Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
Panoramica
K-means clustering è un algoritmo di apprendimento automatico non supervisionato molto famoso e potente. Utilizzato per risolvere molti problemi complessi di machine learning senza supervisione. Prima di iniziare, diamo un'occhiata ai punti che andremo a capire.
Sommario
- introduzione
- Come funziona l'algoritmo K-means??
- Come scegliere il valore di K?
- Metodo del gomito.
- Metodo Silhouette.
- Vantaggi di k-means.
- Svantaggi di k-means.
introduzione
Entendamos el algoritmo de raggruppamentoIl "raggruppamento" È un concetto che si riferisce all'organizzazione di elementi o individui in gruppi con caratteristiche o obiettivi comuni. Questo processo viene utilizzato in varie discipline, compresa la psicologia, Educazione e biologia, per facilitare l'analisi e la comprensione di comportamenti o fenomeni. In ambito educativo, ad esempio, Il raggruppamento può migliorare l'interazione e l'apprendimento tra gli studenti incoraggiando il lavoro.. de K-means con su definición simple.
Un algoritmo di raggruppamento K-means tenta di raggruppare elementi simili sotto forma di raggruppamenti. Il numero di gruppi è rappresentato da K.
Facciamo un esempio. Supponiamo che tu sia andato in un negozio di verdure per comprare alcune verdure. Lì vedrai diversi tipi di verdure. L'unica cosa che noterai è che le verdure saranno organizzate in un gruppo dei loro tipi.. Come tutte le carote saranno tenute in un unico posto, le patate saranno conservate con i loro tipi e così via. Se noti qui, allora scoprirai che stanno formando un gruppo o un gruppo, dove ciascuna delle verdure rimane all'interno del suo tipo di gruppo formando i gruppi.
