Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Visualizzazione dati
Las técnicas de visualización de datos implican la generación de representaciones gráficas o pictóricas. di dati, formulario que lo lleva a comprender la información de un conjunto de datos dado. Esta técnica de visualización tiene como objetivo identificar los patrones, tendenze, correlaciones y valores atípicos de conjuntos de datos.
Vantaggi della visualizzazione dei dati
- Patrones en las operaciones comerciales: Las técnicas de visualización de datos nos ayudan a determinar los patrones de las operaciones comerciales. Entendiendo el planteamiento del problema e identificando las soluciones en términos de patrones y aplicados para eliminar uno o más de los problemas inherentes.
- Identificar las tendencias comerciales y relacionarse con los datos: Sono Las técnicas nos ayudan a identificar las tendencias del mercado mediante la recopilación de datos sobre las actividades comerciales diarias y la preparación de informes de tendencias, lo que ayuda a rastrear la forma en que la empresa influye en el mercado. Para que podamos entender a la competencia y a los clientes. Certamente, esto ayuda a tener una perspectiva a largo plazo.
- Narración y toma de decisiones: El conocimiento de la narración de historias a partir de los datos disponibles es una de las habilidades de nicho para la comunicación empresarial, específicamente para el dominio de la ciencia de datos, que está desempeñando un papel vital. Utilizando la mejor visualización este rol se puede potenciar mucho mejor y alcanzando los objetivos de los problemas empresariales.
- Comprender la información empresarial actual y establecer los objetivos: Las empresas pueden comprender la información de los KPI comerciales, encontrar objetivos tangibles y planificaciones de estrategia comercial, por lo que podrían optimizar los datos para planes de estrategia comercial para actividades en curso.
- Análisis operativo y de rendimiento:
- Incrementar la productividad de la unidad de fabricación: Con la ayuda de técnicas de visualización, la claridad de los KPI que representan las tendencias de la productividad de la unidad de fabricación y la orientación fueron para mejorar la productividad de la planta.
Visualización de datos en ciencia de datos
Las técnicas de visualización de datos son la parte más importante de la ciencia de datos, no habrá ninguna duda al respecto. E incluso en el espacio de análisis de datos, la visualización de datos desempeña un papel importante. Discutiremos esto en detalle con la ayuda de los paquetes de Python y cómo ayuda durante el flujo del proceso de Data Science. Este es un tema muy interesante para todos los científicos y analistas de datos.
io. Grafico a linee
Grafico a linee es una visualización de datos simple en Python, que está disponible en Matplotlib.
Grafici a linee se utilizan para representar la relación entre dos datos X e Y en el eje respectivo. Veamos algunas muestras
Campione #1 # importing the required libraries import matplotlib.pyplot as plt import numpy as np #simple array x = np.array([1, 2, 3, 4]) #genearting y values y = x*2 plt.plot(X, e) plt.mostra() Campione #2 x = np.array([1, 2, 3, 4]) y = np.array([2, 4, 6, 8]) plt.trama(X, e) plt.xlabel("Time in Hrs") plt.ylabel("Distance in Km") plt.titolo("Time Vs Distance") plt.mostra()
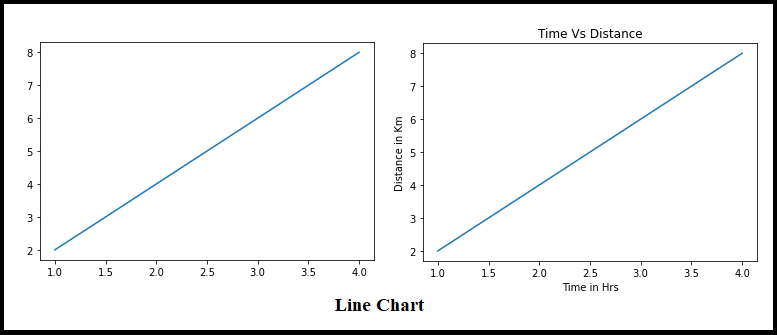
Line Chart siempre una relación lineal entre los ejes X e Y, lo observamos en la imagen de arriba.
II.Histograma
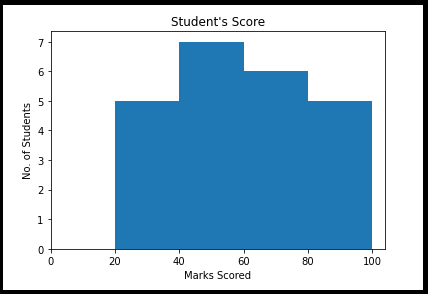
El histograma es la representación gráfica de un conjunto de distribución de datos numéricos. Es una especie de gráfico de barras con el eje X y el eje Y representa los rangos y la frecuencia de los intervalos, rispettivamente. Cómo leer o representar esta tabla.
