Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati
Panoramica
Questo articolo discuterà brevemente della CNN, una variante speciale delle reti neurali progettate specificamente per compiti relativi alle immagini. L'articolo si concentrerà principalmente sulla parte di implementazione della CNN. È stato fatto ogni sforzo per rendere questo articolo interattivo e semplice.. Spero che ti piaccia Buon apprendimento !!

introduzione
Le reti neurali convoluzionali sono state introdotte da Yann LeCun e Yoshua Bengio nell'anno 1995 che in seguito ha dimostrato di mostrare risultati eccezionali nel dominio delle immagini. Quindi, Cosa le rendeva speciali rispetto alle normali reti neurali quando applicate nel dominio dell'immagine?? Spiegherò uno dei motivi con un semplice esempio. Nota che ti è stato assegnato il compito di ordinare le immagini delle cifre scritte a mano e che di seguito sono riportati alcuni esempi di set di addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina.....

Se osservi correttamente, potresti scoprire che tutte le cifre appaiono al centro delle rispettive immagini. Allena un neuronale rossoLe reti neurali sono modelli computazionali ispirati al funzionamento del cervello umano. Usano strutture note come neuroni artificiali per elaborare e apprendere dai dati. Queste reti sono fondamentali nel campo dell'intelligenza artificiale, consentendo progressi significativi in attività come il riconoscimento delle immagini, Elaborazione del linguaggio naturale e previsione delle serie temporali, tra gli altri. La loro capacità di apprendere schemi complessi li rende strumenti potenti.. La normalità con queste immagini può dare un buon risultato se l'immagine di prova è di tipo simile. Ma, Cosa succede se l'immagine di prova è come sotto??

Qui il numero nove appare nell'angolo dell'immagine. Se usiamo un semplice modello di rete neurale per classificare questa immagine, il nostro modello potrebbe fallire improvvisamente. Ma se la stessa immagine di prova viene data a un modello della CNN, è molto probabile che venga classificato correttamente. Il motivo delle prestazioni migliori è che cerca le caratteristiche spaziali nell'immagine. Per il caso di cui sopra stesso, anche se il numero nove è nell'angolo sinistro della cornice, il modello CNN addestrato cattura le caratteristiche nell'immagine e probabilmente prevede che il numero sia la cifra nove. Una normale rete neurale non può fare questo tipo di magia. Ora discutiamo brevemente i principali elementi costitutivi della CNN.
Componenti principali dell'architettura di un modello CNN
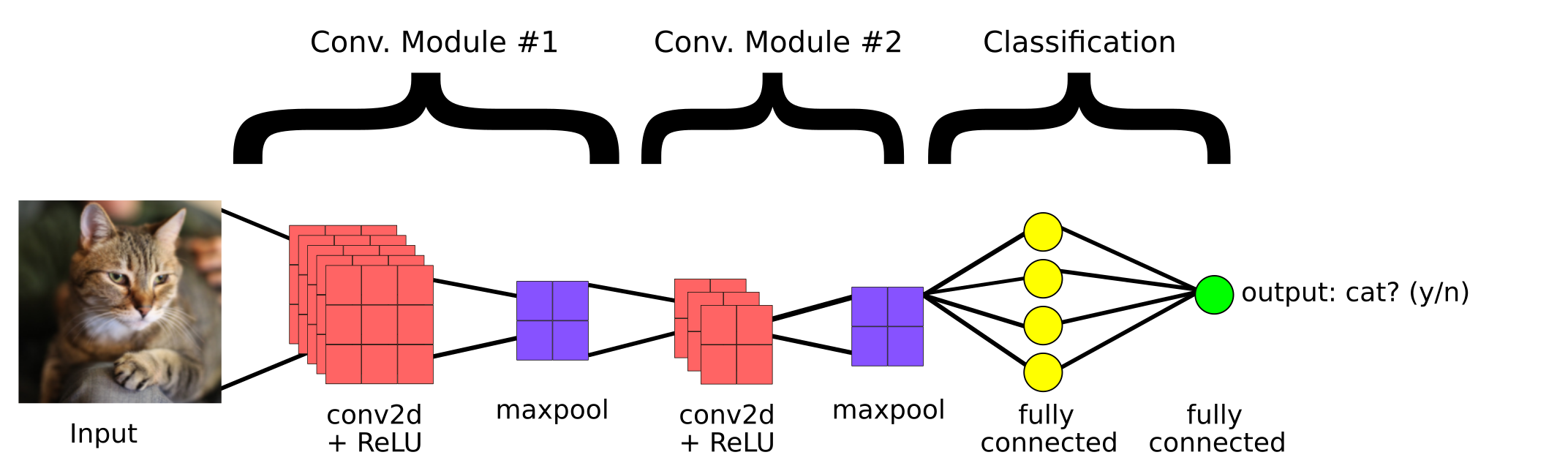
Questo è un semplice modello CNN creato per classificare se l'immagine contiene o meno un gatto. Quindi, i componenti principali di una CNN sono:
1. copertina convolutivaIl livello convoluzionale, Fondamentale nelle reti neurali convoluzionali (CNN), Viene utilizzato principalmente per l'elaborazione dei dati con strutture a griglia, come immagini. Questo livello applica filtri che estraggono le caratteristiche rilevanti, come bordi e trame, Consentire al modello di riconoscere modelli complessi. La sua capacità di ridurre la dimensionalità dei dati e di mantenere le informazioni essenziali lo rende uno strumento chiave nelle attività di visione artificiale..
