Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
L'imputazione è una tecnica utilizzata per sostituire i dati mancanti con un valore surrogato per conservare la maggior parte dei dati / informazioni sul set di dati. Estas técnicas se utilizan porque eliminar los datos del conjunto de datos cada vez no es factible y puede conducir a una reducción en el tamaño del conjunto de datos en gran misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica...., che non solo solleva preoccupazioni sull'inclinazione del set di dati, porta anche a un'analisi errata.
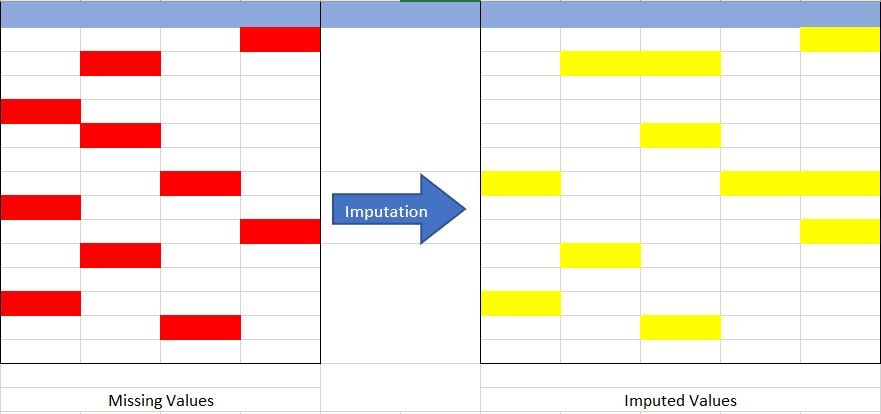
Fonte: creato dall'autore
Non sono sicuro di quali dati mancano? Come succede?? E il tuo tipo? Dai un'occhiata QUI per saperne di più.
Comprendiamo il concetto di imputazione dalla Fig {Fig 1} anteriore. Nella foto sopra, Ho cercato di rappresentare i dati mancanti nella tabella a sinistra (segnato in rosso) e utilizzando tecniche di imputazione abbiamo completato il set di dati mancante nella tabella a destra (segnato in giallo), senza ridurre la dimensione effettiva del set di dati. Se ci rendiamo conto qui, abbiamo aumentato la dimensione della colonna, cosa è possibile nell'imputazione (aggiungendo l'imputazione di categoria “La mancanza”).
Perché l'imputazione è importante??
Quindi, dopo aver conosciuto la definizione di imputazione, la prossima domanda è perché dovremmo usarlo e cosa succederebbe se non lo uso?
Eccoci con le risposte alle domande precedenti.
Usiamo l'imputazione perché i dati mancanti possono causare i seguenti problemi: –
- Incompatibile con la maggior parte delle librerie Python utilizzate in Machine Learning: – sì, hai letto bene. Quando si utilizzano le librerie per ML (il più comune è skLearn), non hanno una disposizione per gestire automaticamente questi dati mancanti e possono generare errori.
- Distorsione nel set di dati: – Una gran cantidad de datos faltantes puede causar distorsiones en la distribución de la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi...., vale a dire, può aumentare o diminuire il valore di una particolare categoria nel set di dati.
- Influenza il modello finale: – i dati mancanti possono causare distorsioni nel set di dati e possono portare a un'analisi errata da parte del modello.
Un altro e il motivo più importante è “Vogliamo ripristinare il set di dati completo”. Questo si verifica principalmente nel caso in cui non vogliamo perdere (più) dati dal nostro set di dati, poiché tutti sono importanti e, al secondo posto, la dimensione del set di dati non è molto grande e rimuoverne una parte può avere un impatto significativo. nel modello finale.
Eccellente..!! abbiamo alcune nozioni di base sui dati mancanti e sull'imputazione. Ora, Diamo un'occhiata alle diverse tecniche di imputazione e confrontiamole. Ma prima di buttarci dentro, dobbiamo conoscere i tipi di dati nel nostro set di dati.
Sembra strano..!!! Non preoccuparti... La maggior parte dei dati proviene da 4 tipi: – Numerico, Categorico, Data-ora e misto. Questi nomi si spiegano da soli, quindi non approfondiscono molto o li descrivono.
