introduzione
Lo stacking è una tecnica di apprendimento di insieme che utilizza le previsioni per più nodi (ad esempio, kNN, alberi decisionali o SVM) per costruire un nuovo modello. Questo modello finale viene utilizzato per fare previsioni sul set di dati del test..
***Video***
Nota: Se sei più interessato ad apprendere concetti in un formato audiovisivo, abbiamo questo articolo completo spiegato nel video qui sotto. Se non è così, puoi continuare a leggere.
Quindi, ciò che facciamo durante l'impilamento è prendere i dati di addestramento ed eseguirli attraverso più modelli, M1 a Mn. E tutti questi modelli sono normalmente conosciuti come studenti di base o modelli di base.. E generiamo previsioni da questi modelli.
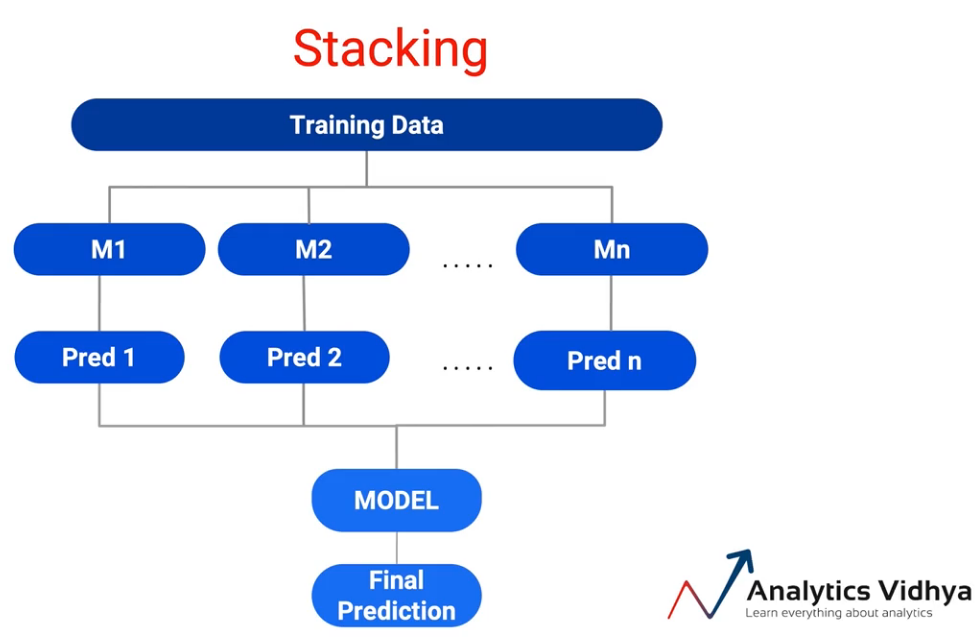
Perciò, Precedente 1 a Pred n sono le previsioni, e questo input viene inviato al modello, invece del voto massimo o medio. E il modello li prende come input e ci dà la previsione finale. E a seconda che si trattasse di un problema di regressione o di un problema di classificazione, posso scegliere quale è il modello corretto per farlo. Quindi, il concetto di impilamento è molto interessante e apre molte possibilità.
Ma impilare in questo modo apre un grande pericolo di Sovra-regolazione il modello perché sto usando tutti i miei dati di addestramento per creare il modello e anche per creare previsioni su di esso.
Quindi, la domanda è, Posso diventare più intelligente e posso utilizzare i dati di allenamento e i dati di test in un modo diverso per ridurre il pericolo di sovradattamento?? Ed è di questo che parleremo in questo particolare articolo.. Quindi, quello che tratterò è uno dei modi più popolari in cui viene utilizzato l'impilamento.
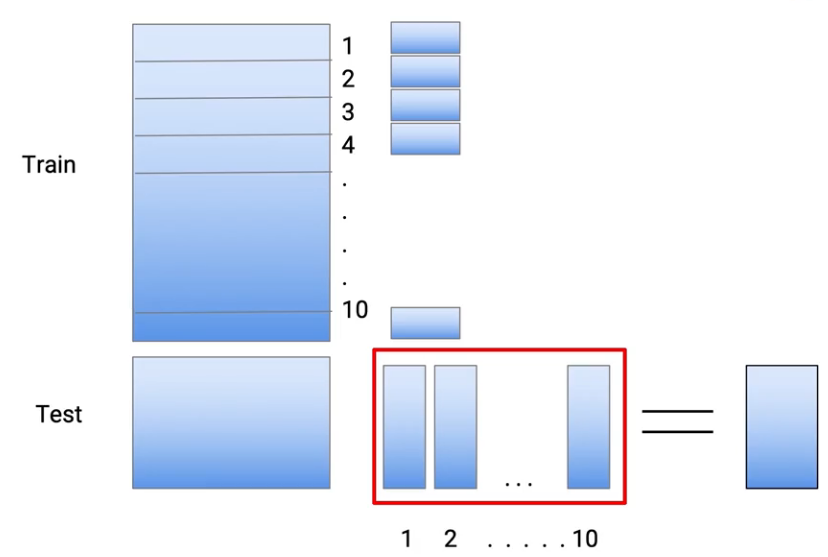
Diciamo che abbiamo questi set di dati di addestramento e test:
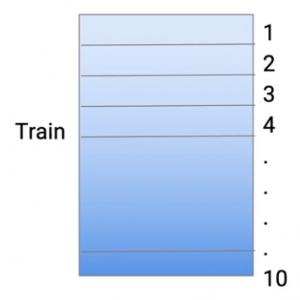
E per ridurre il sovradattamento, Prendo i dati dal mio treno e li divido in 10 parti. Quindi questo è fatto a caso. Quindi prendo l'intero set di dati dal treno e lo trasformo in 10 set di dati più piccoli.