2. Livello di raggruppamento
3.Strato completamente connesso
copertina convolutiva
I livelli convolutivi ci aiutano a estrarre le caratteristiche presenti nell'immagine. Questa estrazione si ottiene con l'ausilio di filtri. Osservare la seguente operazione.
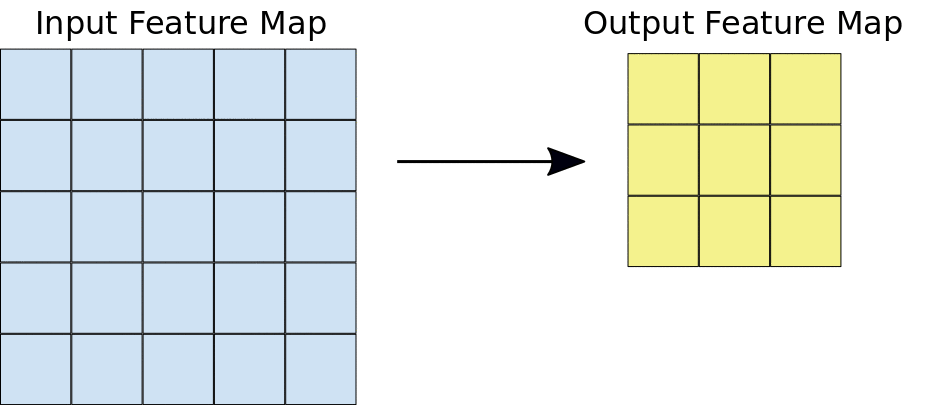
Qui possiamo vedere che una finestra scorre sull'intera immagine in cui l'immagine viene visualizzata come una griglia (Questo è il modo in cui il computer vede le immagini in cui le griglie sono piene di numeri!!). Ora vediamo come vengono eseguiti i calcoli nell'operazione di convoluzione.
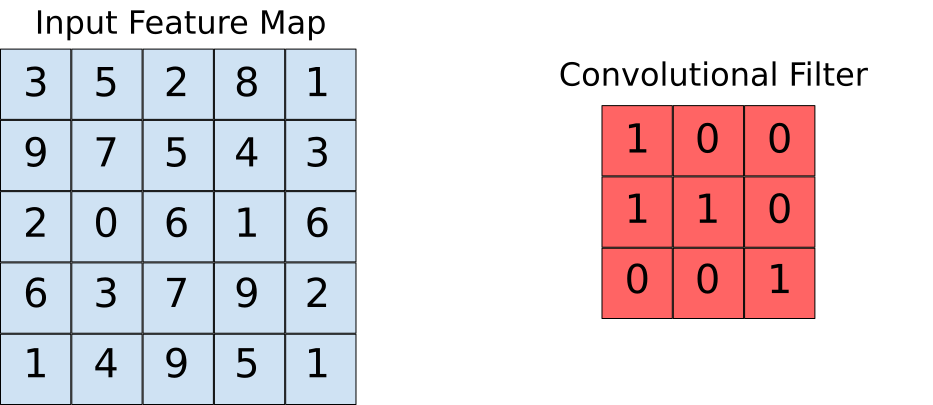
Supponiamo che la mappa delle caratteristiche di input sia la nostra immagine e che il filtro convoluzionale sia la finestra su cui andremo a scorrere. Ora diamo un'occhiata a una delle istanze dell'operazione di convoluzione.
