Questo post è stato reso pubblico come parte del Blogathon sulla scienza dei dati
introduzione
campionamento per ottenere la probabilità di un intervallo di una quantità sconosciuta. Sembra difficile! Non preoccuparti, lo esploreremo in profondità in questo post
Una breve storia:
Il metodo Monte Carlo è stato inventato da John Neumann e Ulam Stanislaw per guidare il processo decisionale in condizioni incerte. Prende il nome da una nota città di casinò di Monte Carlo chiamata Monaco, poiché l'elemento del caso è centrale nell'approccio alla modellizzazione, poiché è simile a un gioco di roulette.
In parole semplici, La simulazione Monte Carlo è un metodo di stimare il valore di una quantità sconosciuta con l'aiuto della statistica inferenziale. Non è necessario approfondire le statistiche inferenziali per avere una solida comprensione di come funziona la simulazione Monte Carlo. Nonostante questo, questo post esaminerà solo quei punti di statistica inferenziale che saranno rilevanti per noi nella simulazione Monte Carlo.
La statistica inferenziale è responsabile della popolazione qual è la nostra serie di esempi e Spettacoli, che è un sottoinsieme adatto della popolazione. Il punto chiave a cui prestare attenzione è che un campione casuale tende a mostrare lo stesso caratteristiche / proprietà come la popolazione da cui è estratta.
Vedremo un esempio per capire come funziona la simulazione Monte Carlo.
Il nostro obiettivo è stimare la probabilità di andare avanti se lanciamo una moneta un numero infinito di volte..
1. Diciamo che lo giriamo una volta e andiamo avanti. Possiamo dire con sicurezza che la nostra risposta è 1?
2. Ora abbiamo lanciato di nuovo la moneta e la faccia è riapparsa. Siamo sicuri che anche la prossima uscita sarà avanti??
3. Lo giriamo più e più volte, Diciamo 100 volte, e stranamente la testa appare ogni volta. Ora, Dobbiamo accettare il fatto che il prossimo turno si tradurrà in un'altra testa??
4. Cambiamo scena e supponiamo che 100 rilasci, 52 ha provocato il riposo della testa, 48 sono diventate croci. La probabilità che il prossimo lancio colpisca la testa è 52/100? Data l'osservazione, è la nostra migliore stima, ma la fiducia rimarrà bassa.
Perché c'è una differenza nel livello di confidenza??
È fondamentale sapere che la nostra stima dipende da due cose
1. Taglia: La dimensione del campione (come esempio, 100 vs 2 Nei casi 2 e 4 rispettivamente)
2. Differenza: varianza di campionamento (tutti i risultati come testa vs. 52 teste come nel caso 3 e 4 rispettivamente)
3. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... que aumenta la varianza de la observación (casi 3 e 4), nasce la necessità di una più ampia osservazione (come nei casi 2 e 4) avere lo stesso grado di fiducia.
Ora simuleremo un gioco di roulette (pitone):
Roulette è un gioco in cui un disco con blocchi (metà rosso e metà nero) in cui può essere contenuta una palla, girare con una palla. Dobbiamo indovinare un numero e se la pallina si ferma su questo numero, allora è una vittoria, e abbiamo vinto un importo di (importo pagato per una slot
) X (no. Del totale delle slot nella macchina).
classe Roulette():
def __init__(se stesso):
self.pockets = []
per io nel raggio d'azione(1,37):
self.pockets.append(io)
self.ball = None
self.pocketOdds = len(self.pockets) - 1
def spin(se stesso):
self.ball = random.choice(self.pockets)
def betPocket(se stesso, Tasca, Amt):
se str(Tasca) == str(self.ball):
return amt*self.pocketOdds
else: return -amt
def __str__(se stesso):
return 'Fair Roulette'
def playRoulette(gioco, numSpins, Tasca, Scommettere):
totPocket = 0
per io nel raggio d'azione(numSpins):
game.spin()
totPocket += game.betPocket(Tasca, Scommettere)
se toPrint:
Stampa (numSpins, 'giri di', gioco)
Stampa ('Scommesse sul rendimento previsto', Tasca, '=',
str(100*totPocket/numSpins) + '%n')
Restituzione (totPocket/numSpins)
gioco = Roulette()
per numSpins in (100, 1000000):
per io nel raggio d'azione(3):
playRoulette(gioco, numSpins, 5, 1, Vero)
100 Giri della roulette
Scommesse di ritorno previste 5 = -100.0%
100 Giri della roulette
Scommesse di ritorno previste 5 = 42.0%
100 Giri della roulette
Scommesse di ritorno previste 5 = -26.0%
1000000 Giri della roulette
Scommesse di ritorno previste 5 = -0,0546%
1000000 Giri della roulette
Scommesse di ritorno previste 5 = 0,502%
1000000 Giri della roulette
Scommesse di ritorno previste 5 = 0,7764%
Legge dei grandi numeri
In ripetuti test indipendenti con la probabilità p costante della popolazione di un particolare risultato su ciascun test, la probabilità che il risultato si verifichi, In altre parole, ottenuto da campioni. Differisce di p converge a zero Come la il numero di prove va all'infinito.
Significa semplicemente che se si verificano deviazioni (varianza) comportamento atteso (probabilità p), è probabile che queste deviazioni vengano compensate in futuro dalla deviazione opposta.