Digamos el ejemplo, conjunto de marcas de los estudiantes en los rangos y frecuencias que se muestran a continuación. Aquí podríamos entender exactamente el rango y la frecuencia de corte.
from matplotlib import pyplot as plt import numpy as np fig,ax = plt.sottotrame(1,1) a = np.array([25,42,48,55,60,62,67,70,30,38,44,50,54,58,75,78,85,88,89,28,35,90,95]) ax.hist(un, bidoni = [20,40,60,80,100]) ax.set_title("Student's Score") ax.set_xticks([0,20,40,60,80,100]) ax.set_xlabel('Marks Scored') ax.set_ylabel('No. of Students') plt.mostra()
Características del histograma
- il Istogramma se utiliza para obtener cualquier observación inusual en el conjunto de datos de dar.
- Medido en una escala de intervalo de valores numéricos dados con varios contenedores de datos.
- El eje Y representa el número de% de ocurrencias en los datos
- El eje X representa distribuciones de datos.
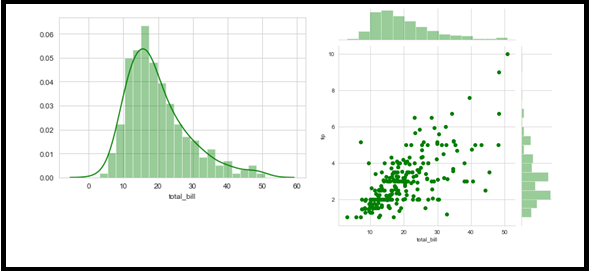
Mostrare – Esto es similar al histograma en el gráfico, pero con características adicionales. Y trayendo Estimación de la densidad del grano (DOVE).
Trama comune – Una combinación de dispersión e histograma.
import seaborn as sns
import matplotlib.pyplot as plt
from warnings import filterwarnings
df = sns.load_dataset('suggerimenti')
sns.distplot(df['fattura_totale'], kde = Vero, colore="verde", bidoni = 20)
sns.jointplot(x ='total_bill',colore="verde", y ='tip', dati = df)
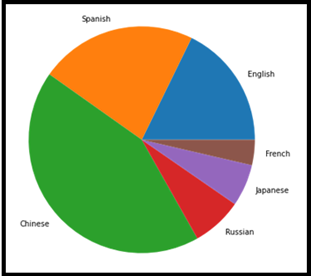
III.Gráfico de pastel
Este es un gráfico muy familiar y un gráfico estadístico de representación en forma de circular a partir de una serie de datos. Esto se usa comúnmente en presentaciones comerciales para representar pedidos, saldi, ganancias, rischi, eccetera. Consiste en porciones de datos que forman parte de la recopilación del mismo conjunto y diferenciación por caracteres. Cada una de las porciones de pastel se llama cuña con valores de diferentes tamaños.
Esta tabla se usa ampliamente para representar la colección de composición.. Perfecto para el tipo de datos categóricos.
from matplotlib import pyplot as plt import numpy as np Language = ['Inglese', 'Spanish', 'Chinese', 'Russian', 'Japanese', 'French'] dati = [379, 480, 918, 154, 128, 77.2] # Creating plot fig = plt.figure(dimensione del fico =(10, 7)) plt.pie(dati, labels = Language) # show plot plt.show()
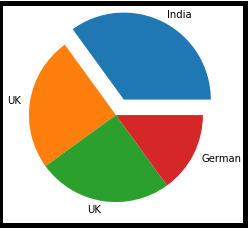
import matplotlib.pyplot as plt import numpy as np y = np.array([35, 25, 25, 15]) mylabels = ["India", "REGNO UNITO", "REGNO UNITO", "German"] myexplode = [0.2, 0, 0, 0] plt.pie(e, labels = mylabels, explode = myexplode) plt.mostra()
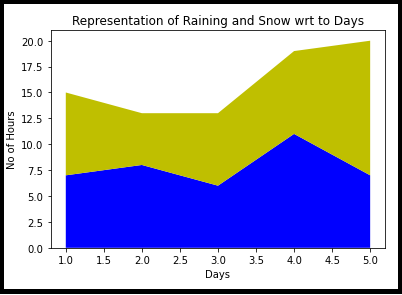
IV. Parcela de área
Esto es muy similar a un gráfico de líneas con cercas rodeadas por una línea de límite de diferentes colores. Representación simple de la evolución de una variable numérica.
