Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
introduzione
Elaborazione del linguaggio naturale (PNL) è un campo in cui convergono intelligenza artificiale e linguistica. L'obiettivo è far capire ai computer il linguaggio del mondo reale o il linguaggio naturale in modo che possano svolgere compiti in risposta alle domande, traduzione in lingua e molto altro.
La PNL ha molte applicazioni in diversi campi.
1. La PNL consente il riconoscimento e la previsione delle malattie sulla base di cartelle cliniche elettroniche.
2. Utilizzato per ottenere il feedback dei clienti.
3. Per aiutare a identificare le notizie false.
4. Chatbot.
5. Monitoraggio dei social media, eccetera.
Cos'è il trasformatore??
L'architettura del modello Transformer è stata presentata da Ashish Vaswani, Noam shazeer, Niki Parmar, Jakob Razoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin en su artículo “L'attenzione è tutto ciò di cui hai bisogno”. [1]
Il modello Transformer estrae le caratteristiche di ogni parola utilizzando un meccanismo di auto-attenzione per conoscere l'importanza di ogni parola nella frase. Non vengono utilizzate altre unità ricorrenti per estrarre questa funzione, sono solo attivazioni e somme ponderate, quindi possono essere molto efficienti e parallelizzabili.
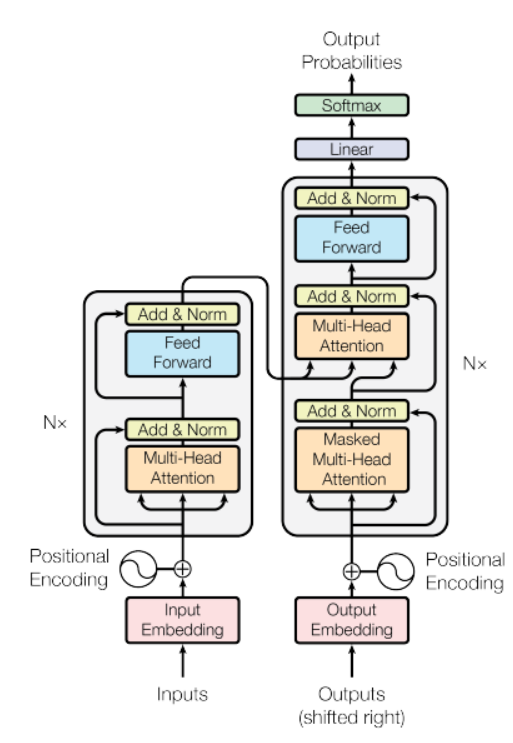
Fonte: documento “L'attenzione è tutto ciò di cui hai bisogno”
Nel figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.... anteriore, c'è un modello di encoder sul lato sinistro e il decoder sulla destra. Sia l'encoder che il decoder contengono un blocco centrale di attenzione e una rete di feedback ripetuto N numero di volte.
Nella figura sopra, c'è un modello di encoder sul lato sinistro e il decoder sulla destra. Sia l'encoder che il decoder contengono un blocco di attenzione centrale e una rete di feedback ripetuta N numero di volte.
Ha una pila di 6 codificatori e 6 decoder, l'encoder contiene due livelli (sottolivelli), vale a dire, uno strato di autocura multi-testa e una rete di alimentazione in avanti completamente connessa. Il decoder contiene tre strati (sottolivelli), uno strato di autocura multi-testa, un altro livello di auto-cura multi-testa per eseguire l'auto-cura sulle uscite dell'encoder e una rete di alimentazione in avanti completamente connessa. Cada subcapa en Decoder y Encoder tiene una conexión residual con standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... de capa.
Iniziamo a costruire un modello di traduzione linguistica
Qui useremo il set di dati Multi30k. Non preoccuparti, il set di dati verrà scaricato con uno snippet di codice.
