introduzione
Occasionalmente, Viene sviluppata una libreria Python che ha il potenziale per cambiare il panorama nel campo della apprendimento profondoApprendimento profondo, Una sottodisciplina dell'intelligenza artificiale, si affida a reti neurali artificiali per analizzare ed elaborare grandi volumi di dati. Questa tecnica consente alle macchine di apprendere modelli ed eseguire compiti complessi, come il riconoscimento vocale e la visione artificiale. La sua capacità di migliorare continuamente man mano che vengono forniti più dati lo rende uno strumento chiave in vari settori, dalla salute.... PyTorch è una di quelle librerie.
Nelle ultime settimane, Mi sono dilettato un po' con PyTorch. Sono rimasto colpito da quanto sia facile da capire. Tra i vari framework di deep learning che ho usato fino ad oggi, PyTorch è stato il più flessibile e semplice di tutti.
![]()
In questo articolo, esploreremo PyTorch con un approccio più pratico, coprendo le basi insieme a un caso di studio. Confronteremo anche un neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. costruito da zero sia in numpy che in PyTorch per vedere le loro somiglianze nell'implementazione.
Andiamo avanti!
Nota: questo articolo presuppone che tu abbia una conoscenza di base dell'apprendimento profondo. Se vuoi recuperare il ritardo sull'apprendimento profondo, leggi prima questo articolo.
Cosa c'è di più, se vuoi una spiegazione più dettagliata di PyTorch da zero, capire come funzionano i tensionatori, come eseguire operazioni matematiche e matriciali con PyTorch, Consiglio vivamente di dare un'occhiata a Guida per principianti a PyTorch e come funziona da zero.
Sommario
- Una panoramica di PyTorch
- Tuffati nei tecnicismi
- Costruire una rete neurale in Numpy vs. PyTorch
- Confronto con altre librerie di deep learning
- Argomento di studio: risolvere un problema di riconoscimento delle immagini con PyTorch
Se preferisci affrontare i seguenti concetti in un formato strutturato, Puoi iscriverti a questo corso gratuito su PyTorch e seguili per capitoli.
Una panoramica di PyTorch
I creatori di PyTorch dicono di avere una filosofia: vogliono essere imperativi. Ciò significa che eseguiamo il nostro calcolo immediatamente. Questo si adatta perfettamente alla metodologia di programmazione Python, Che cosa non dobbiamo aspettare che tutto il codice sia scritto prima di sapere se funziona o no. Possiamo facilmente eseguire una parte del codice e ispezionarla in tempo reale. Per me, come debugger di reti neurali, Questa è una benedizione!
PyTorch è una libreria basata su Python creata per fornire flessibilità come piattaforma di sviluppo di deep learning. Il flusso di lavoro PyTorch è la cosa più vicina alla libreria di calcolo scientifico di Python: insensibile.
Ora potrei chiedere, Perché dovremmo usare PyTorch per costruire modelli di deep learning? Posso elencare tre cose che potrebbero aiutare a rispondere a questa domanda:
- API facile da usare – È semplice come può essere Python.
- Supporto Python – Come menzionato prima, PyTorch si integra perfettamente con lo stack di data science di Python. È così simile a numpy che potresti non notare nemmeno la differenza.
- Grafici di calcolo dinamico – Invece di grafici predefiniti con funzionalità specifiche, PyTorch ci fornisce un framework per costruire computer grafica attraverso misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... che avanziamo, e li cambiamo anche durante il runtime. Questo è prezioso per le situazioni in cui non sappiamo quanta memoria ci vorrà per creare una rete neurale..
Alcuni altri vantaggi dell'utilizzo di PyTorch sono il supporto multiGPU, caricatori di dati personalizzati e preprocessori semplificati.
Dal suo lancio all'inizio di gennaio 2016, molti ricercatori l'hanno adottata come libreria di riferimento per la sua facilità nella creazione di grafiche nuove e anche estremamente complesse. Avendolo detto, manca ancora del tempo prima che PyTorch venga adottato dalla maggior parte dei professionisti della scienza dei dati grazie al suo nuovo e “In costruzione”.