import matplotlib.pyplot as plt days = [1, 2, 3, 4, 5] raining = [7, 8, 6, 11, 7] snow = [8, 5, 7, 8, 13] plt.stackplot(giorni, raining, neve,colori =['B', 'e']) plt.xlabel('Days') plt.ylabel('No of Hours') plt.titolo('Representation of Raining and Snow wrt to Days') plt.mostra()
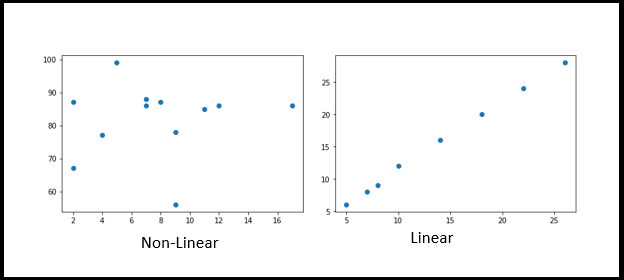
V. Gráficos de dispersión
Los diagramas de dispersión se utilizan para trazar puntos de datos en ambos ejes (horizontal y vertical) y representan cómo cada eje se correlaciona entre sí. Principalmente en la implementación de Data Science / Machine Learning y antes del proceso de EDA, generalmente debemos analizar qué tan dependientes e independientes se alinean. Podría ser positivo o negativo o, A volte, estar disperso en el gráfico.
import matplotlib.pyplot as plt
x = [5,7,8,7,2,17,2,9,4,11,12,9]
y = [99,86,87,88,67,86,87,78,77,85,86,56]
plt.scatter(X, e)
plt.mostra()
import matplotlib.pyplot as plt
x = [5,7,8,10,14,18,22,26]
y = [6,8,9,12,16,20,24,28]
plt.scatter(X, e)
plt.mostra()
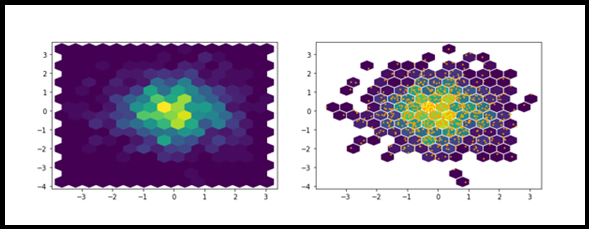
VI. Parcelas de hexbins
El objetivo de Hexbins se utiliza para agrupar los dos conjuntos de valores numéricos. Hexbins ayuda a mejorar la visualización de los diagramas de dispersión. Porque para un conjunto de datos más grande, un diagrama de dispersión crea un puñado de puntos confusos. Podemos mejorar esto con Hexbins. Proporciona dos modos de representación: 1. Lista de coordenadas 2. Objeto geoespacial.
import numpy as np import matplotlib.pyplot as plt x = np.random.normal(taglia=(1, 1000)) y = np.random.normal(taglia=(1, 1000)) plt.hexbin(X, e, gridsize=15)
plt.hexbin(X,e,gridsize=15, mincnt=1, edgecolors="bianco") plt.scatter(X,e, s=2, c="arancia") plt.mostra()
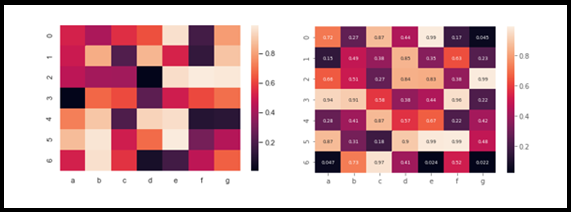
VII. Mappa di calore
UN mappa di calore es una de mis técnicas de visualización favoritas entre los otros gráficos. fondamentalmente, un conjunto de correlaciones variables está representado por varios tonos del mismo color. Generalmente, los tonos más oscuros del gráfico representan los valores de correlación más altos que el tono más claro. este mapa ayudaría a los científicos de datos a descubrir cómo la variable objetivo se correlaciona con otras variables dependientes en el conjunto de datos dado. Las variables menos correlacionadas se pueden eliminar para un análisis más detallado, podríamos decir que esto nos ayuda durante el proceso de selección de características. Luego agrupándolos en X, Y como nuestro objetivo y seguido de prueba y división del tren.
import seaborn as sn import numpy as np import pandas as pd df=pd.DataFrame(np.random.random((7,7)),colonne=['un','B','C','D','e','F','G']) sn.heatmap(df)
sn.heatmap(df,annot=Vero,annot_kws={'dimensione':7})
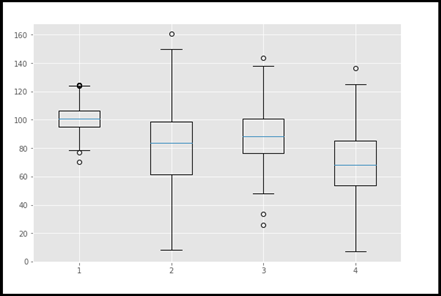
VIII. Trama scatola
Un diagrama de caja es un tipo de gráfico que se utiliza a menudo en el ciclo de vida de la ciencia de datos, especialmente durante el análisis de datos explicativos (EDA). Que representa la distribución de datos en forma de cuartiles o percentiles. Q1 representa el primer cuartil (percentile 25), Q2 es el segundo cuartil (percentile 50 / mediano), Q3 representa el tercer cuartil (Q3) y Q4 representa el cuarto cuartil o el valor más grande.