Primo, la parte relativa al trattamento dei dati che utilizzeremo Torcia Modulo PyTorch. il Torcia dispone di utilità per creare set di dati che possono essere facilmente iterati per creare un modello di traduzione linguistica. Il codice seguente scaricherà il set di dati e tokenizzerà anche un testo non elaborato, construirá el vocabulario y convertirá tokens en un tensoreI tensori sono strutture matematiche che generalizzano concetti come scalari e vettori. Sono utilizzati in varie discipline, compresa la fisica, Ingegneria e Machine Learning, per rappresentare dati multidimensionali. Un tensore può essere visualizzato come una matrice multidimensionale, che consente di modellare relazioni complesse tra variabili diverse. La loro versatilità e capacità di gestire grandi volumi di informazioni li rendono strumenti fondamentali nell'analisi e nell'elaborazione dei dati.....
importare matematica importare il testo della torcia importare la torcia import torcia.nn come nn da torchtext.data.utils import get_tokenizer dall'importazione di collezioni Contatore da torchtext.vocab import Vocab da torchtext.utils import download_from_url, estratto_archivio da torch.nn.utils.rnn import pad_sequence da torch.utils.data import DataLoader da importazione torcia Tensor da torch.nn import (Trasforma Codifica, TrasformatoreDecodificatore,TransformerEncoderLayer, TransformerDecoderLayer) import io tempo di importazione
url_base ="https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/"
train_urls = ('treno.de.gz', 'train.en.gz')
val_urls = ('val.de.gz', 'val.en.gz')
test_urls = ('test_2016_flickr.de.gz', 'test_2016_flickr.en.gz')
train_filepaths = [estratto_archivio(download_from_url(url_base + URL))[0] per l'URL in train_urls]
val_filepaths = [estratto_archivio(download_from_url(url_base + URL))[0] per l'URL in val_urls]
test_filepaths = [estratto_archivio(download_from_url(url_base + URL))[0] per l'URL in test_urls]
de_tokenizer = get_tokenizer('spazioso', lingua="de_core_news_sm")
en_tokenizer = get_tokenizer('spazioso', lingua="en_core_web_sm")
def build_vocab(percorso del file, tokenizzatore):
contatore = contatore()
con io.open(percorso del file, codifica="utf8") come f:
per stringa_ in f:
counter.update(tokenizzatore(corda_))
torna Vocab(contatore, speciali=['<unk>', '<pad>', '<grappolo>', '<eos>'])
de_vocab = build_vocab(train_filepaths[0], de_tokenizer)
en_vocab = build_vocab(train_filepaths[1], it_tokenizer)
def data_process(percorsi file):
raw_de_iter = iter(io.open(percorsi file[0], codifica="utf8"))
raw_en_iter = iter(io.open(percorsi file[1], codifica="utf8"))
dati = []
per (raw_de, raw_en) in zip(raw_de_iter, raw_en_iter):
de_tensor_ = torcia.tensor([de_vocab[gettone] per token in de_tokenizer(raw_de.rstrip("n"))],
dtype=torcia.lunga)
en_tensor_ = torcia.tensor([en_vocab[gettone] per token in en_tokenizer(raw_en.rstrip("n"))],
dtype=torcia.lunga)
data.append((de_tensore_, en_tensore_))
restituire i dati
train_data = data_process(train_filepaths)
val_data = data_process(val_filepaths)
test_data = data_process(test_filepaths)
dispositivo = torcia.dispositivo('cuda' se torcia.cuda.is_available() altro "CPU")
BATCH_SIZE = 128
PAD_IDX = de_vocab['<pad>']
BOS_IDX = de_vocab['<grappolo>']
EOS_IDX = de_vocab['<eos>']
Quindi useremo il modulo PyTorch DataLoader che combina un set di dati e un campionatore, e ci permette di iterare sul set di dati dato. Il DataLoader supporta set di dati iterabili e in stile mappa con caricamento singolo o multithread, possiamo anche personalizzare l'ordine di caricamento e la fissazione della memoria.
