Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Ogni volta che creiamo un modello di apprendimento automatico, lo alimentiamo con i dati iniziali per addestrare il modello. E poi inseriamo dati sconosciuti (dati di test) per capire come si comporta il modello e generalizzare su dati invisibili. Se il modello funziona bene su dati invisibili, è coerente e può prevedere con buona precisione su un'ampia gamma di dati di input; quindi questo modello è stabile.
Ma non è sempre così!! I modelli di apprendimento automatico non sono sempre stabili e dobbiamo valutare la stabilità del modello di apprendimento automatico. È qui che entra in gioco la convalida incrociata..
“In parole povere, la convalida incrociata è una tecnica utilizzata per valutare l'efficacia dei nostri modelli di apprendimento automatico su dati non visti”
Secondo Wikipedia, la convalida incrociata è il processo di valutazione di come i risultati di un'analisi statistica si generalizzeranno a un set di dati indipendente.
Esistono molti modi per eseguire la convalida incrociata e ne impareremo a conoscere 4 metodi in questo articolo.
Per prima cosa capiamo la necessità della convalida incrociata!!
Perché abbiamo bisogno della convalida incrociata??

Supponiamo di creare un modello di apprendimento automatico per risolvere un problema e di aver addestrato il modello su un determinato set di dati. Cuando verifica la precisión del modelo en los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina...., è vicino a 95%. Questo significa che il tuo modello è stato addestrato molto bene ed è il miglior modello grazie all'elevata precisione??
No, Non è! Perché il tuo modello è addestrato sui dati forniti, conosce bene i dati, cattura anche le più piccole variazioni (rumore) ed è stato generalizzato molto bene sui dati forniti. Se esponi il modello a dati completamente nuovi e invisibili, potrebbe non prevedere in modo accurato e potrebbe non generalizzare su nuovi dati. Questo problema si chiama overfitting..
Qualche volta, il modello non si allena bene nel training set perché non riesce a trovare schemi. In questo caso, non funzionerebbe bene neanche sul banco di prova. Questo problema si chiama Insufficient Fit.
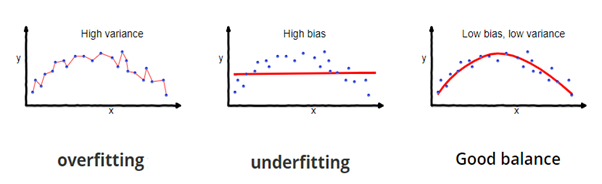
Fonte immagine: fireblazeaischool.in
Per superare i problemi di sovradattamento, usiamo una tecnica chiamata Cross Validation.
Convalida incrociata è una tecnica di ricampionamento con l'idea fondamentale di dividere il set di dati in 2 parti: dati di allenamento e dati di test. I dati di addestramento vengono utilizzati per addestrare il modello e i dati di test invisibili vengono utilizzati per la previsione. Se il modello si comporta bene sui dati del test e offre una buona precisione, significa che il modello non ha adattato eccessivamente i dati di addestramento e può essere utilizzato per la previsione.
Immergiamoci e impariamo alcune delle tecniche di valutazione del modello.
1. Metodo di attesa
Questo è il metodo di valutazione più semplice ed è ampiamente utilizzato nei progetti di apprendimento automatico.. Qui, il set di dati completo (popolazione) è diviso in 2 imposta: set di treni e set di prova. I dati possono essere suddivisi in 70-30 oh 60-40, 75-25 oh 80-20, o anche 50-50 a seconda del caso d'uso. Come regola generale, la proporzione dei dati di allenamento deve essere maggiore dei dati del test.
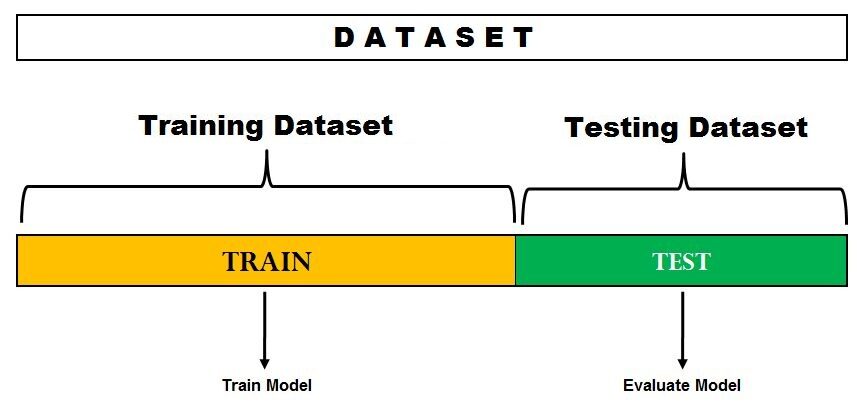
Fonte immagine: Dati Veda
La divisione dei dati avviene in modo casuale e non possiamo essere sicuri di quali dati finiscano sul treno e nel magazzino di prova durante la divisione, a meno che non specifichiamo random_state. Questo può portare a una varianza estremamente elevata e ogni volta che la divisione cambia, anche la precisione cambierà.
