Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Este artículo se centra en Apache MaialeIl maiale, un mammifero addomesticato della famiglia dei Suidi, È noto per la sua versatilità in agricoltura e nella produzione alimentare. Originario dell'Asia, Il suo allevamento si è diffuso in tutto il mondo. I maiali sono onnivori e hanno un'elevata capacità di adattarsi a vari habitat. Cosa c'è di più, svolgono un ruolo importante nell'economia, Fornitura di carne, cuoio e altri prodotti derivati. Anche la loro intelligenza e il loro comportamento sociale sono .... È una piattaforma di alto livello per elaborare e analizzare una grande quantità di dati.
PANORAMICA
Se osserviamo la panoramica di alto livello di Pig, Pig es una abstracción de Riduci mappaMapReduce è un modello di programmazione progettato per elaborare e generare in modo efficiente set di dati di grandi dimensioni. Sviluppato da Google, Questo approccio suddivide il lavoro in attività più piccole, che sono distribuiti tra più nodi in un cluster. Ogni nodo elabora la sua parte e poi i risultati vengono combinati. Questo metodo consente di scalare le applicazioni e gestire enormi volumi di informazioni, essere fondamentali nel mondo dei Big Data..... Maiale corre su Hadoop. Perciò, utiliza tanto el sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestione di grandi volumi di informazioni. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Cosa c'è di più, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... l'Hadoop (HDFSHDFS, o File system distribuito Hadoop, Si tratta di un'infrastruttura chiave per l'archiviazione di grandi volumi di dati. Progettato per funzionare su hardware comune, HDFS consente la distribuzione dei dati su più nodi, garantire un'elevata disponibilità e tolleranza ai guasti. La sua architettura si basa su un modello master-slave, dove un nodo master gestisce il sistema e i nodi slave memorizzano i dati, facilitare l'elaborazione efficiente delle informazioni..) come il sistema di elaborazione Hadoop, Riduci mappa. I flussi di dati vengono eseguiti
da un motore. Utilizzato per analizzare i set di dati come flussi di dati. Include un linguaggio di alto livello chiamato Pig Latin per esprimere questi flussi di dati.
La voce di Pig è Pig Latin, che diventeranno lavori MapReduce. Pig utilizza i trucchi di MapReduce per eseguire tutta l'elaborazione dei dati. Combina gli script Pig Latin in una serie di uno o più lavori MapReduce che vengono eseguiti.
Apache Pig è stato progettato da Yahoo perché è facile da imparare e con cui lavorare.. Quindi, Maiale rende Hadoop abbastanza facile. Apache Pig è stato sviluppato perché la programmazione di MapReduce stava diventando piuttosto difficile e molti utenti di MapReduce non sono a proprio agio con i linguaggi dichiarativi. Ora, Pig è un progetto open source sotto Apache.
SOMMARIO
- Caratteristiche del maiale
- Cerdo vs MapReduce
- Architettura del maiale
- Opzioni per la corsa dei maiali
- Comandi di esecuzione Pig di base
- Tipi di dati suini
- Operatori suini
- Esempio di scrittura latina di maiale
1. CARATTERISTICHE DEL MAIALE
Diamo un'occhiata ad alcune delle caratteristiche di Pig.
- Ha un ricco set di operatori come join, ordine, eccetera.
- È facile da programmare in quanto è simile a SQL.
- Le attività in Apache Pig sono state convertite automaticamente in lavori MapReduce. I programmatori dovrebbero concentrarsi solo sulla semantica del linguaggio e non su MapReduce.
- Puoi creare le tue funzioni usando Pig.
- Le funzioni in altri linguaggi di programmazione come Java possono essere incorporate negli script Pig Latin.
- Apache Pig può gestire
tutti i tipi di dati, come dati strutturati, non strutturato e semi-strutturato e
memorizza il risultato in HDFS.
2. CERDO VS MAPREDUCE
Vediamo la differenza tra Pig e MapReduce.
Il maiale ha diversi vantaggi rispetto a MapReduce.
Apache Pig è un linguaggio per il flusso di dati. Significa che consente agli utenti di descrivere come dovrebbero essere letti, elaborare e quindi memorizzare i dati da uno o più input a uno o più output in parallelo. Mentre MapReduce, In secondo luogo, è uno stile di programmazione.