# Caricatore dati
def generate_batch(data_batch):
de_batch, en_batch = [], []
per (de_item, it_item) in data_batch:
de_batch.append(torcia.cat([torcia.tensore([BOS_IDX]), de_item, torcia.tensore([EOS_IDX])], dim=0))
it_batch.append(torcia.cat([torcia.tensore([BOS_IDX]), it_item, torcia.tensore([EOS_IDX])], dim=0))
de_batch = pad_sequence(de_batch, padding_value=PAD_IDX)
en_batch = pad_sequence(it_batch, padding_value=PAD_IDX)
return de_batch, it_batch
train_iter = DataLoader(train_data, batch_size=BATCH_SIZE, casuale=Vero, collate_fn=generate_batch) valid_iter = DataLoader(val_data, batch_size=BATCH_SIZE, casuale=Vero, collate_fn=generate_batch) test_iter = DataLoader(dati di test, batch_size=BATCH_SIZE, casuale=Vero, collate_fn=generate_batch)
Quindi stiamo progettando il trasformatore. Qui, l'encoder elabora il flusso di input propagandolo attraverso una serie di livelli di rete feed-forward e multi-head care. L'output di questo codificatore è chiamato memoria di seguito e viene inviato al decodificatore insieme ai tensori di destinazione. Encoder e decoder sono addestrati end-to-end.
# trasformatore
classe Seq2SeqTransformer(nn.Modulo):
def __init__(se stesso, num_encoder_layers: int, num_decoder_layers: int,
emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
dim_feedforward:int = 512, ritirarsi:galleggiante = 0.1):
super(Trasformatore Seq2Seq, se stesso).__dentro__()
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
self.generator = nn.Lineare(emb_size, tgt_vocab_size)
self.src_tok_emb = Inserimento token(src_vocab_size, emb_size)
self.tgt_tok_emb = Inserimento token(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(emb_size, abbandono=abbandono)
def avanti(se stesso, src: tensore, trg: tensore, src_mask: tensore,
tgt_mask: tensore, src_padding_mask: tensore,
tgt_padding_mask: tensore, memory_key_padding_mask: tensore):
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
outs = self.transformer_decoder(tgt_emb, memoria, tgt_mask, Nessuno,
tgt_padding_mask, memory_key_padding_mask)
ritorno self.generator(fuori)
codifica def(se stesso, src: tensore, src_mask: tensore):
return self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decodificare(se stesso, tgt: tensore, memoria: tensore, tgt_mask: tensore):
return self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memoria,
tgt_mask)
Il testo convertito in token è rappresentato da incorporamenti di token. La funzione di codifica posizionale viene aggiunta all'incorporamento del token in modo da poter ottenere le nozioni di ordine delle parole.
class PositionalEncoding(nn.Modulo):
def __init__(se stesso, emb_size: int, ritirarsi, maxlen: int = 5000):
super(Codifica posizionale, se stesso).__dentro__()
den = torcia.exp(- torcia.arancione(0, emb_size, 2) * math.log(10000) / emb_size)
pos = torcia.arancione(0, maxlen).rimodellare(maxlen, 1)
pos_embedding = torcia.zero((maxlen, emb_size))
pos_embedding[:, 0::2] = torcia.sin(posizione * il)
pos_embedding[:, 1::2] = torcia.cos(posizione * il)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.dropout(ritirarsi)
self.register_buffer('pos_embedding', pos_embedding)
def avanti(se stesso, token_embedding: tensore):
ritorno self.dropout(token_embedding +
self.pos_embedding[:token_embedding.size(0),:])
class TokenEmbedding(nn.Modulo):
def __init__(se stesso, vocab_size: int, emb_size):
super(Incorporamento di token, se stesso).__dentro__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def avanti(se stesso, gettoni: tensore):
ritorna self.embedding(gettoni.lungo()) * math.sqrt(self.emb_size)
Qui, nel codice qui sotto, viene creata una maschera di parola successiva per impedire a una parola di destinazione di prestare attenzione alle sue parole successive. Le mascherine si creano anche qui, per mascherare i token di riempimento di origine e destinazione.
def generate_square_subsequent_mask(sz):
maschera = (torcia.triu(torch.ones((sz, sz), dispositivo=DISPOSITIVO)) == 1).trasporre(0, 1)
mask = mask.float().masked_fill(maschera == 0, galleggiante('-inf')).masked_fill(maschera == 1, galleggiante(0.0))
maschera di ritorno
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
src_mask = torcia.zero((src_seq_len, src_seq_len), dispositivo=DISPOSITIVO).genere(torcia.bool)
src_padding_mask = (origine == PAD_IDX).trasporre(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).trasporre(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
Luego defina los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... del modelo y cree una instancia del modelo.