Questo metodo ha alcuni inconvenienti:
- Nel metodo Hold out, i tassi di errore del test sono molto variabili (alta varianza) e dipende totalmente da quali osservazioni finiscono nel training set e nel test set.
- Solo una parte dei dati viene utilizzata per addestrare il modello (alta distorsione) che non è una buona idea quando i dati non sono grandi e questo porterà a una sopravvalutazione dell'errore di test.
Uno dei principali vantaggi di questo metodo è che è computazionalmente poco costoso rispetto ad altre tecniche di convalida incrociata..
Implementazione rapida del metodo Hold Out in Python
da sklearn.model_selection import train_test_split
X = [10,20,30,40,50,60,70,80,90,100]
treno, test = train_test_split (X, test_size = 0.3, stato_casuale = 1)
Stampa (“Treno:”, X_treno, “Test:”, X_test)
Produzione
Treno: [50, 10, 40, 20, 80, 90, 60] Test: [30, 100, 70]
Qui, Stato casuale è il seme utilizzato per la riproducibilità.
2. Lascia uno fuori dalla convalida incrociata
In questo metodo, dividiamo i dati in test e train set, ma con una svolta. Invece di dividere i dati in 2 sottoinsiemi, selezioniamo una singola osservazione come dati di test, e tutto il resto viene etichettato come dati di addestramento e il modello viene addestrato. Ora la seconda osservazione viene selezionata come dati di test e il modello viene addestrato con i dati rimanenti.
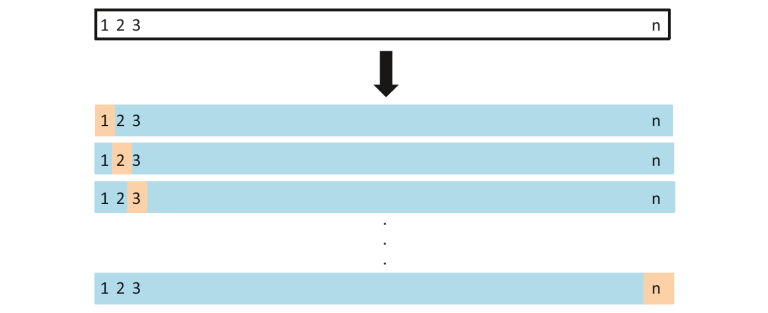
Fonte immagine: ISLR
Questo processo continua' n’ volte e la media di tutte queste iterazioni viene calcolata e stimata come l'errore del test set.
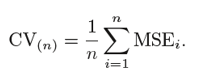
Quando si tratta di stime degli errori di test, LOOCV fornisce stime imparziali (basso pregiudizio). Ma il pregiudizio non è l'unica preoccupazione nei problemi di stima. Dovremmo anche considerare la varianza.
LOOCV ha un alta varianza perché stiamo mediando l'output di n-modelli che si adattano a un insieme di osservazioni quasi identico, e i loro risultati sono correlati in modo molto positivo tra loro.
E puoi vedere chiaramente che questo è computazionalmente costoso poiché il modello viene eseguito' n’ volte per testare ogni osservazione sui dati. Il nostro prossimo metodo affronterà questo problema e ci darà un buon equilibrio tra bias e varianza..
Implementazione rapida di Leave One Out Cross Validation in Python
da sklearn.model_selection import LeaveOneOut
X = [10,20,30,40,50,60,70,80,90,100]
l = LasciaUnoFuori()
per il treno, prova in l.split(X):
Stampa("%s %s"% (treno,test))
Produzione
[1 2 3 4 5 6 7 8 9] [0] [0 2 3 4 5 6 7 8 9] [1] [0 1 3 4 5 6 7 8 9] [2] [0 1 2 4 5 6 7 8 9] [3] [0 1 2 3 5 6 7 8 9] [4] [0 1 2 3 4 6 7 8 9] [5] [0 1 2 3 4 5 7 8 9] [6] [0 1 2 3 4 5 6 8 9] [7] [0 1 2 3 4 5 6 7 9] [8] [0 1 2 3 4 5 6 7 8] [9]
Questo output mostra chiaramente come LOOCV tiene da parte un'osservazione mentre i dati del test e tutte le altre osservazioni vanno ai dati del treno.