Apache Pig è un linguaggio di alto livello, mentre MapReduce è compilato in codice java.
La sintassi Pig per eseguire join e file multipli è molto intuitiva e abbastanza semplice come SQL. MappaRiduci codice
diventa complesso se vuoi scrivere operazioni di join.
La curva di apprendimento di Apache Pig è molto piccola. L'esperienza nelle librerie Java e MapReduce è un must
per eseguire il codice MapReduce.
Gli script di Apache Pig possono fare l'equivalente di più righe di codice MapReduce e il codice MapReduce necessita di più righe di codice per eseguire le stesse operazioni.
Apache Pig è facile da eseguire il debug e da testare, mentre i programmi MapReduce impiegano molto tempo per codificare, Tentativo, eccetera. Pig Latin è meno costoso di MapReduce.
3. ARCHITETTURA SUINA
Ora diamo un'occhiata all'architettura di Pig.
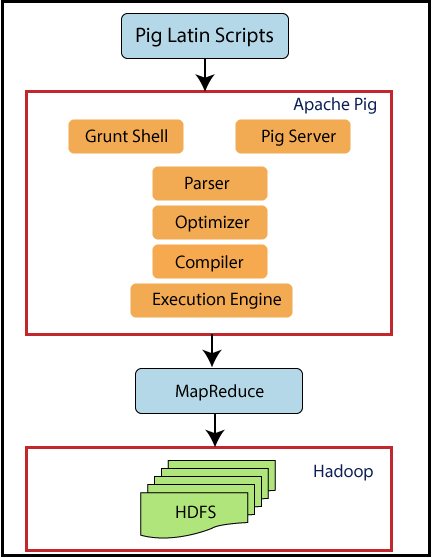
Il maiale si siede sopra Hadoop. Gli script Pig possono essere eseguiti nella shell Grunt o nel server Pig. Il runtime Pig the Pass ottimizza e compila lo script e alla fine lo converte in lavori MapReduce. Utilizza HDFS per archiviare dati intermedi tra i lavori MapReduce e quindi scrive il suo output su HDFS.
4. OPZIONI DI ESECUZIONE DEL MAIALE
Apache Pig può eseguire due modalità di esecuzione. Entrambi producono gli stessi risultati.
4.1. modalità locale
Comando in passerelle
maiale -x locale
4.2. Modo Hadoop
Comando in passerelle
maiale -exectype mapreduce
Apache Pig può essere eseguito in tre modi nelle due modalità sopra.
- Modalità batch / file di script: metti i comandi Pig in un file di script ed esegui lo script
- Programma integrato / UDF: incorporare i comandi Pig in Java ed eseguire gli script
5. COMANDI DI GUSCIO DI GRUNT DI MAIALE
I gusci di grunt possono essere usati per scrivere script Pig Latin. I comandi della shell possono essere invocati usando i comandi fs e sh. Vediamo alcune basi
Comandi maiale.
5.1. comando fs
Il comando fs ti consente di eseguire comandi HDFS da Pig
5.1.1 Per elencare tutte le directory in HDFS
grugnito> fs -ls;
Ora, verranno visualizzati tutti i file in HDFS.
5.1.2. Per creare una nuova directory mydir in HDFS
grugnito> fs -mkdir miadir/;
Il comando precedente creerà una nuova directory chiamata mydir in HDFS.
5.1.3. Per eliminare una directory
grugnito> fs -rmdir miadir;
Il comando precedente eliminerà la directory creata mydir.
5.1.4. Per copiare un file su HDFS
concedere> fs -put sales.txt sales/;
Qui, il file chiamato sales.txt è il file sorgente che verrà copiato nella directory di destinazione in HDFS, vale a dire, saldi.
5.1.5. Per uscire da Grunt Shell
grugnito> uscire;
Il comando precedente uscirà dalla shell grunt.
5.2. comando sh
Il comando sh ti consente di eseguire un'istruzione Unix da Pig
5.2.1. Per mostrare la data corrente
grugnito> sh data;
Questo comando visualizzerà la data corrente.
5.2.2. Per elencare i file locali
grugnito> sh ls;
Questo comando mostrerà tutti i file sul sistema locale.
5.2.3. Per eseguire Pig Latin da grunt shell
grugnito> eseguire salesreport.pig;
Il comando precedente eseguirà un file di script Pig Latin “reportvendite.pig” dal guscio grugnito.
