Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
Gli obiettivi principali della convalida di un modello includono la verifica della solidità concettuale del modello e della continua aderenza allo scopo., compresa l'identificazione di potenziali rischi e limitazioni. Questi test devono costituire una sfida efficace al modello produttivo esistente a vantaggio del suo miglioramento., mitigazione del rischio. I dati per questo esercizio sono presi da qui.
Quadro di convalida
I seguenti test sono stati eseguiti per convalidare i risultati del modello:
- Variabili del modello: IV, linearità e VIF
- 3. Vestibilità del modello: Grafica AUROC, Gini, KS e guadagno e sollevamento
- 4. Test del modello: analisi di sensibilità
- 5. Coefficiente di stabilità: stabilità del segnale e stabilità del coefficiente
2.1 Controlli dei dati
Variabili dipendenti
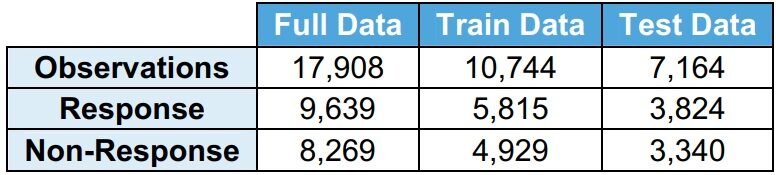
Si osserva che la distribuzione della risposta (Y = 1) e nessuna risposta (Y = 0) è molto simile tra i dati completi, dati del treno e dati dei test.
· La risposta (Y = 1) indica che il richiedente ha richiesto il prestito
· senza risposta (Y = 0) indica che il richiedente non ha richiesto il prestito
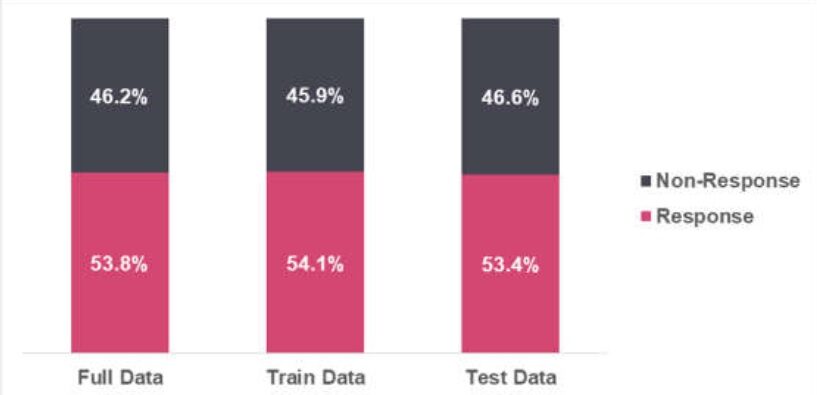
Variabili indipendenti
Le variabili indipendenti includono informazioni personali e finanziarie. I punteggi di rischio vengono utilizzati per sviluppare il modello. Ci sono 5 variabili indipendenti nel modello.
Si osserva che non ci sono valori mancanti nel set di dati del treno.
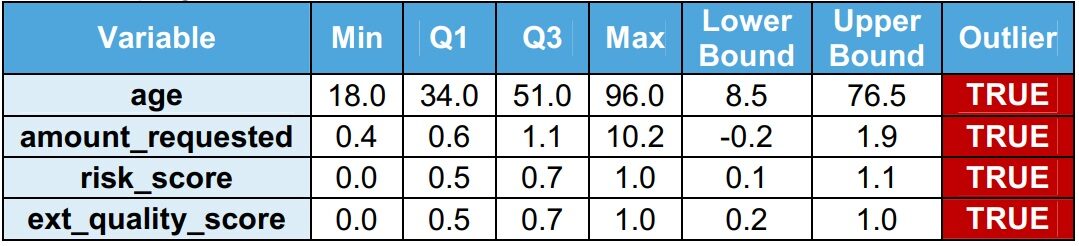
Si osserva che ci sono valori anomali nel set di dati del treno. L'intervallo tra i quartili (IQR = Q3 – Q1) serve per identificare i punti vendita. I valori anomali sono valori superiori al limite superiore (Q1 + 1,5 x IQR) o valori inferiori al limite inferiore (Q1 – 1,5 x IQR). Il team di validazione raccomanda di affrontare gli outlier prima di sviluppare il modello.