Tuffati nei tecnicismi
Prima di tuffarci nei dettagli, vediamo il flusso di lavoro PyTorch.
PyTorch utilizza un paradigma imperativo / ansioso. Vale a dire, ogni riga di codice richiesta per costruire un grafico definisce un componente di quel grafico. Possiamo eseguire autonomamente calcoli su questi componenti, anche prima che il tuo grafico sia completamente costruito. Questo si chiama “definizione per esecuzione”.

Fonte: http://pytorch.org/about/
Installare PyTorch è piuttosto semplice. Puoi seguire i passaggi indicati nel documenti ufficiali ed esegui il comando in base alle specifiche del tuo sistema. Ad esempio, questo era il comando che ho usato in base alle opzioni che ho scelto:
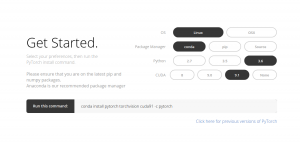
conda install pytorch torchvision cuda91 -c pytorch
Gli elementi principali che dobbiamo sapere quando si inizia con PyTorch sono:
- Tensionatori PyTorch
- Operazioni matematiche
- Modulo di autovalutazione
- Modulo Optim e
- modulo nn
Prossimo, daremo un'occhiata a ciascuno di essi in dettaglio.
Tensionatori PyTorch
I tensori non sono altro che matrici multidimensionali. I tensori in PyTorch sono simili ai ndarray in numpy, con l'aggiunta che i tensionatori possono essere utilizzati anche su GPU. Compatibile con PyTorch vari tipi di tenditori. Se hai familiarità con altri framework di deep learning, deve aver trovato anche tensori in TensorFlow. Infatti, puoi anche implementare le seguenti attività in Tensorflow e fare il tuo confronto tra PyTorch e TensorFlow.
È possibile definire un semplice array unidimensionale come mostrato di seguito:
# import pytorch importare la torcia # definire un tensore torcia.FloatTensor([2])
2 [torcia.FloatTensore di dimensione 1]
Operazioni matematiche
Come con numpy, è molto importante che una libreria di calcolo scientifico abbia implementazioni efficienti di funzioni matematiche. PyTorch ti offre un'interfaccia simile, insieme a più di 200 operazioni matematiche Puoi usare.
Di seguito è riportato un esempio di una semplice operazione di addizione in PyTorch:
a = torcia.FloatTensor([2]) b = torcia.FloatTensor([3]) un + B
5 [torcia.FloatTensore di dimensione 1]
Non sembra un approccio kinessenziale di Python?? Possiamo anche eseguire varie operazioni di matrice sui tensori PyTorch che definiamo. Ad esempio, trasporremo una matrice bidimensionale:
matrice = torcia.randn(3, 3) matrice 0.7162 1.0152 1.1525 -0.3503 -0.9452 -1.0861 -0.1093 -0.0927 -0.0476 [torcia.FloatTensore di dimensioni 3x3] matrice.t() 0.7162 -0.3503 -0.1093 1.0152 -0.9452 -0.0927 1.1525 -1.0861 -0.0476 [torcia.FloatTensore di dimensioni 3x3]
Modulo di autovalutazione
PyTorch utilizza una tecnica chiamata differenziazione automatica. Vale a dire, abbiamo un registratore che registra le operazioni che abbiamo eseguito e poi le riproduce per calcolare i nostri gradienti. Questa tecnica è particolarmente potente quando si costruiscono reti neurali, poiché risparmiamo tempo in una sola volta calcolando la differenziazione del parametriIl "parametri" sono variabili o criteri che vengono utilizzati per definire, misurare o valutare un fenomeno o un sistema. In vari campi come la statistica, Informatica e Ricerca Scientifica, I parametri sono fondamentali per stabilire norme e standard che guidano l'analisi e l'interpretazione dei dati. La loro corretta selezione e gestione sono fondamentali per ottenere risultati accurati e pertinenti in qualsiasi studio o progetto.... nel pass diretto.