5.2.4. Per eseguire Pig Latin dal prompt di Unix
$rapporto vendite suini.pig;
Il comando precedente eseguirà un file di script Pig Latin "salesreport.pig" dal prompt di Unix.
6. P
Pig Latin è costituito dai seguenti tipi di dati.
6.1. Atomo di dati
È un valore unico. Può essere una stringa o un numero. Sono di tipo scalare come int, galleggiante, Doppio, eccetera.
Ad esempio, “John”, 9.0
6.2. Doppio
Una tupla è simile a un record con una sequenza di campi. Può essere di qualsiasi tipo di dato.
Ad esempio, ('John', "Giacomo") è una tupla.
6.3. Borsa dati
Consiste in una raccolta di tuple che è equivalente a a “tavolo” e SQL. Le tuple non sono uniche e possono avere un numero arbitrario di campi, ognuno può essere di qualsiasi tipo.
Ad esempio, {('John', "Giacomo"), (‘ re ',’ segnare ')} è un insieme di dati equivalente alla seguente tabella in SQL.
6.4. Mappa dati
Questo tipo di dati
contiene una raccolta di coppie chiave-valore. Qui, la chiave deve essere un singolo carattere. I valori possono essere di qualsiasi tipo.
Ad esempio, [nome#('John', "Giacomo"), età#22] è una mappa dati dove nome, l'età è fondamentale e ('John,’ Giacomo'), 22 sono valori.
7. OPERATORI SUINI
Di seguito è riportato il contenuto del file student.txt.
John,23,Hyderabad James,45,Hyderabad Sam,33,Chennai ,56,Delhi ,43,Mumbai
7.1. CARICO
Carica i dati da un dato file system.
A = CARICA 'student.txt' AS (nome: chararray, età: int, città: chararray);
Dati dei file degli studenti con nomi di colonne come "nome", 'età', 'cittadina’ se cargarán en una variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... UN.
7.2. SCARICO
L'operatore DUMP viene utilizzato per visualizzare il contenuto di una relazione. Qui, verrà visualizzato il contenuto di A.
SCARICA A //risultati (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai) (,56,Delhi) (,43,Mumbai)
7.3. NEGOZIO
La funzione di salvataggio salva i risultati nel file system.
STORE A in "myoutput" utilizzando PigStorage('*');
Qui, i dati presenti in A verranno memorizzati in myoutput separati da '*'.
SCARICA il mio output;
//results
John*23*Hyderabad
James*45*Hyderabad
Sam*33*Chennai
*56*Delhi
*43*Mumbai
7.4. FILTRO
B = FILTRO A per nome non è nullo;
L'operatore FILTER filtrerà una tabella con alcune condizioni. Qui, il nome è la colonna in A. I valori non vuoti nel nome verranno memorizzati nella variabile B.
SCARICA B; //risultati (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai)
7.5. PER OGNUNO DA GENERARE
C = FOREACH A GENERATE nome, città;
L'operatore FOREACH è abituato ad accedere ai singoli record. Qui, le righe presenti nel nome e nella città saranno ricavate da A e memorizzate in C.
SCARICA C //risultati (John,Hyderabad) (James,Hyderabad) (Sam,Chennai) (,Delhi) (,Mumbai)
8. ESEMPIO DI SCRIPT LATINO DI MAIALE
Abbiamo un file di persone i cui campi sono l'identificazione del dipendente, il nome e gli orari.
001,Rajiv,21 002,siddart,12 003,Rajesh,22
Primo, caricare questi dati in un impiegato variabile. Filtralo per ore in meno di 20 e conservare part-time. Ordina part-time in ordine decrescente e salvalo in un altro file chiamato part_time. Visualizza contenuto.
La sceneggiatura sarà
impiegato = Carica "persone" come (empid, nome, ore); parttime = FILTRA dipendente PER Ore < 20; sorted = ORDINA parttime per ore DESC; NEGOZIO ordinato IN "part_time"; DUMP ordinato; DESCRIVERE ordinato; //risultati (003,Rajesh,22) (001,Rajiv,21)
NOTE FINALI
Queste sono alcune delle basi di Apache Pig. Spero che ti sia piaciuto leggere questo articolo. Inizia a praticare
con l'ambiente Cloudera.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.






{kind=link}