Ahora entenderemos esto con la ayuda de una hermosa figura"Figura" è un termine che viene utilizzato in vari contesti, Dall'arte all'anatomia. In campo artistico, si riferisce alla rappresentazione di forme umane o animali in sculture e dipinti. In anatomia, designa la forma e la struttura del corpo. Cosa c'è di più, in matematica, "figura" è legato alle forme geometriche. La sua versatilità lo rende un concetto fondamentale in molteplici discipline.....
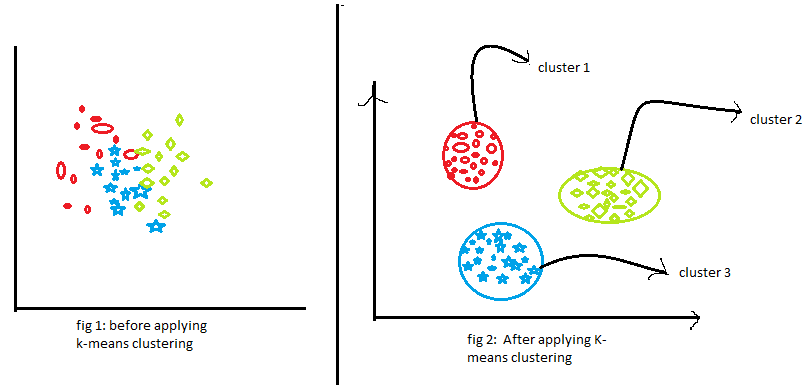
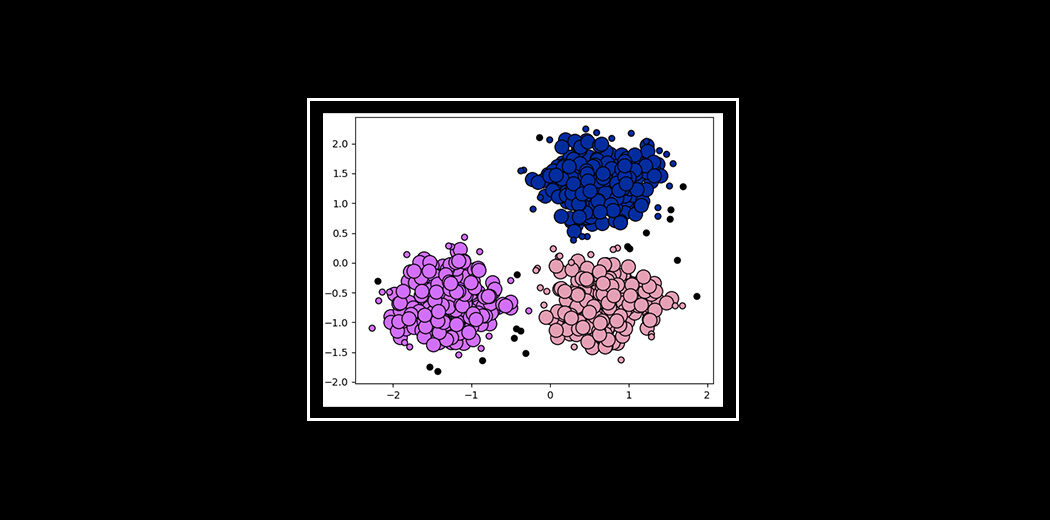
Ora, guarda le due figure sopra. che hai osservato Parliamo della prima figura. La prima figura mostra i dati prima di applicare l'algoritmo di raggruppamento k-means. Qui le tre diverse categorie sono disordinate. Quando vedi quei dati nel mondo reale, non potrai scoprire le diverse categorie.
Ora, guarda la seconda figura (figura 2). In questo modo vengono visualizzati i dati dopo l'applicazione dell'algoritmo di pool K-Means. Si può vedere che i tre diversi elementi sono classificati in tre diverse categorie chiamate gruppi.
Come funziona l'algoritmo di clustering K-media??
k-significa che il raggruppamento tenta di raggruppare tipi simili di elementi sotto forma di raggruppamenti. Trova la somiglianza tra gli elementi e raggruppali in gruppi. L'algoritmo di raggruppamento K-means funziona in tre fasi. Vediamo quali sono questi tre passaggi.
- Selezionare i valori di k.
- Inizializzare i centroidi.
- Seleziona il gruppo e trova la media.
Comprendiamo i passaggi precedenti con l'aiuto della figura perché una buona immagine è migliore delle migliaia di parole.
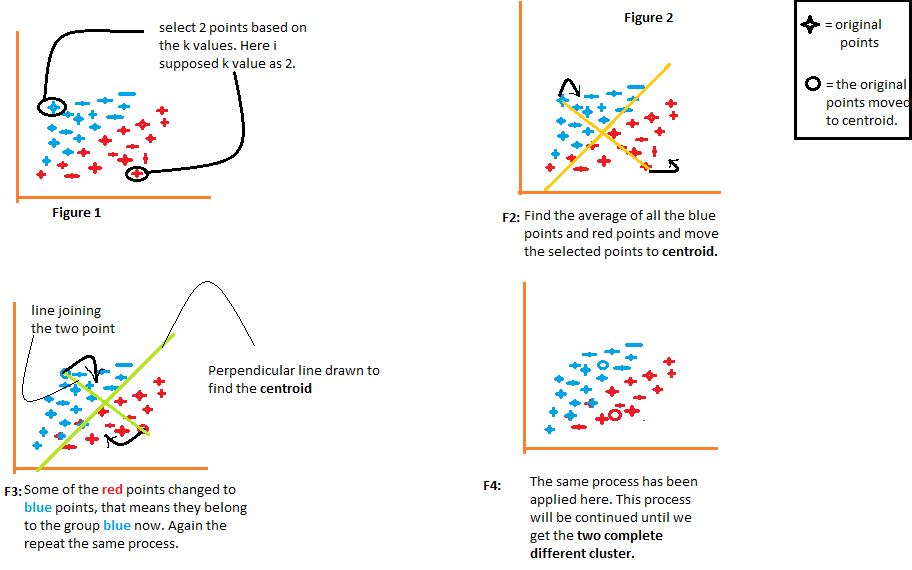
Capiremo ogni figura una per una.