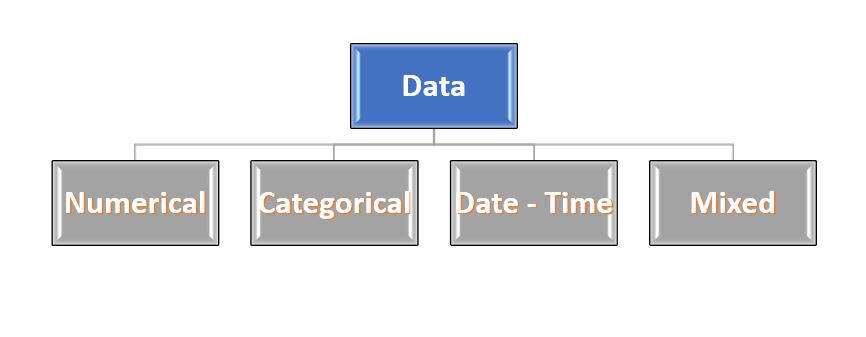
Fig 2: – Tipo di dati
Fonte: creato dall'autore
Tecniche di imputazione
Passando ai punti salienti di questo articolo … Tecniche utilizzate nell'imputazione …
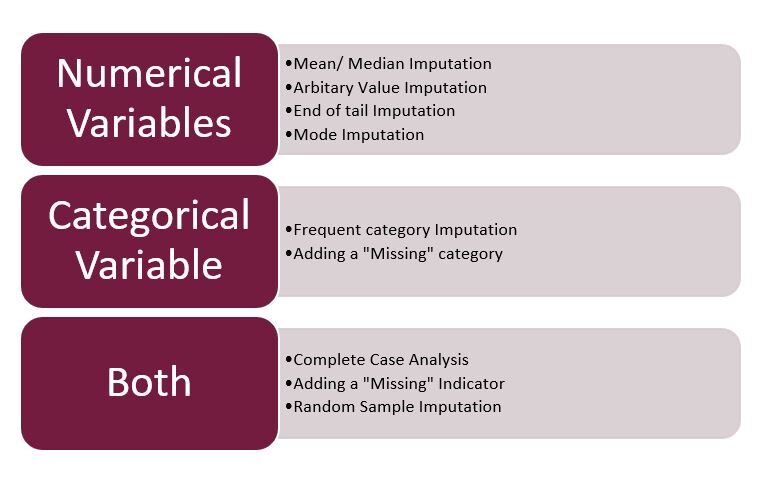
Fig 3: – Tecniche di imputazione
Fonte: creato dall'autore
Nota: – Qui mi concentrerò esclusivamente sull'imputazione mista, numerico e categorico. La data e l'ora faranno parte del prossimo articolo.
1. Analisi completa del caso (CCA): –
Questo è un metodo abbastanza semplice per gestire i dati mancanti, che rimuove direttamente le righe con dati mancanti, vale a dire, consideriamo solo quelle righe in cui abbiamo dati completi, vale a dire, nessun dato mancante. Questo metodo è anche popolarmente conosciuto come “elimina per elenco”.
- Ipotesi: –
- Mancano dati casuali (MAR).
- I dati mancanti vengono completamente rimossi dalla tabella.
- Vantaggio: –
- Facile da implementare.
- Nessuna manipolazione dei dati richiesta.
- Limitazioni: –
- I dati cancellati possono essere informativi.
- Può portare alla cancellazione di gran parte dei dati.
- Puoi creare una distorsione nel set di dati, se viene rimossa una grande quantità di un particolare tipo di variabile.
- Il modello di produzione non saprà cosa fare con i dati mancanti.
- Quando usare:-
- I dati sono MAR (Manca a caso).
- Buono per dati misti, numerico e categorico.
- I dati mancanti non sono più di 5% al 6% del set di dati.
- I dati non contengono molte informazioni e non distorceranno il set di dati.