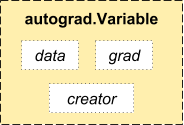
Fonte: http://pytorch.org/about/
dalla variabile di importazione torcia.autograd x = variabile(treno_x) y = variabile(train_y, require_grad=Falso)
Modulo ottimale
torch.optim è un modulo che implementa vari algoritmi di ottimizzazione utilizzati per costruire reti neurali. La maggior parte dei metodi più comunemente usati è già supportata, quindi non dobbiamo crearli da zero (A meno che tu non voglia!).
Di seguito è riportato il codice per utilizzare un ottimizzatore Adam:
ottimizzatore = torcia.optim.Adam(parametri.modello(), lr=learning_rate)
modulo nn
PyTorch autograd semplifica la definizione della grafica computazionale e l'acquisizione di gradienti, ma l'autogrado grezzo potrebbe essere un livello troppo basso per definire reti neurali complesse. Qui è dove il modulo nn può aiutare.
Il pacchetto nn definisce un insieme di moduli, che possiamo considerare come uno strato di rete neurale che produce un output dall'input e può avere dei pesi addestrabili.
Puoi considerare un modulo nn come il duro di PyTorch!
importare la torcia # definire il modello modello = torcia.nn.Sequenziale( torcia.nn.Lineare(input_num_units, unità_num_nascoste), torcia.nn.ReLU(), torcia.nn.Lineare(unità_num_nascoste, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss()
Ora che conosci i componenti di base di PyTorch, puoi facilmente costruire la tua rete neurale da zero. Seguilo se vuoi sapere come!
Costruire una rete neurale in Numpy vs. PyTorch
Ho menzionato sopra che PyTorch e Numpy sono molto simili. Vediamo perché. In questa sezione, vedremo un'implementazione di una semplice rete neurale per risolvere un problema di classificazione binaria (puoi leggere questo articolo per una spiegazione dettagliata).
## Rete neurale in numpy
importa numpy come np
#Input array
X=np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Produzione
y=np.array([[1],[1],[0]])
#Funzione sigmoide
def sigmoide (X):
Restituzione 1/(1 + np.exp(-X))
#Derivato della funzione sigmoide
def derivate_sigmoid(X):
restituire x * (1 - X)
#Inizializzazione variabile
epoch=5000 #Impostazione delle iterazioni di addestramento
lr=0.1 #Impostazione della velocità di apprendimento
inputlayer_neurons = X.shape[1] #numero di funzioni nel set di dati
hiddenlayer_neurons = 3 #numero di strati nascosti neuroni
output_neurons = 1 #numero di neuroni a livello di output
#inizializzazione del peso e del bias
wh=np.random.uniform(taglia=(inputlayer_neurons,hiddenlayer_neurons))
bh=np.random.uniform(taglia=(1,hiddenlayer_neurons))
wout=np.random.uniform(taglia=(hiddenlayer_neurons,output_neuroni))
bout=np.random.uniform(taglia=(1,output_neuroni))
per io nel raggio d'azione(epoca):
#Propagazione in avanti
hidden_layer_input1=np.dot(X,ns)
hidden_layer_input=hidden_layer_input1 + bh
hiddenlayer_activations = sigmoide(input_layer_nascosto)
output_layer_input1=np.dot(hiddenlayer_activations,strada)
output_layer_input= output_layer_input1+ incontro
uscita = sigmoide(output_layer_input)
#retropropagazione
E = uscita y
slope_output_layer = derivatives_sigmoid(produzione)
slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
d_output = E * slope_output_layer
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout += hiddenlayer_activations.T.dot(d_output) *lr
incontro += np.somma(d_output, asse=0,dim.mantenimento=Vero) *lr
wh += X.T.dot(d_hiddenlayer) *lr
bh + = np.somma(d_hiddenlayer, asse=0,dim.mantenimento=Vero) *lr
Stampa('effettivo :n', e, 'n')
Stampa("previsto" :n', produzione)
Ora, prova a individuare la differenza in un'implementazione semplicissima dello stesso in PyTorch (le differenze sono indicate in grassetto nel codice seguente).