3. Convalida incrociata di K-Fold
In questa tecnica di ricampionamento, tutti i dati sono divisi in k insiemi di dimensioni quasi uguali. Il primo set viene selezionato come set di prova e il modello viene addestrato sui restanti set k-1. Il tasso di errore del test viene calcolato dopo aver adattato il modello ai dati del test.
Nella seconda iterazione, il secondo set viene selezionato come set di test e i restanti set k-1 vengono utilizzati per addestrare i dati e viene calcolato l'errore. Questo processo continua per tutti i k insiemi.
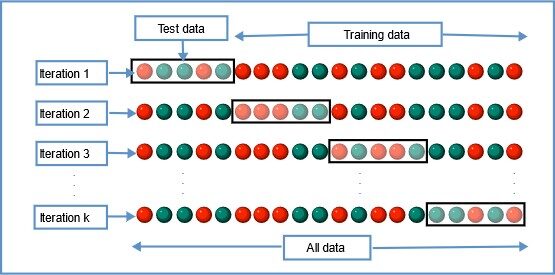
Fonte immagine: Wikipedia
La media degli errori di tutte le iterazioni è calcolata come stima dell'errore del test CV.
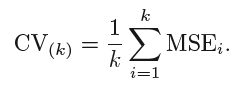
Un CV piegato a K, il numero di pieghe k è inferiore al numero di osservazioni nei dati (K <n) e stiamo calcolando la media dei risultati di k modelli adattati che sono in qualche modo meno correlati tra loro perché la sovrapposizione tra i set di allenamento in ciascun modello è minore. Questo porta a varianza bassa poi LOOCV.
La parte migliore di questo metodo è che ogni punto dati è nel test set esattamente una volta e fa parte del training set k-1 volte.. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que aumenta el número de pliegues k, diminuisce anche la varianza (varianza bassa). Questo metodo porta a bias intermedio perché ogni set di allenamento contiene meno osservazioni (k-1) n / k rispetto al metodo Leave One Out ma più del metodo Hold Out.
Generalmente, K volte la convalida incrociata viene eseguita utilizzando k = 5 o k = 10, poiché è stato dimostrato empiricamente che questi valori producono stime di errori di test che non sono né alta distorsione né alta varianza.
Il principale svantaggio di questo metodo è che il modello deve essere eseguito da zero k volte ed è computazionalmente costoso rispetto al metodo Hold Out., ma meglio del metodo Leave One Out.
Semplice implementazione di K-Fold Cross Validation in Python
da sklearn.model_selection import KFold
X = ["un",'B','C','D','e','F']
kf = KFold(n_split=3, shuffle=Falso, random_state=Nessuno)
per il treno, prova in kf.split(X):
Stampa("Dati del treno",treno,"Dati di test",test)
Produzione
Treno: [2 3 4 5] Test: [0 1] Treno: [0 1 4 5] Test: [2 3] Treno: [0 1 2 3] Test: [4 5]
4. Convalida incrociata stratificata di K-Fold
Questa è una leggera variazione di K-Fold Cross Validation, cosa usi "Campionamento stratificato"’ invece di “campionamento Casuale”.
Capiamo velocemente cos'è il campionamento stratificato e come si differenzia dal campionamento casuale.
Supponiamo che i tuoi dati contengano recensioni di un prodotto cosmetico utilizzato dalla popolazione maschile e femminile. Quando eseguiamo il campionamento casuale per dividere i dati in serie di test e treni, esiste la possibilità che la maggior parte dei dati che rappresentano gli uomini non siano rappresentati nei dati di allenamento, ma potrebbero finire nei dati del test. Quando addestriamo il modello con dati di addestramento di esempio che non sono una rappresentazione corretta della popolazione reale, il modello non prevederà i dati del test con una buona precisione.
È qui che viene in soccorso il campionamento stratificato.. Qui i dati sono suddivisi in modo da rappresentare tutte le classi della popolazione.
Consideriamo l'esempio sopra, chi ha una recensione di prodotti cosmetici da 1000 clienti, di cui il 60% Sono donne e lui 40% loro sono uomini. Voglio dividere i dati in test e addestrare i dati in proporzione (80:20). Il 80% del 1000 i clienti saranno 800 che sarà scelto in modo tale che ci sia 480 recensioni associate alla popolazione femminile e 320 in rappresentanza della popolazione maschile. Allo stesso modo, il 20% a partire dal 1000 i clienti saranno scelti per i dati di prova (con la stessa rappresentazione femminile e maschile).