- Codice:-
## Per controllare la forma del set di dati originale
train_df.shape
## Produzione (614 righe & 13 colonne) (614,13)
## Trovare le colonne che hanno valori nulli(Dati mancanti) ## Stiamo utilizzando un ciclo for per tutte le colonne presenti nel set di dati con valori medi nulli maggiori di 0
na_variables = [ var per var in train_df.columns se train_df[dove].è zero().Significare() > 0 ]
## Output dei nomi delle colonne con valori null ['Genere','Sposato','dipendenti','Lavoratore autonomo','Ammontare del prestito','Prestito_Importo_Durata',"Cronologia_credito"]
## Possiamo anche vedere i valori medi nulli presenti in queste colonne {Mostrato nell'immagine qui sotto}
data_na = trainf_df[na_variabili].è zero (). Significare ()
## Implementazione delle tecniche CCA per rimuovere i dati mancanti data_cca = train_df(asse=0) ### asse=0 viene utilizzato per specificare le righe
## Verifica della forma finale del set di dati rimanente data_cca.shape
## Produzione (480 righe & 13 colonne) (480,13)
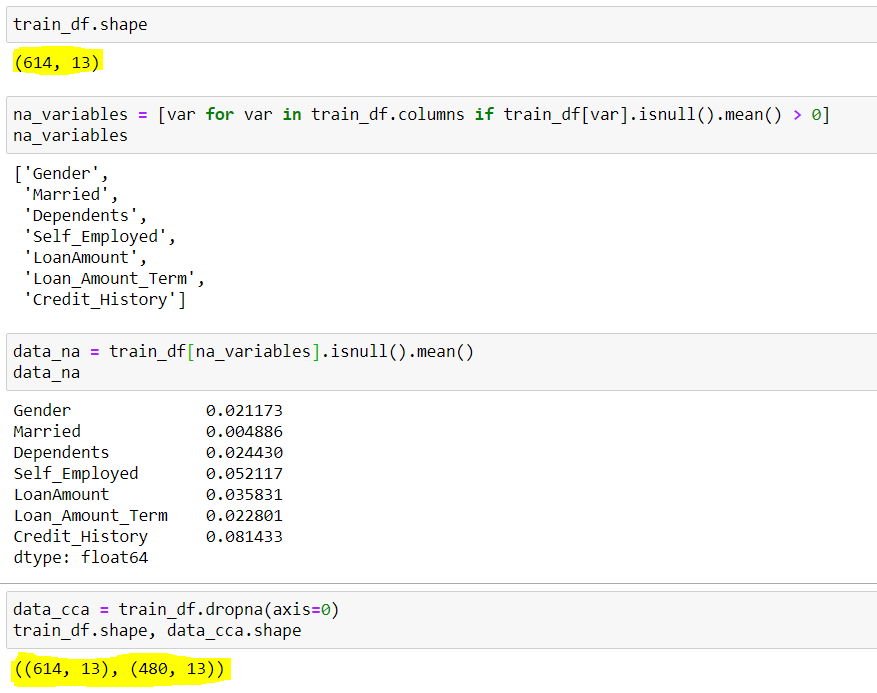
Figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... 3: – CCA
Fonte: Creato dall'autore
Qui possiamo vedere, il set di dati inizialmente aveva 614 righe e 13 colonne, di cui 7 le righe avevano dati mancanti(variabili_variabili), le sue righe centrali mancanti sono mostrate da data_na. Abbiamo osservato che, a parte e , hanno tutti una media inferiore a 5%. Quindi, secondo CCA, rimuoviamo le righe con dati mancanti, che ha portato a un set di dati con solo 480 righe. Qui puoi vedere in giro per il 20% di riduzione dei dati, che può causare molti problemi in futuro.
2. Assegnazione arbitraria del valore
Questa è una tecnica importante usata nell'imputazione, poiché può gestire sia variabili numeriche che categoriali. Questa tecnica afferma che raggruppiamo i valori mancanti in una colonna e li assegniamo a un nuovo valore che è lontano dall'intervallo di quella colonna. Generalmente, usiamo valori come 99999999 oh -9999999 oh “La mancanza” oh “Non definito” per variabili numeriche e categoriali.
- Ipotesi: –
- I dati non mancano a caso.
- Ai dati mancanti viene attribuito un valore arbitrario che non fa parte del set di dati o della media / medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... / moda dei dati.
- Vantaggio: –
- Facile da implementare.
- Possiamo usarlo in produzione.
- Preserva l'importanza di “valori mancanti” se esiste.
- Svantaggi: –
- Puoi distorcere la distribuzione della variabile originale.
- I valori arbitrari possono creare valori anomali.
- È necessaria una maggiore cautela quando si seleziona il valore arbitrario.
- Quando usare:-
- Quando i dati non sono MAR (Manca a caso).
- adatto a tutti.