## rete neurale in pytorch importare la torcia #Matrice di input X = torcia.Tensore([[1,0,1,0],[1,0,1,1],[0,1,0,1]]) #Produzione y = torcia.Tensore([[1],[1],[0]]) #Funzione sigmoide def sigmoide (X): Restituzione 1/(1 + torcia.exp(-X)) #Derivato della funzione sigmoide def derivate_sigmoid(X): restituire x * (1 - X) #VariabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... initialization epoch=5000 #Setting training iterations lr=0.1 #Setting learning rate inputlayer_neurons = X.shape[1] #numero di funzioni nel set di dati hiddenlayer_neurons = 3 #numero di strati nascosti neuroni output_neurons = 1 #numero di neuroni a livello di output #inizializzazione del peso e del bias wh=torcia.randn(inputlayer_neurons, hiddenlayer_neurons).genere(torcia.FloatTensor) bh=torcia.randn(1, hiddenlayer_neurons).genere(torcia.FloatTensor) strada =torcia.randn(hiddenlayer_neurons, output_neuroni) incontro=torcia.randn(1, output_neuroni) per io nel raggio d'azione(epocaEpoch è una piattaforma che offre strumenti per la creazione e la gestione di contenuti digitali. Il suo obiettivo è quello di facilitare la produzione multimediale, Consentire agli utenti di collaborare e condividere le informazioni in modo efficiente. Con un'interfaccia intuitiva, Epoch è diventata una scelta popolare tra i professionisti e le aziende che desiderano semplificare il proprio flusso di lavoro nell'era digitale. La sua versatilità lo rende adatto a diversi tipi di applicazioni..): #Propagazione in avanti nascosto_layer_input1 = torcia.mm(X, ns) hidden_layer_input = hidden_layer_input1 + bh hidden_layer_activations = sigmoide(input_layer_nascosto) output_layer_input1 = torcia.mm(hidden_layer_activations, strada) output_layer_input = output_layer_input1 + incontro uscita = sigmoide(output_layer_input1) #retropropagazione E = uscita y slope_output_layer = derivatives_sigmoid(produzione) slope_hidden_layer = derivatives_sigmoid(hidden_layer_activations) d_output = E * slope_output_layer Error_at_hidden_layer = torcia.mm(d_output, wout.t()) d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer senza += torcia.mm(hidden_layer_activations.t(), d_output) *lr incontro += d_output.sum() *lr wh += torcia.mm(X.t(), d_hiddenlayer) *lr bh += d_output.sum() *lr Stampa('effettivo :n', e, 'n') Stampa("previsto" :n', produzione)
Confronto con altre librerie di deep learning
In uno script di benchmarking, PyTorch ha dimostrato di superare con successo tutte le altre principali librerie di deep learning nel addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.... di una rete di memoria a lungo e breve termine (LSTM) avere il medianoLa mediana è una misura statistica che rappresenta il valore centrale di un insieme di dati ordinati. Per calcolarlo, I dati sono organizzati dal più basso al più alto e viene identificato il numero al centro. Se c'è un numero pari di osservazioni, I due valori fondamentali sono mediati. Questo indicatore è particolarmente utile nelle distribuzioni asimmetriche, poiché non è influenzato da valori estremi.... Tempo più basso per epoca (fare riferimento all'immagine qui sotto).

Le API per il caricamento dei dati sono ben progettate in PyTorch. Le interfacce sono specificate in un set di dati, un campionatore e un caricatore di dati.
Quando si confrontano gli strumenti per il caricamento dei dati in TensorFlow (lettori, cola, eccetera.), ho trovato PyTorchI moduli di caricamento dati sono abbastanza facili da usare. Cosa c'è di più, PyTorch è perfetto quando si cerca di costruire una rete neurale, quindi non dobbiamo fare affidamento su librerie di terze parti di alto livello come keras.