2.2. Variabili del modello
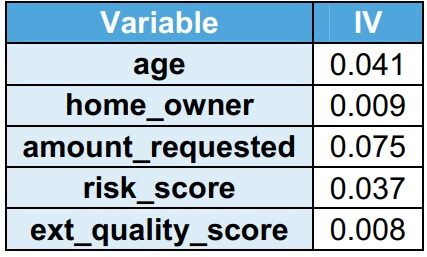
Valore delle informazioni (IV)
da statsmodels.stats.outliers_influence import variance_inflation_factor
Il potere esplicativo di variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... viene catturato da IV. UN misuraIl "misura" È un concetto fondamentale in diverse discipline, che si riferisce al processo di quantificazione delle caratteristiche o delle grandezze degli oggetti, fenomeni o situazioni. In matematica, Utilizzato per determinare le lunghezze, Aree e volumi, mentre nelle scienze sociali può riferirsi alla valutazione di variabili qualitative e quantitative. L'accuratezza della misurazione è fondamentale per ottenere risultati affidabili e validi in qualsiasi ricerca o applicazione pratica.... che aumenta il potere esplicativo della variabile, aumenta IV. Si osserva che tutte le variabili hanno IV <0.1, indicando che hanno un basso potere esplicativo nel set di dati del treno.
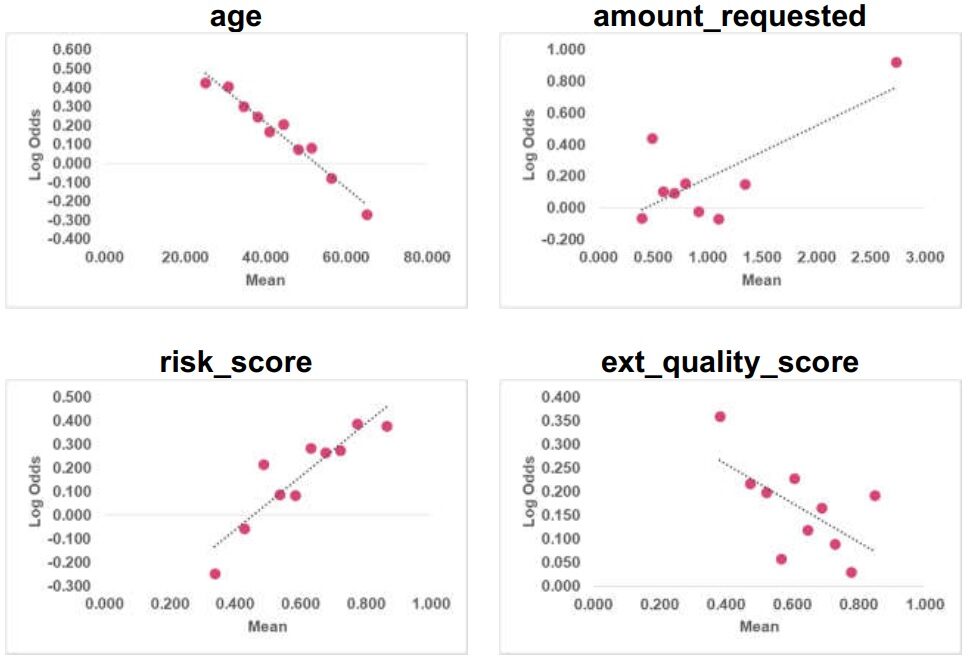
Linearità
passo 1: fare 10 contenitori per ogni variabile numerica
passo 2: per ogni intervallo, calcolare la media della variabile e le corrispondenti probabilità logaritmiche
Viene verificata la linearità delle variabili numeriche (età, importo richiesto, punteggio_rischio e punteggio_qualità_ ext) nei dati del treno. si osserva che agisce & risk_score figlio lineales y quantità_richiesta & ext_quality_score no son lineales. Il team di validazione raccomanda di testare le trasformazioni per ottenere una relazione lineare.
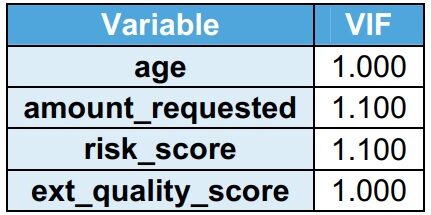
Fattore di informazione sulla varianza (VIVACE)
VIF indica la multicollinearità tra variabili indipendenti. Si osserva che il suo VIF è inferiore a 2 Nel addestramentoLa formazione è un processo sistematico volto a migliorare le competenze, conoscenze o abilità fisiche. Viene applicato in vari ambiti, come lo sport, Formazione e sviluppo professionale. Un programma di allenamento efficace include la pianificazione degli obiettivi, Pratica regolare e valutazione dei progressi. L'adattamento alle esigenze individuali e la motivazione sono fattori chiave per ottenere risultati di successo e sostenibili in qualsiasi disciplina..... VIF inferiore a 2 non indica multicollinearità. Il proprietario di casa è una bandiera, così, non considerato per VIF.