- La figura 1 mostra la rappresentazione dei dati di due elementi diversi. Il primo elemento è stato mostrato in blu e il secondo elemento è stato mostrato in rosso. Qui scelgo il valore di K in modo casuale come 2. Esistono diversi metodi con cui possiamo scegliere i valori k corretti.
- Nella figura 2, unisce i due punti selezionati. Ora, per scoprire il centroide, tracceremo una linea perpendicolare a quella linea. I punti verranno spostati nel loro centroide. Se guardi lì, Vedrai che alcuni dei punti rossi ora si spostano sui punti blu. Ora, Questi punti appartengono al gruppo di elementi blu.
- Lo stesso processo continuerà nella figura 3. Uniremo i due punti e tracceremo una linea perpendicolare a quella e troveremo il centroide. Ora i due punti si sposteranno nel loro centroide e di nuovo alcuni dei punti rossi si trasformeranno in punti blu.
- Lo stesso processo sta accadendo nella figura 4. Questo processo continuerà fino a quando non avremo due gruppi completamente diversi da questi gruppi..
NOTA: Si noti che il raggruppamento K-means utilizza il metodo della distanza euclidea per scoprire la distanza tra i punti.
Troverete molte spiegazioni sulla distanza euclidea su Internet.
Come scegliere il valore di K?
Uno dei compiti più impegnativi di questo algoritmo di raggruppamento è scegliere i valori corretti di k. Quale dovrebbe essere il valore k corretto? Come scegliere il valore k? Troviamo la risposta a queste domande. Se si scelgono valori k a caso, può essere giusto o sbagliato. Se scegli il valore sbagliato, influenzerà direttamente le prestazioni del modello. Quindi, Esistono due metodi con cui è possibile selezionare il valore corretto di K.
- Metodo del gomito.
- Metodo Silhouette.
Ora, comprendiamo entrambi i concetti uno per uno in dettaglio.
Metodo del gomito
Il gomito è uno dei metodi più famosi con cui è possibile selezionare il valore corretto di k e aumentare le prestazioni del modello. Eseguiamo anche la regolazione degli iperparametri per scegliere il miglior valore di k. Vediamo come funziona questo metodo a gomito.
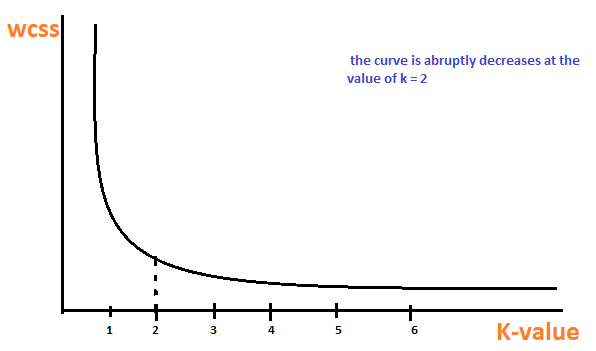
È un metodo empirico per trovare il miglior valore di k. raccogliere l'intervallo di valori e trarne il meglio. Calcola la somma del quadrato dei punti e calcola la distanza media.
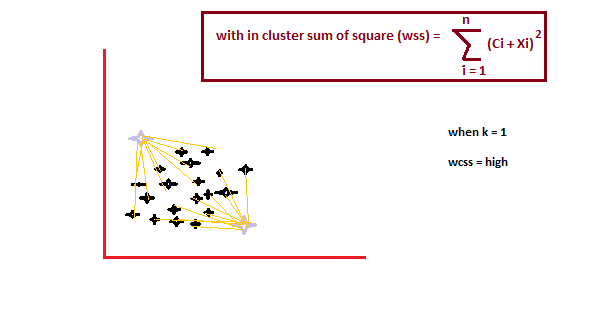
Quando il valore di k è 1, la somma del quadrato all'interno del gruppo sarà alta. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... che aumenta il valore di k, la somma del valore quadrato all'interno del gruppo diminuirà.