In secondo luogo, Non consiglierei comunque di utilizzare PyTorch per l'implementazione. PyTorch deve ancora evolversi. Come hanno detto gli sviluppatori di PyTorch, "Quello che stiamo vedendo è che gli utenti creano prima un modello PyTorch. Quando sono pronti a distribuire il loro modello in produzione, rendilo un modello Caffe 2 e poi lo inviano a una piattaforma mobile o un'altra ".
Argomento di studio: Risoluzione di un problema di riconoscimento delle immagini in PyTorch
Per familiarizzare con PyTorch, risolveremo il problema della pratica di apprendimento profondo di DataPeaker: Identificare le cifre. Diamo un'occhiata alla nostra dichiarazione del problema:
Il nostro problema è un problema di riconoscimento delle immagini, identificare le cifre di una data immagine di 28 X 28. Abbiamo un sottoinsieme di immagini per l'addestramento e il resto per testare il nostro modello.
Primo, scarica il treno e prova i file. Il set di dati contiene un file compresso di tutte le immagini e sia train.csv che test.csv prendono il nome dalle corrispondenti immagini train e test. Funzionalità aggiuntive non sono fornite nei set di dati, solo le immagini grezze sono fornite in formato '.png'.
Iniziamo:
PASO 0: Prepararsi
un) Importa tutte le librerie necessarie
# importare moduli %pylab in linea importare il sistema operativo importa numpy come np importa panda come pd da scipy.misc import imread da sklearn.metrics import precision_score
B) Impostiamo un valore seme, in modo da poter controllare la casualità dei nostri modelli
# Per fermare la potenziale casualità seme = 128 rng = np.random.RandomState(seme)
C) Il primo passo è impostare i percorsi delle directory, Per la tua sicurezza!
root_dir = os.path.abspath('.')
data_dir = os.path.join(root_dir, 'dati')
# verifica l'esistenza
os.path.exists(root_dir), os.path.exists(data_dir)
PASO 1: Caricamento e pre-elaborazione dei dati
un) Ora leggiamo i nostri set di dati. Questi sono in formato .csv e hanno un nome file insieme ai tag corrispondenti.
# caricare il set di dati treno = pd.read_csv(os.path.join(data_dir, 'Treno', 'treno.csv')) test = pd.read_csv(os.path.join(data_dir, 'Test.csv')) sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv')) train.head()
| nome del file | etichetta | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
B) Vediamo come sono i nostri dati!! Leggiamo la nostra immagine e la mostriamo.
# stampa un'immagine
img_name = rng.choice(treno.nomefile)
filepath = os.path.join(data_dir, 'Treno', 'Immagini', 'treno', nome_img)
img = imread(percorso del file, appiattire=Vero)
pylab.imshow(img, cmap='grigio')
pylab.axis('spento')
pylab.show()

D) Per una più facile manipolazione dei dati, memorizziamo tutte le nostre immagini come array numpy
# caricare immagini per creare treno e set di prova
temperatura = []
per img_name in train.filename:
image_path = os.path.join(data_dir, 'Treno', 'Immagini', 'treno', nome_img)
img = imread(percorso_immagine, appiattire=Vero)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temperatura)
train_x /= 255.0
train_x = train_x.reshape(-1, 784).come tipo('float32')
temperatura = []
per img_name in test.filename:
image_path = os.path.join(data_dir, 'Treno', 'Immagini', 'test', nome_img)
img = imread(percorso_immagine, appiattire=Vero)
img = img.astype('float32')
temp.append(img)
test_x = np.stack(temperatura)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).come tipo('float32')
train_y = train.label.values
e) Come è un tipico problema di AA, per testare il corretto funzionamento del nostro modello creiamo un set di validazione. Prendiamo una dimensione di divisione di 70:30 per il set di treni rispetto al set di convalida
# creare set di convalida split_size = int(train_x.shape[0]*0.7) treno_x, val_x = treno_x[:split_size], treno_x[split_size:] train_y, val_y = train_y[:split_size], train_y[split_size:]
PASO 2: Costruzione di modelli
un) Ora arriva la parte principale! Definiamo la nostra architettura di rete neurale. Definiamo una rete neurale con 3 livelli di input, nascosto ed esci. Il numero di neuroni di input e output è fisso, poiché l'input è la nostra immagine di 28 X 28 e l'uscita è un vettore di 10 X 1 cosa rappresenta la classe. Prendiamo 50 neuroni nello strato nascosto. Qui usiamo Adamo come i nostri algoritmi di ottimizzazione, che è una variante efficiente dell'algoritmo Gradient Descent.