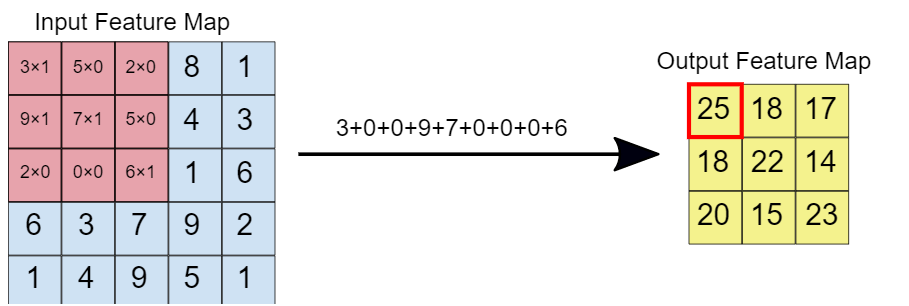
Quando il filtro di convoluzione è sovrapposto all'immagine, i rispettivi elementi sono moltiplicati. Dopo, i valori moltiplicati vengono aggiunti per ottenere un singolo valore che viene popolato sulla mappa delle caratteristiche di output. Questa operazione continua finché non facciamo scorrere la finestra sulla mappa delle caratteristiche di input., riempiendo così la mappa delle caratteristiche di output.
Livello di raggruppamento
L'idea alla base dell'utilizzo di un livello di raggruppamento è quella di ridurre il dimensione"Dimensione" È un termine che viene utilizzato in varie discipline, come la fisica, Matematica e filosofia. Si riferisce alla misura in cui un oggetto o un fenomeno può essere analizzato o descritto. In fisica, ad esempio, Si parla di dimensioni spaziali e temporali, mentre in matematica può riferirsi al numero di coordinate necessarie per rappresentare uno spazio. Comprenderlo è fondamentale per lo studio e... della mappa delle funzioni. Per la rappresentazione fornita di seguito, abbiamo utilizzato un livello di raggruppamento massimo di 2 * 2. Ogni volta che la finestra scorre sull'immagine, prendiamo il valore massimo presente all'interno della finestra.
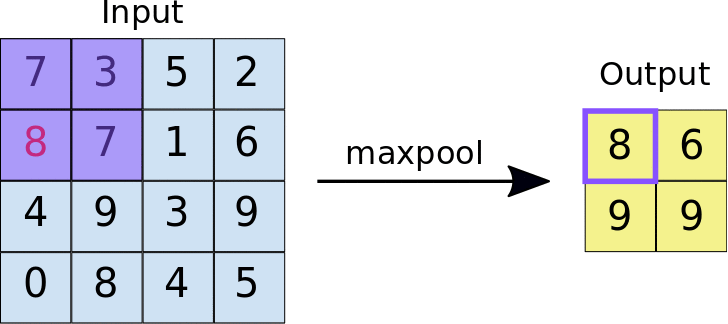
Finalmente, dopo il massimo funzionamento del gruppo, possiamo vedere qui che la dimensione dell'input, vale a dire, 4 * 4, è stato ridotto a 2 * 2.
Strato completamente connesso
Questo livello è presente nella sezione di coda dell'architettura del modello CNN come visto prima. L'input al livello completamente connesso sono le ricche funzionalità che sono state estratte dai filtri convoluzionali. Questo poi si propaga in avanti al Livello di outputIl "Livello di output" è un concetto utilizzato nel campo della tecnologia dell'informazione e della progettazione di sistemi. Si riferisce all'ultimo livello di un modello o di un'architettura software che è responsabile della presentazione dei risultati all'utente finale. Questo livello è fondamentale per l'esperienza dell'utente, poiché consente l'interazione diretta con il sistema e la visualizzazione dei dati elaborati...., dove otteniamo la probabilità che l'immagine in ingresso appartenga a classi diverse. Il risultato previsto è la classe con la più alta probabilità prevista dal modello.
