“La previsione è molto difficile, soprattutto se si tratta del futuro”.
qualsiasi idea dopo aver letto la bella citazione sopra. Ho spiegato diverse librerie automatizzate per automatizzare l'apprendimento automatico e i compiti di PNL nei miei articoli precedenti. Allo stesso modo, in questo articolo, Spiegherò "Come automatizzare la previsione delle serie temporali utilizzando Auto-TS".
Auto-TS fa parte di AutoML che automatizza alcuni dei componenti del processo di apprendimento automatico. Questo automatizza le librerie e aiuta i non esperti a formare un modello di apprendimento automatico di base senza avere molte conoscenze sul campo. Qui In questo articolo, Discuterò come automatizzare l'implementazione di un modello di previsione delle serie temporali utilizzando la libreria Auto-TS.
Cos'è Auto-TS?
È una libreria Python open source che viene fondamentalmente utilizzata per automatizzare la previsione delle serie temporali. Addestrerà automaticamente più modelli di serie temporali utilizzando una singola riga di codice, che ci aiuterà a scegliere il migliore per la nostra dichiarazione del problema.
Nella libreria Python open source, Auto-TS, auto-ts.Auto_TimeSeries () è la funzione principale che chiamerai con i dati del tuo treno. Dopo, possiamo scegliere che tipo di modelli vuoi, come modelli basati sulla statistica, ml o FB. También podemos ajustar los parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... que seleccionarán automáticamente el mejor modelo en función del parámetro de puntuación en el que queremos que se base. Restituirà il modello migliore e un dizionario contenente le previsioni per il numero di Forecast_periods che hai menzionato (predefinito = 2).
Funzionalità della libreria Auto-TS:
- Trova il modello di previsione delle serie temporali ottimale ottimizzando la programmazione genetica.
- Addestra modelli ingenui, statistiche, de aprendizaje automático y de apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute..., con tutte le possibili configurazioni di iperparametri e cross-validation.
- Esegue trasformazioni dei dati per gestire dati disordinati imparando l'imputazione NaN ottimale e l'eliminazione anomala.
- Scelta della combinazione metrica per la selezione del modello.
Installazione:
pip install autots O pip3 installa auto-ts O pip installare git+git://github.com/AutoViML/Auto_TS
Requisiti:
dask
scikit-learn
FB Prophet
statsmodels
pmdarima
XGBoost
Importare libreria utilizzando:
da auto_ts import auto_timeseries
Parametri disponibili in auto_timeseries:
modello = auto_timeseries( score_type="rmse", time_interval="Mese", non_seasonal_pdq=Nessuno, stagionalità=Falso, periodo_stagionale=12, model_type=['Profeta'], verboso=2)
È possibile regolare i parametri e analizzare il cambiamento nelle prestazioni del modello. Per maggiori dettagli sui parametri, clicca su qui.
Set di dati utilizzato:
Qui ho usato il Prezzo delle azioni Amazon set di dati per gennaio 2006 a gennaio 2018, che viene scaricato da Kaggle. Questa libreria offre solo modelli di previsione delle serie temporali dei treni. Il set di dati deve avere una colonna in formato data o ora.
Inizialmente, cargue el conjunto de datos de la Serie storicheUna serie temporale è un insieme di dati raccolti o misurati in tempi successivi, di solito a intervalli di tempo regolari. Questo tipo di analisi consente di identificare i modelli, Tendenze e cicli dei dati nel tempo. La sua applicazione è ampia, che coprono settori come l'economia, Meteorologia e sanità pubblica, facilitare la previsione e il processo decisionale basato su informazioni storiche.... con una columna de fecha y hora:
