come intervallo di confidenza. L'intervallo di confidenza descrive quanto sia affidabile una stima e viene calcolato dai dati osservati. I punti finali degli intervalli sono noti come superiore e limiti di confidenza inferiori.
Note finali
Grazie per aver letto!
Spero che il post ti sia piaciuto e che abbia aumentato la tua conoscenza della teoria della stima.
Per favore sentiti libero di contattarmi su E-mail
Tutto ciò che non è stato menzionato o vuoi condividere i tuoi pensieri? Sentiti libero di commentare qui sotto e ti ricontatterò.
Circa l'autore
Aashi Goyal
A quest'ora, Sto perseguendo il mio Bachelor of Technology (B.Tech) in Ingegneria Elettronica e delle Comunicazioni Universidad Guru Jambheshwar (GJU), Hisar. Sono molto entusiasta delle statistiche, apprendimento automatico e apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute....
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