Implementazione del codice
Qui prendiamo il Fashion MNIST come il nostro set di dati problematico. Il set di dati contiene magliette, pantaloni, maglione, vestiti, cappotti, infradito, camicie, scarpe, borse e stivaletti. Il compito è classificare una certa immagine nelle classi di cui sopra dopo aver addestrato il modello.
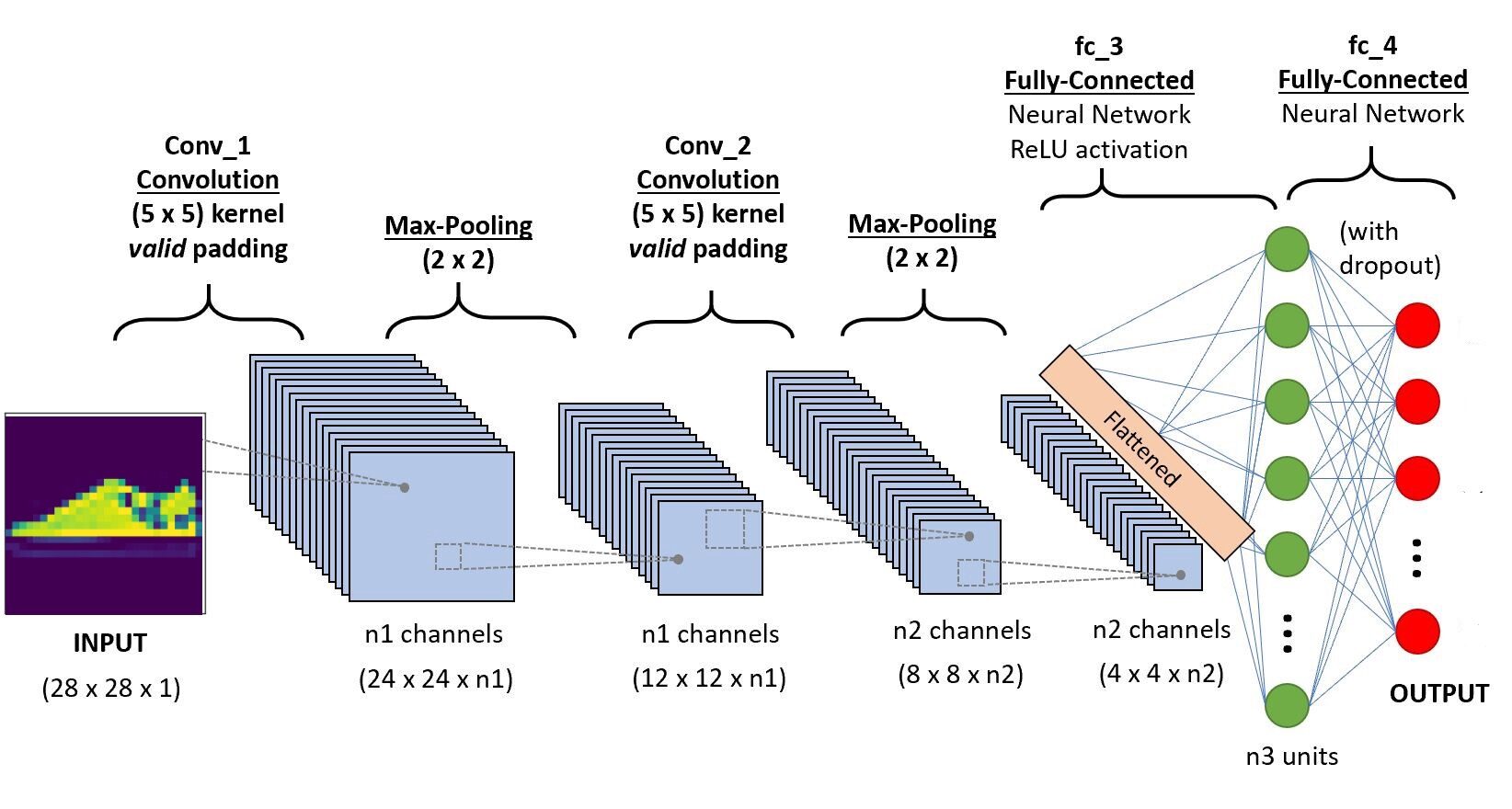
Implementeremo il codice in Google Colab, in quanto forniscono l'uso di risorse GPU gratuite per un periodo di tempo fisso. Se non conosci l'ambiente Colab e le GPU, controlla questo blog per farti un'idea migliore. Di seguito è riportata l'architettura della CNN che andremo a costruire.