importare la torcia dalla variabile di importazione torcia.autograd
# numero di neuroni in ogni strato input_num_units = 28*28 nascosto_num_units = 500 output_num_units = 10 # imposta le variabili rimanenti epoche = 5 batch_size = 128 tasso_di_apprendimento = 0.001
B) È ora di addestrare il nostro modello
# definire il modello modello = torcia.nn.Sequenziale( torcia.nn.Lineare(input_num_units, unità_num_nascoste), torcia.nn.ReLU(), torcia.nn.Lineare(unità_num_nascoste, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss() # definire l'algoritmo di ottimizzazione ottimizzatore = torcia.optim.Adam(parametri.modello(), lr=learning_rate)
## funzioni di supporto
# preelaborare un batch di set di dati
def preproc(unclean_batch_x):
"""Converti valori in intervallo 0-1"""
temp_batch = unclean_batch_x / unclean_batch_x.max()
return temp_batch
# creare un lotto
def batch_creator(dimensione del lotto):
dataset_name="treno"
dataset_length = train_x.shape[0]
batch_mask = rng.choice(dataset_length, dimensione del lotto)
batch_x = eval(nome_set di dati + '_X')[batch_mask]
batch_x = preproc(batch_x)
if dataset_name == 'train':
batch_y = eval(nome_set di dati).ix[batch_mask, 'etichetta'].valori
restituire batch_x, batch_y
# rete ferroviaria
total_batch = int(treno.forma[0]/dimensione del lotto)
per epoca in gamma(epoche):
avg_cost = 0
per io nel raggio d'azione(total_batch):
# creare batch
batch_x, batch_y = batch_creator(dimensione del lotto)
# passa quel batch per l'allenamento
X, y = variabile(torcia.da_numpy(batch_x)), Variabile(torcia.da_numpy(batch_y), require_grad=Falso)
prima = modello(X)
# perdersi, smarrirsi
perdita = perdita_fn(pred, e)
# eseguire la retropropagazione
perdita.indietro()
ottimizzatore.passo()
avg_cost += loss.data[0]/total_batch
Stampa(epoca, avg_cost)
# ottenere la precisione dell'allenamento X, y = variabile(torcia.da_numpy(preproc(treno_x))), Variabile(torcia.da_numpy(train_y), require_grad=Falso) prima = modello(X) final_pred = np.argmax(pred.data.numpy(), asse=1) precision_score(train_y, final_pred)
# ottieni l'accuratezza della convalida X, y = variabile(torcia.da_numpy(preproc(val_x))), Variabile(torcia.da_numpy(val_y), require_grad=Falso) prima = modello(X) final_pred = np.argmax(pred.data.numpy(), asse=1) precision_score(val_y, final_pred)
Il punteggio dell'allenamento risulta essere:
0.8779008746355685
mentre il punteggio di convalida è:
0.867482993197279
Questo è un punteggio piuttosto impressionante!, soprattutto quando abbiamo addestrato una rete neurale molto semplice per sole cinque epoche!
Note finali
Spero che questo articolo ti abbia dato un'idea di come il framework PyTorch può cambiare la prospettiva della costruzione di modelli di deep learning. In questo articolo, abbiamo appena graffiato la superficie. Per approfondire, Puoi leggi la documentazione e tutorial sulla pagina ufficiale di PyTorch.
Nei prossimi articoli, mi applicherò PyTorch per l'analisi audio e proveremo a creare modelli di deep learning per l'elaborazione del parlato. Rimani sintonizzato!
Hai usato PyTorch per creare un'applicazione o in uno qualsiasi dei tuoi progetti di data science?? Fammi sapere nei commenti qui sotto..