SRC_VOCAB_SIZE = lunghezza(de_vocab)
TGT_VOCAB_SIZE = lunghezza(en_vocab)
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 512
BATCH_SIZE = 128
NUM_ENCODER_LAYERS = 3
NUM_DECODER_LAYERS = 3
NUM_EPOCHS = 50
DISPOSITIVO = torcia.dispositivo("miracoli":0' se torcia.cuda.è_disponibile() altro "CPU")
trasformatore = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
FFN_HID_DIM)
per p in trasformatore.parametri():
se p.dim() > 1:
nn.init.xavier_uniform_(P)
trasformatore = trasformatore.to(dispositivo)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
ottimizzatore = torcia.optim.Adam(
parametri.trasformatore(), lr=0,0001, beta =(0.9, 0.98), eps = 1°-9°
)
Definire due diverse funzioni, vale a dire, per la formazione e la valutazione.
def train_epoca(modello, train_iter, ottimizzatore):
modello.treno()
perdite = 0
per idx, (src, tgt) in enumerare(train_iter):
src = src.to(dispositivo)
tgt = tgt.to(dispositivo)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = modello(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
ottimizzatore.zero_grad()
tgt_out = tgt[1:, :]
perdita = perdita_fn(logits.reshape(-1, logits.forma[-1]), tgt_out.reshape(-1))
perdita.indietro()
ottimizzatore.passo()
perdite += loss.item()
torcia.salva(modello, IL PERCORSO)
perdite di ritorno / len(train_iter)
def valutare(modello, val_iter):
model.eval()
perdite = 0
per idx, (src, tgt) in (enumerare(valid_iter)):
src = src.to(dispositivo)
tgt = tgt.to(dispositivo)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = modello(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :]
perdita = perdita_fn(logits.reshape(-1, logits.forma[-1]), tgt_out.reshape(-1))
perdite += loss.item()
perdite di ritorno / len(val_iter)
Ora addestrando il modello.
per epoca in gamma(1, NUM_EPOCHS+1):
start_time = ora.ora()
train_loss = train_poch(trasformatore, train_iter, ottimizzatore)
end_time = time.time()
val_loss = valutare(trasformatore, valid_iter)
Stampa((F"Epoca: {epoca}, Perdita di treno: {train_loss:.3F}, Perdita di valore: {val_loss:.3F}, "
F"Tempo dell'epoca = {(Tempo scaduto - Ora di inizio):.3F}S"))
Questo modello viene addestrato utilizzando l'architettura del trasformatore in modo tale che si addestra più velocemente e converge anche a una perdita di convalida inferiore rispetto ad altri modelli RNN..
def greedy_decode(modello, src, src_mask, max_len, start_symbol):
src = src.to(dispositivo)
src_mask = src_mask.to(dispositivo)
memory = model.encode(src, src_mask)
ys = torcia.ones(1, 1).riempire_(start_symbol).genere(torcia.lunga).a(dispositivo)
per io nel raggio d'azione(max_len-1):
memoria = memoria.to(dispositivo)
memory_mask = torcia.zero(ys.forma[0], memoria.forma[0]).a(dispositivo).genere(torcia.bool)
tgt_mask = (generate_square_subsequent_mask(ys.size(0))
.genere(torcia.bool)).a(dispositivo)
out = model.decode(sì, memoria, tgt_mask)
out = out.transpose(0, 1)
prob = modello.generatore(fuori[:, -1])
_, next_word = torcia.max(probabilmente, debole = 1)
next_word = next_word.item()
ys = torcia.cat([sì,
torch.ones(1, 1).type_as(src.data).riempire_(next_word)], dim=0)
if next_word == EOS_IDX:
rottura
ritorno si
def tradurre(modello, src, src_vocab, tgt_vocab, src_tokenizer):
model.eval()
gettoni = [BOS_IDX] + [src_vocab.stoi[ha preso] per tok in src_tokenizer(src)] + [EOS_IDX]
num_tokens = len(gettoni)
src = (torcia.LongTensor(gettoni).rimodellare(num_tokens, 1))
src_mask = (torcia.zero(num_tokens, num_tokens)).genere(torcia.bool)
tgt_tokens = greedy_decode(modello, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).appiattire()
Restituzione " ".aderire([tgt_vocab.itos[ha preso] per tok in tgt_tokens]).sostituire("<grappolo>", "").sostituire("<eos>", "")
Ora, Testiamo il nostro modello di traduzione.