passo 1: Importa le librerie richieste
importare il sistema operativo importare la torcia importare torchvision importa file tar da torchvision import trasforma da torch.utils.data import random_split da torch.utils.data.dataloader import DataLoader import torcia.nn come nn da torch.nn import funzionale come F dalla catena di importazione di itertools
passo -2: Download del set di dati di test e training
train_set = torchvision.datasets.FashionMNIST("/usr", download=Vero, trasformare=
trasforma.Componi([trasforma.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./dati", download=Vero, treno=falso, trasformare=
trasforma.Componi([trasforma.ToTensor()]))
passo 3 Divisione del training set per la formazione e la validazione
train_size = 48000 val_size = 60000 - train_size train_ds,val_ds = random_split(train_set,[train_size,val_size])
passo 4 Carica il set di dati in memoria utilizzando Dataloader
train_dl = DataLoader(train_ds,batch_size=20,shuffle=Vero) val_dl = DataLoader(val_ds,batch_size=20,shuffle=Vero) classi = train_set.classes
Ora visualizziamo i dati caricati,
per imgs,etichette in train_dl:
per img in imgs:
arr_ = np.squeeze(img)
plt.mostra()
rottura
rottura
passo -5 Definire l'architettura
import torcia.nn come nn
import torcia.nn.funzionale come F
#definire l'architettura della CNN
classe Net(nn.Modulo):
def __init__(se stesso):
super(Netto, se stesso).__dentro__()
#strato convolutivo-1
self.conv1 = nn.Conv2d(1,6,5, imbottitura=0)
#strato convolutivo-2
self.conv2 = nn.Conv2d(6,10,5,imbottitura=0)
# livello di raggruppamento massimo
self.pool = nn.MaxPool2d(2, 2)
# Strato completamente connesso 1
self.ff1 = nn.Lineare(4*4*10,56)
# Strato completamente connesso 2
self.ff2 = nn.Lineare(56,10)
def avanti(se stesso, X):
# aggiunta di una sequenza di livelli convoluzionali e massimi di pooling
#ingresso dim-28*28*1
x = self.conv1(X)
# Dopo l'operazione di convoluzione, output_dim - 24*24*6
x = self.pool(X)
# Dopo il massimo funzionamento in piscina, l'uscita dim - 12*12*6
x = self.conv2(X)
# Dopo l'operazione di convoluzione uscita dim - 8*8*10
x = self.pool(X)
# uscita max piscina dim 4*4*10
x = x.vista(-1,4*4*10) # Rimodellare i valori in una forma appropriata all'input del livello completamente connesso
x = F.relu(self.ff1(X)) # Applicazione di Relu all'output del primo strato
x = F.sigmoide(self.ff2(X)) # Applicazione di sigmoid all'output del secondo strato
restituire x
# creare una CNN . completa model_scratch = Net() Stampa(modello)
# sposta i tensori su GPU se CUDA è disponibile
if use_cuda:
model_scratch.cuda()
passo 6: Definizione del Funzione di perditaLa funzione di perdita è uno strumento fondamentale nell'apprendimento automatico che quantifica la discrepanza tra le previsioni del modello e i valori effettivi. Il suo obiettivo è quello di guidare il processo di formazione minimizzando questa differenza, consentendo così al modello di apprendere in modo più efficace. Esistono diversi tipi di funzioni di perdita, come l'errore quadratico medio e l'entropia incrociata, ognuno adatto a compiti diversi e...