df = pd.read_csv("Amazon_Stock_Price.csv", usecols =['Data', 'Chiudere'])
df['Data'] = pd.to_datetime(df['Data'])
df = df.sort_values('Data')
Ora, dividere tutti i dati in dati di test e training:
train_df = df.iloc[:2800] test_df = df.iloc[2800:]
Ora, visualizzeremo la divisione di prova del treno:
train_df.Close.plot(figsize=(15,8), titolo="Prezzo delle azioni AMZN", dimensione del carattere = 14, etichetta="Treno") test_df.Close.plot(figsize=(15,8), titolo="Prezzo delle azioni AMZN", dimensione del carattere = 14, etichetta="Test") plt.legend() plt.grid() plt.mostra()
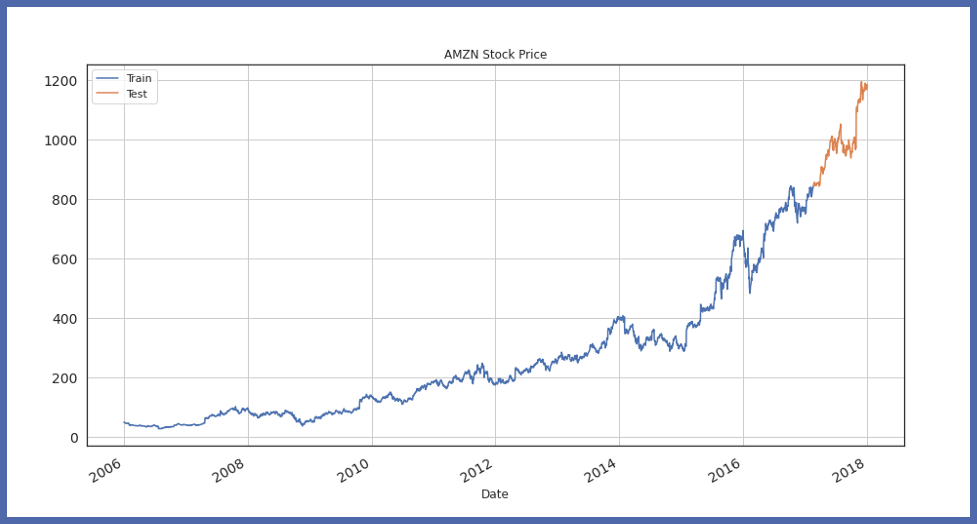
Ora, inicialicemos el objeto del modelo Auto-TS y ajustemos los datos de addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina....:
modello = auto_timeseries(forecast_period=219, score_type="rmse", time_interval="D", model_type="migliore") model.fit(traindata= train_df, ts_column="Data", obiettivo="Chiudere")
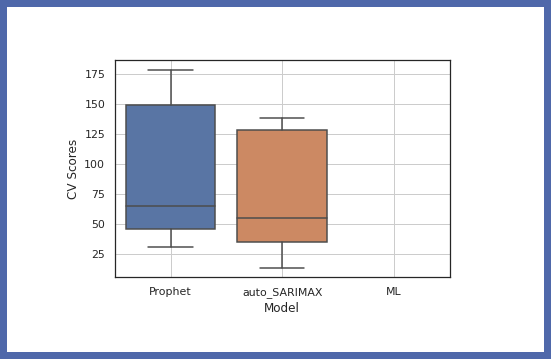
Ora confrontiamo la precisione di diversi modelli:
model.get_leaderboard() model.plot_cv_scores()
Ora testiamo il nostro modello con i dati di prova:
future_predictions = model.predict(dati di prova=219)
Finalmente, visualizzare il valore e la previsione dei dati di test:
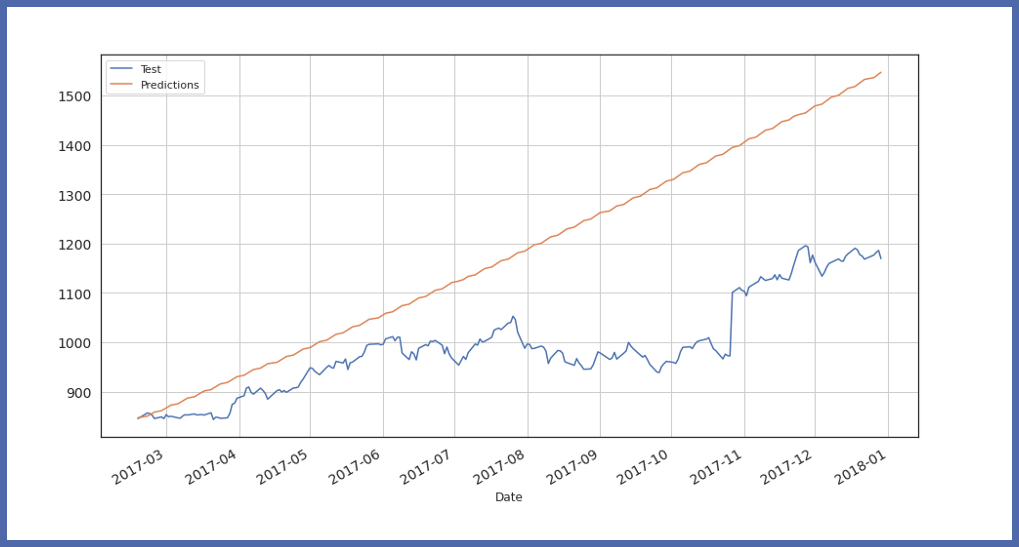
Parametri disponibili in auto_timeseries:
modello = auto_timeseries( score_type="rmse", time_interval="Mese", non_seasonal_pdq=Nessuno, stagionalità=Falso, periodo_stagionale=12, model_type=['Profeta'], verboso=2)
Parametri disponibili in model.fit ():
model.fit( traindata=train_data, ts_column=ts_column, target=target, cv=5, set="," )
Parametri disponibili in model.predict ():
forecasts = model.predict( testdata = può essere un dataframe o un numero intero che sta per forecast_period, modello="migliore" o qualsiasi altra stringa che rappresenta il modello addestrato )
Puoi giocare con tutti questi parametri e analizzare le prestazioni del nostro modello e quindi puoi selezionare il modello più adatto per la tua dichiarazione di problema.. Puoi controllare tutti questi parametri in dettaglio facendo clic su qui.
conclusione:
In questo articolo, Ho discusso di come il modello delle serie temporali può essere automatizzato in una riga di codice Python. Auto-TS esegue la preelaborazione dei dati, in quanto rimuove i valori anomali dai dati e gestisce i dati disordinati apprendendo l'imputazione NaN ottimale. Usando solo una riga di codice, inizializzazione dell'oggetto Auto-TS e regolazione dei dati del treno, addestrerà automaticamente più modelli di serie temporali come ARIMA, SARIMAX, Profeta FB, DOVE, e genererà il modello più performante adatto alla nostra dichiarazione del problema. L'output del modello sembra dipendere dalla dimensione del set di dati. Se proviamo ad aumentare la dimensione del set di dati, il risultato può sicuramente migliorare.
Nota finale
Spero che questo articolo ti sia piaciuto. Qualsiasi domanda? Mi sono perso qualcosa?? Per favore, contattami LinkedIn Oppure lascia un commento qui sotto. E infine, … Non c'è bisogno di dire,
Grazie per aver letto!
Salute!!
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