Ora parliamo di un episodio interessante che ha avuto luogo il 18 agosto 1913, in un casinò di Montecarlo. Alla roulette, il nero ha scalato un record ventisei volte di fila, e il panico è sorto per scommettere sul rosso (per eguagliare la deviazione dal comportamento previsto)
Analizziamo matematicamente questa situazione
1. Probabilità 26 rossi consecutivi = 1 / 67,108,865
2. Probabilità 26 rossi consecutivi quando 25 le pergamene precedenti erano rosse = 1/2
Regressione alla media
1. Dopo un evento casuale estremo, è probabile che il prossimo evento casuale sia meno estremo, in modo che la media sia mantenuta.
2. Come esempio, se la ruota della roulette viene girata 10 volte e i rossi vengono ogni volta, allora è un evento estremo = 1/1024 ed è probabile che nel prossimo 10 giri otteniamo meno di 10 rosso, ma il numero medio è 5 soltanto.
Quindi, quando osserviamo la media di 20 giri, sarà più vicino alla media attesa di 50% di rosso che di 100% nel primo 10 giri.
Ora è il momento di affrontare un po' di realtà.
Spazio di campionamento dei possibili risultati
1. Non è possibile garantire una perfetta precisione attraverso il campionamento e non si può dire che una stima non sia esattamente corretta..
Siamo di fronte a una domanda qui: Quanti campioni ci vogliono per guardare prima di poter avere una fiducia significativa nella nostra risposta?
Dipende dalla variabilità della distribuzione sottostante.
Livelli di confidenza e intervalli di confidenza
Proprio come in una situazione di vita reale, non possiamo essere sicuri di alcun parametro sconosciuto ottenuto da un campione per l'intera popolazione, quindi usiamo livelli di confidenza e intervalli di confidenza.
L'intervallo di confidenza fornisce un intervallo in cui è probabile che il valore sconosciuto sia contenuto con la certezza che il valore sconosciuto rientri rigorosamente in tale intervallo..
Come esempio, le prestazioni delle scommesse su una slot machine 1000 volte nella roulette è -3% con un margineMargine è un termine usato in una varietà di contesti, come la contabilità, Economia e stampa. In contabilità, si riferisce alla differenza tra ricavi e costi, che permette di valutare la redditività di un'impresa. Nel campo dell'editoria, Il margine è lo spazio bianco intorno al testo di una pagina, che lo rende facile da leggere e fornisce una presentazione estetica. La sua corretta gestione è fondamentale.. de error de +/- 4% con un livello di confidenza di 95%.
Può essere ulteriormente decodificato mentre eseguiamo un test infinito di 1000,
Resa media / la media prevista sarebbe -3%
Le prestazioni varierebbero all'incirca tra + 1% e -7% che oltre al 95% dei tempi.
Densità di probabilità (PDF).
La distribuzione della forma generale è stabilita attraverso la funzione di densità di probabilità (PDF). Se establece como la probabilidad de que la variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... aleatoria se encuentre entre un intervalo.
L'area sotto la curva tra i due punti PDF è la probabilità che la variabile casuale sia all'interno di tale intervallo.
Concludiamo il nostro apprendimento con un esempio:
Diciamo che c'è un mazzo di carte mescolate e dobbiamo trovare la probabilità di ottenere 2 re consecutivi se posizionano le carte nell'ordine in cui sono state posate.
Metodo analitico:
P (almeno 2 re consecutivi) = 1-P (nessun re consecutivo)
= 1- (49! X 48!) / ((49-4)! X52!) = 0.217376
Con la simulazione di Monte Carlo:
Passi
1. Seleziona ripetutamente punti dati casuali: qui assumiamo che il mescolamento delle carte sia casuale
2. Esecuzione di calcoli deterministici. Molti di questi si mescolano e trovano i risultati.
3. Combina i risultati: Esplorando il risultato e terminando con la nostra conclusione.
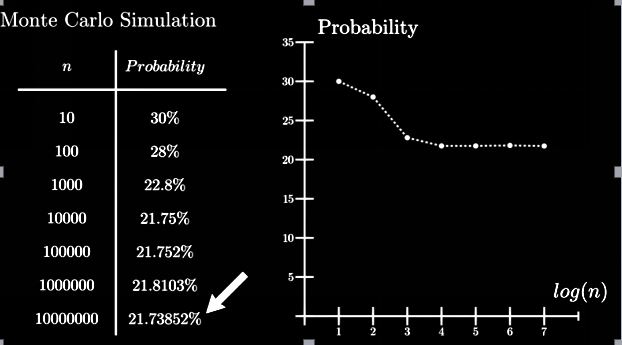
Attraverso il metodo Monte Carlo otteniamo una soluzione quasi esatta dal metodo analitico.
Vantaggi della simulazione Monte Carlo
- Facile da implementare e fornisce campionamento statistico per esperimenti numerici utilizzando il computer.
- Ci fornisce soluzioni approssimate soddisfacenti a problemi matematici computazionalmente costosi.
- Può essere utilizzato sia per problemi deterministici che stocastici.
Svantaggi della simulazione Monte Carlo
- A volte ci vuole molto tempo, poiché dobbiamo generare un gran numero di campioni per ottenere il risultato soddisfacente desiderato.
- I risultati ottenuti con questo metodo sono solo l'approssimazione della risposta vera e non la risposta esatta.
Circa l'autore
Dinesh di soia Junjariya, uno studente Btech di IIT Jodhpur.
Per qualsiasi suggerimento, commenta qui sotto.
Il supporto mostrato in questo post non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