# Funzione di perdita
import torcia.nn come nn
importa torch.optim come optim
criterio_scratch = nn.CrossEntropyLoss()
def get_optimizer_scratch(modello):
ottimizzatore = optim.SGD(parametri.modello(),lr = 0.04)
ottimizzatore di ritorno
passo 7: implementazione dell'algoritmo di addestramento e convalida
# Implementazione dell'algoritmo di addestramento
def treno(n_epoche, caricatori, modello, ottimizzatore, criterio, use_cuda, save_path):
"""restituisce il modello addestrato"""
# inizializza il tracker per una perdita di convalida minima
valid_loss_min = np.Inf
per epoca in gamma(1, n_epoche+1):
# inizializzare le variabili per monitorare la perdita di addestramento e convalida
train_loss = 0.0
valid_loss = 0.0
# fase del treno #
# impostare il modulo in modalità allenamento
modello.treno()
per batch_idx, (dati, obbiettivo) in enumerare(caricatori['treno']):
# passa alla GPU
if use_cuda:
dati, target = data.cuda(), target.cuda()
ottimizzatore.zero_grad()
uscita = modello(dati)
perdita = criterio(produzione, obbiettivo)
perdita.indietro()
ottimizzatore.passo()
train_loss = train_loss + ((1 / (batch_idx + 1)) * (perdita.dati.elemento() - perdita del treno))
# convalidare il modello #
# impostare il modello in modalità di valutazione
model.eval()
per batch_idx, (dati, obbiettivo) in enumerare(caricatori['valido']):
# passa alla GPU
if use_cuda:
dati, target = data.cuda(), target.cuda()
uscita = modello(dati)
perdita = criterio(produzione, obbiettivo)
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (perdita.dati.elemento() - valid_loss))
# stampa statistiche di addestramento/convalida
Stampa('Epoca: {} tPerdita di allenamento: {:.6F} tPerdita di convalida: {:.6F}'.formato(
epoca,
perdita del treno,
valid_loss
))
## Se la perdita di valutazione è diminuita, quindi salvare il modello
se valid_loss <= valid_loss_min:
Stampa('Perdita di convalida diminuita ({:.6F} --> {:.6F}). Salvataggio del modello ...'.format(
valid_loss_min,
valid_loss))
torcia.salva(model.state_dict(), save_path)
valid_loss_min = valid_loss
modello di ritorno
passo 8: Fase di formazione e valutazione
num_epoche = 15
model_scratch = treno(num_epoche, loaders_scratch, model_scratch, get_optimizer_scratch(model_scratch),
criterio_gratta, use_cuda, 'model_scratch.pt')
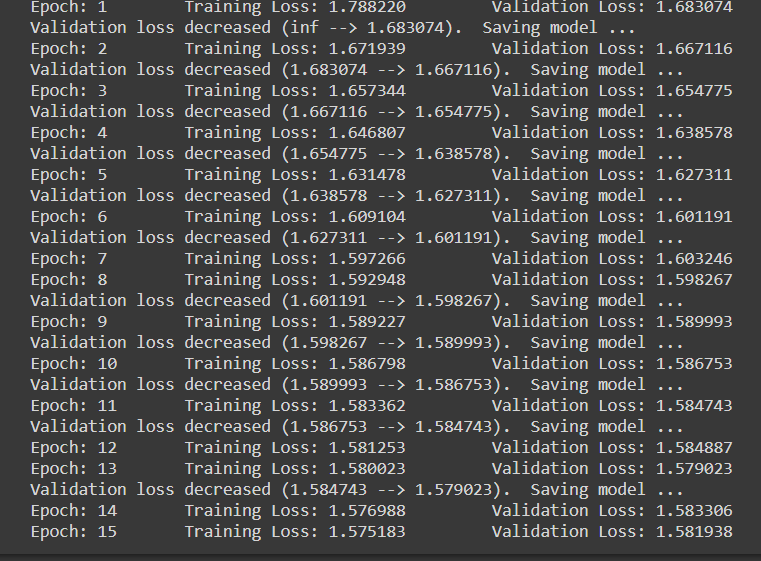
Nota che quando ogni volta la perdita di convalida diminuisce, stiamo salvando lo stato del modello.
passo 9 Fase di prova
def test(caricatori, modello, criterio, use_cuda):
# monitorare la perdita e l'accuratezza del test
test_loss = 0.
corretto = 0.
totale = 0.
# impostare il modulo in modalità di valutazione
model.eval()
per batch_idx, (dati, obbiettivo) in enumerare(caricatori['test']):
# passa alla GPU
if use_cuda:
dati, target = data.cuda(), target.cuda()
# passaggio in avanti: calcolare gli output previsti passando gli input al modello
uscita = modello(dati)
# calcolare la perdita
perdita = criterio(produzione, obbiettivo)
# aggiorna la perdita media del test
test_loss = test_loss + ((1 / (batch_idx + 1)) * (perdita.dati.elemento() - test_loss))
# convertire le probabilità di output in classe prevista
pred = output.data.max(1, keepdim=Vero)[1]
# confronta le previsioni con l'etichetta vera
corretto += np.somma(np.squeeze(pred.eq(target.data.view_as(pred)),asse=1).processore().insensibile())
totale += data.size(0)
Stampa("Perdita di prova": {:.6F}n'.formato(test_loss))
Stampa('nTest Precisione: %2D%% (%2d /% 2d)' % (
100. * corretta / totale, corretta, totale))
# caricare il modello che ha ottenuto la migliore accuratezza di convalida
model_scratch.load_state_dict(torcia.carico('model_scratch.pt'))
test(loaders_scratch, model_scratch, criterio_gratta, use_cuda)

passo 10 Prova con un campione
La funzione definita per testare il modello con una singola immagine.