- Codice:-
## Trovare le colonne che hanno valori nulli(Dati mancanti) ## Stiamo utilizzando un ciclo for per tutte le colonne presenti nel set di dati con valori medi nulli maggiori di 0
na_variables = [ var per var in train_df.columns se train_df[dove].è zero().Significare() > 0 ]
## Output dei nomi delle colonne con valori null ['Genere','Sposato','dipendenti','Lavoratore autonomo','Ammontare del prestito','Prestito_Importo_Durata',"Cronologia_credito"]
## Usa la colonna Genere per trovare i valori univoci nella colonna train_df['Genere'].unico()
## Produzione Vettore(['Maschio','Femmina',in])
## Qui non rappresentano i dati mancanti
## Utilizzo della tecnica dell'imputazione arbitraria, imputeremo il genere mancante con "Mancante" {Puoi usare anche qualsiasi altro valore}
arb_impute = train_df['Genere'].riempire('Mancante')
impute univoco.arb()
## Produzione Vettore(['Maschio','Femmina','Mancante'])
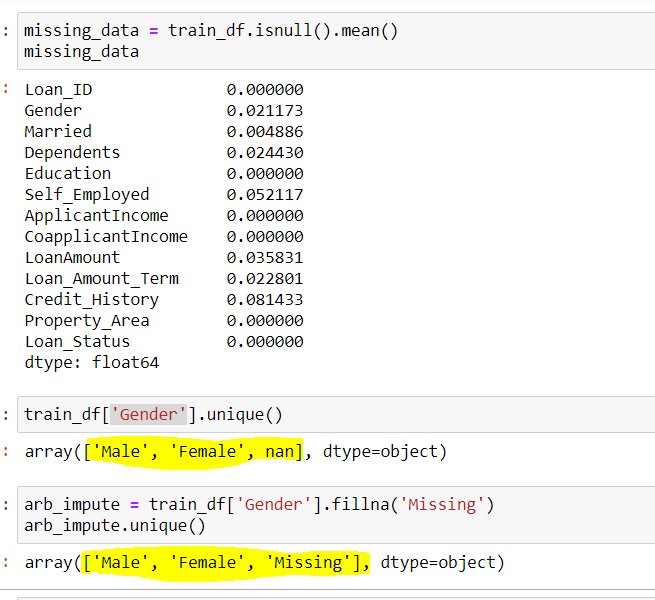
Fig 4: – imputazione arbitraria
Fonte: creato dall'autore
Possiamo vedere qui la colonna Genere avevo 2 valori unici {'Maschio femmina'} e pochi valori mancanti {in}. Quando si utilizza l'imputazione arbitraria, riempiamo i valori di {in} in questa colonna con {mancante}, per quello che ottieni 3 valori univoci per la variabile 'Sesso'.
3. Imputazione di categoria frequente
Questa tecnica dice di sostituire il valore mancante con la variabile con la frequenza più alta o in parole semplici sostituendo i valori con il Mode di quella colonna. Questa tecnica è anche conosciuta come Assegnazione modalità.
- Ipotesi: –
- Mancano dati casuali.
- C'è un'alta probabilità che i dati mancanti assomiglino alla maggior parte dei dati.
- Vantaggio: –
- L'implementazione è semplice.
- Possiamo ottenere un set di dati completo in brevissimo tempo.
- Possiamo usare questa tecnica nel modello di produzione.
- Svantaggi: –
- Maggiore è la percentuale di valori mancanti, maggiore è la distorsione.
- Può portare alla sovrarappresentazione di una particolare categoria.
- Puoi distorcere la distribuzione della variabile originale.
- Quando usare:-
- Mancano dati casuali (MAR)
- I dati mancanti non sono più di 5% al 6% del set di dati.
- Codice:-
## trovare il conteggio dei valori univoci in Genere train_df['Genere'].raggruppare per(train_df['Genere']).contare()
## Produzione (489 Maschio & 112 Femmina) Maschio 489 Femmina 112
## Il maschio ha la frequenza più alta. Possiamo farlo anche controllando la modalità train_df['Genere'].modalità()
## Produzione Maschio
## Utilizzo di computer di categoria frequente
frq_impute = train_df['Genere'].riempire('Maschio')
frq_impute.unique()
## Produzione Vettore(['Maschio','Femmina'])
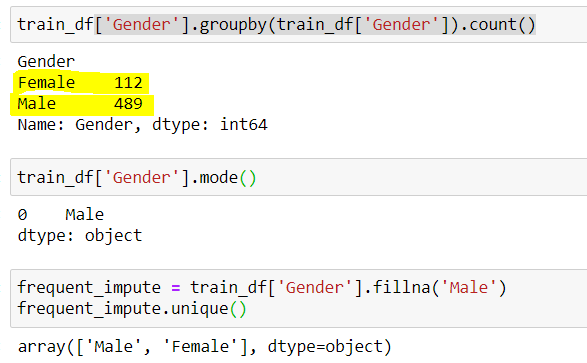
Fig 4: – Imputazione di categoria frequente
Fonte: creato dall'autore
Qui notiamo che “Maschile” era la categoria più frequente, quindi lo usiamo per sostituire i dati mancanti. Ora siamo lasciati soli 2 categorie, vale a dire, maschio e femmina.
Perciò, possiamo vedere che ogni tecnica ha i suoi vantaggi e svantaggi, e dipende dal set di dati e dalla situazione per cui le diverse tecniche che useremo.
È tutto da qui …
Fino ad allora, este es Shashank Singhal, un appassionato di Big Data e data science.
Buon apprendimento...
Se ti è piaciuto il mio articolo puoi seguirmi QUI
Profilo LinkedIn:- www.linkedin.com/in/shashank-singhal-1806
Nota: – Tutte le immagini utilizzate sopra sono state create da me (Autore).
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