2.3 Vestibilità del modello
AU-ROC
sklearn.metrics.auc(X, e)
L'area sotto la curva dell'operatore del ricevitore (AUROCO) viene utilizzato per misurare il potere predittivo del modello. AURO = 0,50 indica che non c'è potere predittivo e AUROC = 1,00 indica un potere predittivo perfetto. Il modello sviluppato con i dati del treno viene eseguito con i dati di prova e i dati completi. Si osserva che non vi è alcuna deviazione significativa nei valori AUROC.
Si osserva che AUROC è inferiore a 0,6. Ciò indica che il modello non ha un buon potere predittivo.. Il team di convalida consiglia di utilizzare variabili aggiuntive per migliorare l'adattamento del modello..

Gini
Formula: Gini = 2 x AURO – 1
Gini se deriva de AUROC. Gini = 0.0 indica che non c'è potere predittivo e Gini = 1.0 indica un potere predittivo perfetto. Il modello sviluppato con i dati del treno viene eseguito con i dati di prova e i dati completi. Si osserva che non vi è alcuna deviazione significativa nei valori di Gini.

Kansas
scipy.stats.ks_2samp
Il test di Kolmogorov-Smirnov (KS) misura la separazione tra la % cumulata di eventi e la % cumulata di nessun evento. Si osserva che le statistiche dei test KS sono inferiori a 40, che indica che il modello non è in grado di separare eventi e non eventi.

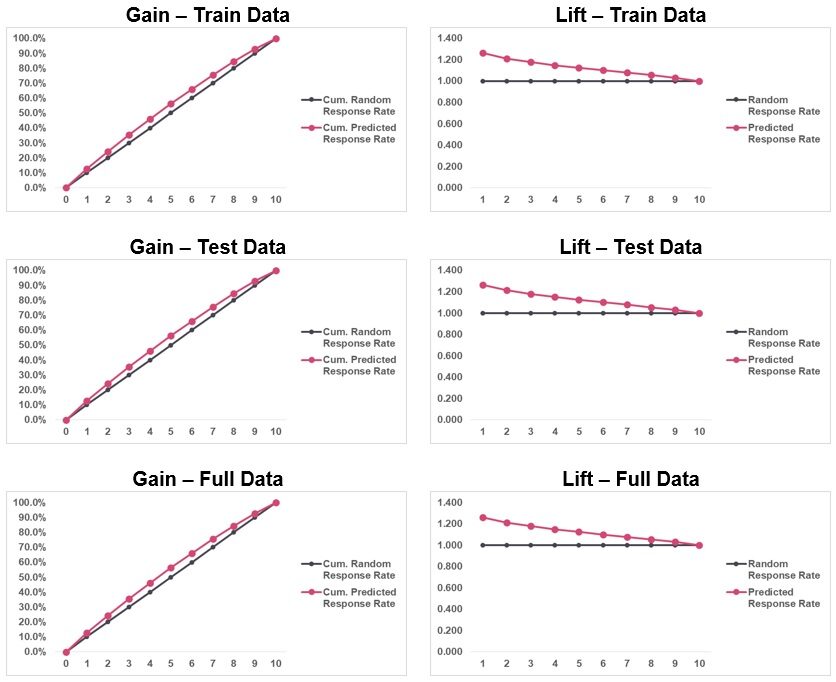
Grafici di guadagno ed elevazione
passo 1: Calcola la probabilità di ogni osservazione.
passo 2: Classifica queste probabilità in ordine decrescente.
passo 3: Costruisci decili con ogni gruppo che ha quasi il 10% delle osservazioni.
passo 4: Calcola il tasso di risposta in ogni decile per Good (risponditori), Un po (non rispondenti) e totale.
I grafici di guadagno ed elevazione sono strumenti di visualizzazione dei dati che confrontano la capacità del classificatore di acquisire il tasso di risposta. Si osserva che il tasso di risposta cumulativo previsto è molto vicino al tasso di risposta casuale cumulativo. Indica che il modello ha un basso potere predittivo. Il team di convalida consiglia di utilizzare variabili aggiuntive per migliorare l'adattamento del modello..