def previsione_immagine(img, modello):
# Converti in un lotto di 1
xb = img.unsqueeze(0)
# Ottieni previsioni dal modello
yb = modello(xb)
# Scegli l'indice con la più alta probabilità
_, pred = torcia.max(yb, dim=1)
# stampare l'immagine
plt.imshow(img.squeeze( ))
#restituendo l'etichetta della classe relativa all'immagine
return train_set.classes[pred[0].articolo()]
img,etichetta = set_test[9] forecast_image(img,model_scratch)
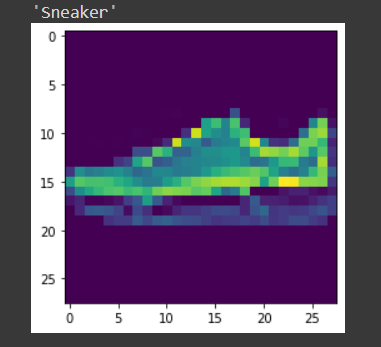
conclusione
Qui abbiamo brevemente discusso le principali operazioni in un convolucional neuronale rossoReti neurali convoluzionali (CNN) sono un tipo di architettura di rete neurale progettata appositamente per l'elaborazione dei dati con una struttura a griglia, come immagini. Usano i livelli di convoluzione per estrarre le caratteristiche gerarchiche, il che li rende particolarmente efficaci nelle attività di riconoscimento e classificazione dei modelli. Grazie alla sua capacità di apprendere da grandi volumi di dati, Le CNN hanno rivoluzionato campi come la visione artificiale.. e la sua architettura. È stato anche implementato un semplice modello di rete neurale convoluzionale per dare una migliore idea del caso d'uso pratico. Puoi trovare il codice implementato in my Archivio GitHub. Cosa c'è di più, puoi migliorare le prestazioni del modello distribuito aumentando il set di dati, Utilizzando regolarizzazioneLa regolarizzazione è un processo amministrativo che cerca di formalizzare la situazione di persone o entità che operano al di fuori del quadro giuridico. Questa procedura è essenziale per garantire diritti e doveri, nonché a promuovere l'inclusione sociale ed economica. In molti paesi, La regolarizzazione viene applicata in contesti migratori, Lavoro e fiscalità, consentire a chi si trova in situazione irregolare di accedere ai benefici e tutelarsi da possibili sanzioni.... come il standardizzazioneLa standardizzazione è un processo fondamentale in diverse discipline, che mira a stabilire norme e criteri uniformi per migliorare la qualità e l'efficienza. In contesti come l'ingegneria, Istruzione e amministrazione, La standardizzazione facilita il confronto, Interoperabilità e comprensione reciproca. Nell'attuazione degli standard, si promuove la coesione e si ottimizzano le risorse, che contribuisce allo sviluppo sostenibile e al miglioramento continuo dei processi.... e l'abbandono a livelli completamente connessi dell'architettura. Cosa c'è di più, nota che sono disponibili anche modelli CNN pre-addestrati, che sono stati formati utilizzando grandi set di dati. Utilizzando questi modelli di ultima generazione, otterrai senza dubbio i migliori punteggi di metrica per un determinato problema.
Riferimenti
- https://www.youtube.com/watch?v = EHuACSjijbI – gioviano
- https://www.youtube.com/watch?v = 2-Ol7ZB0MmU&t=1503s- Un'introduzione amichevole alle reti neurali convoluzionali e al riconoscimento delle immagini
Circa l'autore
Mi chiamo Adwait Datan, Attualmente sto perseguendo la mia laurea magistrale in Intelligenza Artificiale e Data Science. Sentiti libero di connetterti con me attraverso Linkedin.
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