Usando esta gráfica, pudimos identificar los valores atípicos muy rápida y fácilmente. Esta es una trama muy efectiva entre todas las tramas. Perciò, después de eliminar los valores atípicos, el conjunto de datos debe someterse a algún tipo de prueba estadística y ajustarse para un análisis más detallado.
#import matplotlib.pyplot as plt np.random.seed(10) one=np.random.normal(100,10,200) two=np.random.normal(80, 30, 200) three=np.random.normal(90, 20, 200) four=np.random.normal(70, 25, 200) to_plot=[one,two,three,four] fig=plt.figure(1,figsize=(9,6)) ax=fig.add_subplot() bp=ax.boxplot(to_plot) fig.savefig('boxplot.png',bbox_inches="tight")
IX. Parcela
Una parcela es otra gráfica importante en el ciclo de vida de la ciencia de datos durante el proceso de EDA, para analizar cómo se relacionan las características entre sí, en forma de representación gráfica en miniatura basada en cuadrículas a lo largo de los ejes X e Y, correlacionados positivamente o correlacionados negativamente. . Quindi, ovviamente, podríamos eliminar los correlacionados negativamente, considerando los pares corregidos positivamente y movernos para un análisis más detallado. Esto es muy similar al Mapa de calor, pero aquí pudimos ver la relación a simple vista. Eso es especial aquí. Espero que puedas pagar esto. Ancora, esto es lo mejor para realizar el proceso de selección de funciones.
import pandas as pd import seaborn as sb from matplotlib import pyplot as plt df = sb.load_dataset('iris') sb.set_style("Zecche") sb.pairplot(df,tonalità="specie",diag_kind = "kde",kind = "disperdere",tavolozza = "husl") plt.mostra()
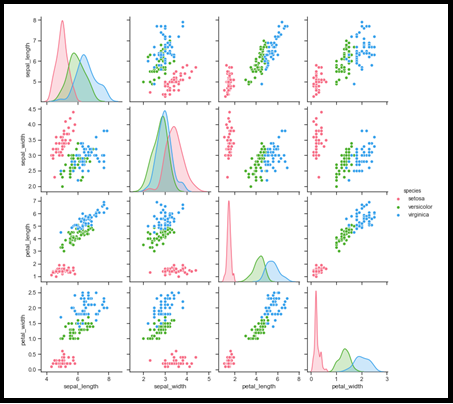
El gráfico de líneas es siempre una relación lineal entre los ejes X e Y, observamos que la imagen de arriba
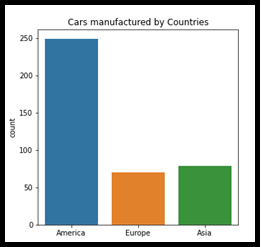
X. Grafico a barre
Un gráfico de barras o gráfico de barras es generalmente un gráfico muy familiar para presentar datos categóricos con barras rectangulares. Puede trazarse de forma horizontal o vertical. este gráfico representaría el impacto de la categoría del individuo en el conjunto de datos dado. Primero del primer vistazo. En el gráfico siguiente, “América” tiene mucho más impacto que “Europa” y “Asia”. Esto derivaría en alguna observación sobre el conjunto de datos y se centraría en el planteamiento del problema.
Fig, ax = plt.sottotrame(dimensione del fico = (5, 5)) sns.countplot(x = df_cars.origin.values, data=df_cars) etichette = [item.get_text() for item in ax.get_xticklabels()] etichette[0] = 'America' labels[1] = 'Europe' labels[2] = 'Asia' ax.set_xticklabels(etichette) ax.set_title("Cars manufactured by Countries") plt.mostra()
Univariante – Análisis bivariado y multivariado
Análisis de variantes en el proceso de Data Science, podría ser Univariante (oh) Bi-variable (oh) Multivariado.
- Univariante: solo una variable a la vez.
- Bi-variable: compara dos variables.
- Multivariante: comparar más de dos variables
Puede muy bien hacer referencia a los modelos anteriores con los Gráficos / Visualización que hemos discutido desde el principio del artículo. Simplemente revísalo de nuevo. Certamente, puede comprender la importancia de estas técnicas de visualización de datos.
Gracias por leer este artículo y creo que es útil para ti. y puede darse cuenta de esto cuando opte por la implementación de la solución Data Science antes de la selección del modelo. Incluso después de que toda la evaluación del modelo y las predicciones sean el resultado de comparaciones. Como se muestra a continuación en los cuadros de referencia.
Grazie! Un'altra volta. Nos pondremos en contacto contigo con otro tema interesante. Hasta entonces ¡adiós! ¡Chau! – Shanthababu
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