output = tradurre(trasformatore, "Un gruppo di persone davanti a un igloo .", de_vocab, en_vocab, de_tokenizer) Stampa(produzione)
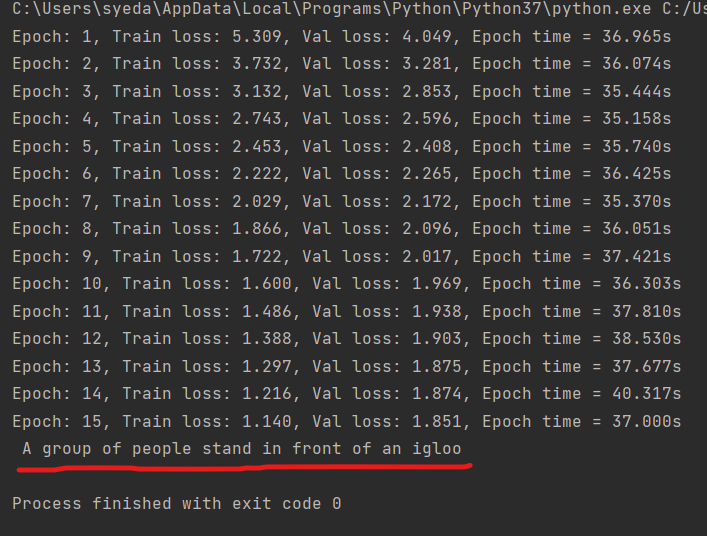
Sopra la linea rossa c'è il risultato del modello di traduzione. Puoi anche confrontarlo con google translate.
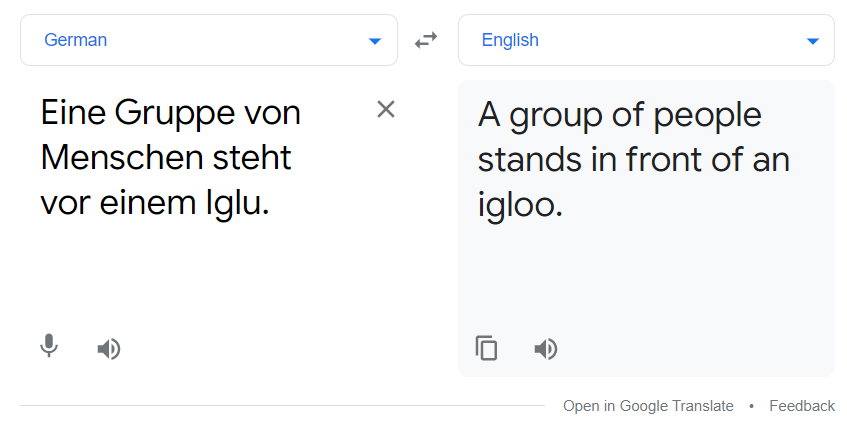
La traduzione di cui sopra e l'output del nostro modello corrispondevano. Il modello non è dei migliori, ma funziona ancora fino a un certo punto.
Riferimento
[1]. Ashish Vaswani, Noam shazeer, Niki Parmar, Jakob Razoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser e Illia Polosukhin: l'attenzione è tutto ciò di cui hai bisogno, dicembre di 2017, DOI: https://arxiv.org/pdf/1706.03762.pdf
Anche per maggiori informazioni, vedere https://pytorch.org/tutorials/
Grazie
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