2.4 Test del modello
Analisi di sensibilità
passo 1: normalizza tutte le variabili
passo 2: eseguire la regressione logistica tra la variabile dipendente e la prima
passo 3: eseguire la regressione logistica tra la variabile dipendente e la seconda
passo 4: ripetere il passaggio precedente per il resto delle variabili
passo 5: il coefficiente della variabile indica la sensibilità tra la variabile e le probabilità logaritmiche della variabile dipendente
Viene testata la sensibilità del modello rispetto alle variabili numeriche indipendenti. La sensibilità viene verificata sui dati del treno. L'obiettivo di questo esercizio è identificare le variabili più sensibili. Si osserva che età e risk_score sono le variabili più sensibili e ext_quality_score è la variabile meno sensibile.

2.5. Coefficiente di stabilità
Coefficiente di stabilità
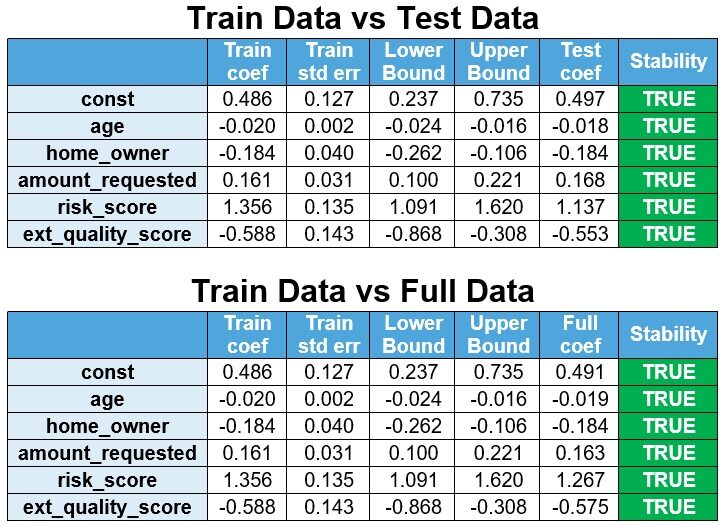
Il modello viene ricalcolato dai dati di prova e i dati completi e i coefficienti vengono confrontati con i dati del treno. Se i coefficienti del modello ristimato sono all'interno dell'intervallo di confidenza del 95% (Coefficiente treno ± 1,96 x Err standard di tendenza), allora i coefficienti sono stabili.
Il limite inferiore è definito come Train Coef – 1,96 x Err std del treno e il limite superiore è definito come Coef del treno + 1,96 x Err standard di tendenza. Si osserva che i coefficienti sono stabili.
Stabilità del segnale
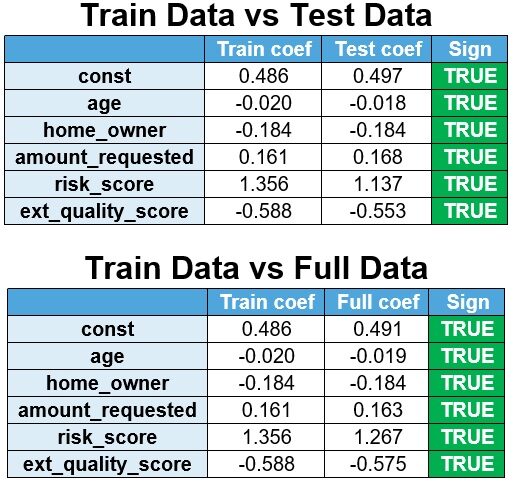
Il modello viene ricalcolato dai dati di prova e i dati completi e i coefficienti vengono confrontati con i dati del treno.
Si osserva che i segni sono stabili.
conclusione
La convalida ha rilevato che il modello è stabile. tuttavia, sono stati sollevati tre risultati gravi:
· trovare 1 (dati in ingresso) – Si osserva che ci sono valori anomali nel set di dati del treno. Il team di validazione raccomanda di affrontare gli outlier prima di sviluppare il modello.
· trovare 2 (dati in ingresso) – Nota che importo_richiesta & ext_quality_score no son lineales. Il team di validazione raccomanda di testare le trasformazioni per ottenere una relazione lineare.
· Risultato 3 (vestibilità del modello) – Si osserva che AUROC è basso, Gini è basso e KS è basso, che indica che il modello non è in grado di separare eventi e non eventi. Il team di convalida consiglia di utilizzare variabili aggiuntive per migliorare l'adattamento del modello..
Il supporto mostrato in questo articolo non è di proprietà di DataPeaker e viene utilizzato a discrezione dell'autore.