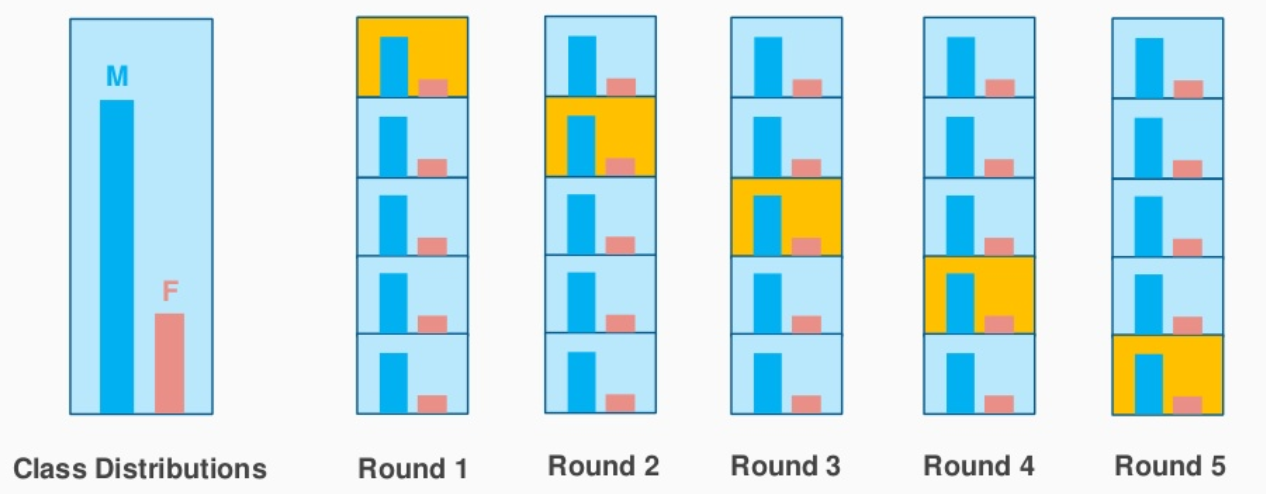
Fonte immagine: stackexchange.com
Questo è esattamente ciò che fa il K-Fold Stratified CV e creerà K-Fold preservando la percentuale del campione per ogni classe. Questo risolve il problema del campionamento casuale associato ai metodi Hold out e K-Fold..
Implementazione rapida di K-Fold Layered Cross Validation in Python
da sklearn.model_selection import StratifiedKFold
X = np.array([[1,2],[3,4],[5,6],[7,8],[9,10],[11,12]])
y = np.array([0,0,1,0,1,1])
skf = StratificatoKFold(n_splits=3,random_state=Nessuno,shuffle=Falso)
per train_index,test_index in skf.split(X,e):
Stampa("Treno:",train_index,'Test:',indice_test)
X_treno,X_test = X[train_index], X[indice_test]
y_train,y_test = y[train_index], e[indice_test]
Produzione
Treno: [1 3 4 5] Test: [0 2] Treno: [0 2 3 5] Test: [1 4] Treno: [0 1 2 4] Test: [3 5]
Il risultato mostra chiaramente la suddivisione stratificata operata per classi ‘0’ e '1’ in e'.
Pregiudizio – Compensazione della varianza
Quando consideriamo le stime del tasso di errore del test, La convalida incrociata di K-Fold fornisce stime più accurate rispetto a una convalida incrociata a parte. Mentre il metodo Hold One Out CV generalmente porta a sopravvalutazioni del tasso di errore del test, perché in questo approccio, solo una parte dei dati viene utilizzata per addestrare il modello di apprendimento automatico.
Quando si tratta di pregiudizi, il metodo Leave One Out fornisce stime imparziali perché ogni training set contiene n-1 osservazioni (che sono praticamente tutti i dati). K-Fold CV porta a un livello intermedio di distorsione a seconda del numero di k-fold rispetto a LOOCV, ma è molto meno rispetto al metodo Hold Out.
Completare, la tecnica di convalida incrociata che scegliamo dipende fortemente dal caso d'uso e dall'equilibrio tra distorsione e varianza.
Se hai letto questo articolo finora, ecco un bonus veloce per te. ?
sklearn.model_selection ha un metodo cross_val_score che semplifica il processo di convalida incrociata. Invece di scorrere tutti i dati utilizzando la funzione 'divide', possiamo usare cross_val_score e controllare il punteggio di precisione del metodo di convalida incrociata scelto
Puoi controllare il mio Github per implementazione Python di diversi metodi di convalida incrociata nel Fatti sul cancro al seno in terapia intensiva Kaggle.
Di seguito sono riportati alcuni dei miei articoli sull'apprendimento automatico.
Inteligencia artificial Vs Aprendizaje automático Vs Apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute...: Qual è esattamente la differenza tra queste parole d'ordine??
Una guida completa all'analisi dei dati utilizzando Pandas
Se vuoi condividere i tuoi pensieri, puoi connetterti con me su LinkedIn.
Buon apprendimento!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