Finalmente, tracceremo un grafico tra i valori k e la somma del quadrato all'interno del gruppo per ottenere il valore k. Esamineremo attentamente il grafico. È compatibile con vari linguaggi come Python, il nostro grafico diminuirà bruscamente. Tale punto è considerato come un valore di k.
Metodo Silhouette
Il metodo della silhouette è in qualche modo diverso. Il metodo del gomito prende anche l'intervallo di k-valori e disegna il grafico della siluetta. Calcola il coefficiente di silhouette di ogni punto. Calcola la distanza media dei punti all'interno del tuo gruppo a (io) e la distanza media dei punti dal prossimo gruppo più vicino chiamato b (io).

Nota: Il a (io) Il valore deve essere inferiore a B (io) valore, cos'è ai << con un.
Ora, abbiamo i valori di un (io) e B (io). calcoleremo il coefficiente di siluetta utilizzando la seguente formula.
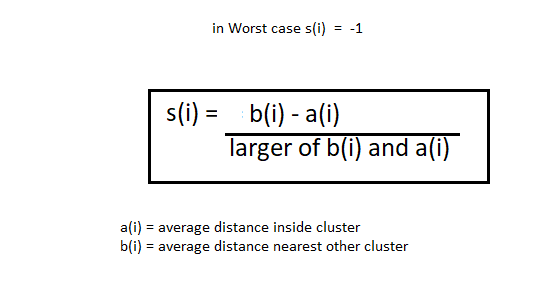
Ora, possiamo calcolare il coefficiente di siluetta di tutti i punti nei gruppi e tracciare il grafico della siluetta. Questo grafico sarà utile anche per rilevare i valori anomali. La trama della silhouette è tra -1 un 1.
Si noti che per il coefficiente di siluetta uguale a -1 è lo scenario peggiore.
Guarda il grafico e controlla quale dei valori k è più vicino a 1.
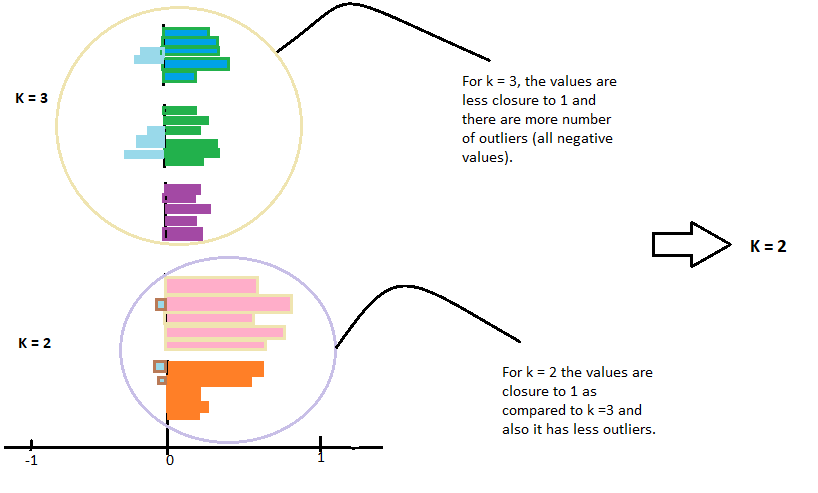
Cosa c'è di più, Controllare il grafico con meno valori anomali, il che significa un valore meno negativo. Quindi scegli quel valore k per il tuo modello da sintonizzare.
Vantaggi dei mezzi K
- È molto semplice da implementare.
- È scalabile per un set di dati di grandi dimensioni e anche più veloce per set di dati di grandi dimensioni.
- adatta molto spesso nuovi esempi.
- Generalizzazione di cluster per diverse forme e dimensioni.
Svantaggi dei mezzi K
- È sensibile ai valori anomali.
- Scegliere manualmente i valori k è un lavoro difficile.
- All'aumentare del numero di dimensioni, la sua scalabilità diminuisce.