E adesso, per ridurre il sovradattamento, quello che faccio è addestrare il mio modello in 9 di questo 10 parti e faccio le mie previsioni nella decima parte. Quindi, in questo caso particolare, Faccio la mia parte allenandomi 2 alla parte 10. E diciamo che sto usando l'albero decisionale come tecniche di modellazione, quindi alleno il mio modello e faccio i miei casi di previsione, chi c'era nella parte 1-
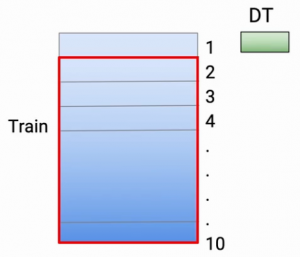
Quindi, la parte 1 è fondamentalmente una previsione. Quindi, il colore verde rappresenta la previsione, cosa ho fatto nei punti, che erano nel set di dati 1, Faccio lo stesso esercizio per ognuna di queste parti. Quindi, per la parte 2, Riaddestrare il mio modello usando la parte 1 dati e parte 3 alla parte 10 di dati. E faccio le mie previsioni nella seconda parte.
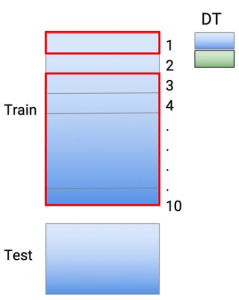
Quindi, in questo modo, Faccio le mie previsioni per tutti questi 10 parti. Quindi, In sintesi, ognuna di queste previsioni proveniva da un modello che non aveva visto gli stessi punti dati del treno. E per creare un set di dati di prova, Uso tutti i dati del treno. Così, ancora, alleno la modella, eseguita sull'intero set di dati del treno, e faccio previsioni nel test.
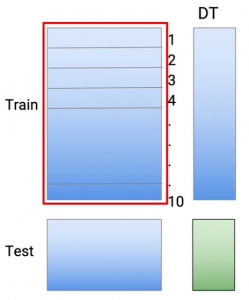
Quindi, se ci pensi, noi creiamo 10 modelli per ottenere previsioni sui dati del treno e l'undicesimo modello per ottenere previsioni sui dati di prova. E questi sono tutti modelli di albero decisionale. Quindi, questo mi dà una serie di previsioni o l'equivalente delle previsioni provenienti dal modello M1.
Faccio lo stesso con una seconda tecnica di modellazione. diciamo KNN. Quindi, ancora, lo stesso concetto che faccio le previsioni parte per parte 1 alla parte 10. E di nuovo, per ottenere previsioni sul set di dati del test, Corro l'undicesimo modello KNN.
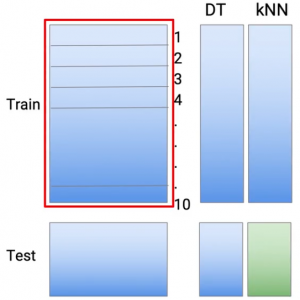
Faccio lo stesso con la terza parte, che potrebbe essere una regressione lineare o logistica, a seconda del tipo di problema che stai gestendo.
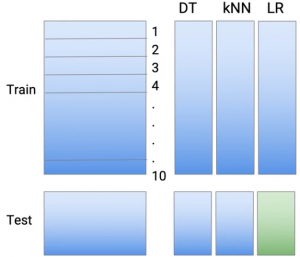
Quindi, questi sono i miei nuovi studenti di base in qualche modo. Ora ho previsioni di tre diversi tipi di tecniche di modellazione, ma ho evitato il pericolo di sovradattamento.
Ora potrei chiedere, Perché sto usando? 10? E cosa c'è di sacrosanto in questo numero 10? Quindi non c'è nulla di sacrosanto nel numero 10. Si basa sul fatto che se uso qualcosa in meno di due o tre, non mi dà molto beneficio. E se prendo qualcosa in più che dire 15 oh 20, quindi il mio numero di calcoli aumenta. Quindi solo un compromesso tra ridurre il sovradattamento e non aumentare molto la mia complessità. Puoi anche andare avanti con 7 tu 8, non c'è niente di specifico con cui hai a che fare 10.
Quindi sentiti libero di scegliere il tuo numero. Potrebbero essere sette, potrebbero essere otto, ma di solito vedo persone che usano tra cinque e forse 11, 12, dipende dalla situazione. E vedrai questo ancora e ancora insieme che ci sono linee guida, ma alla fine della giornata, devi prendere decisioni in base a quante risorse hai, quanta complessità c'è e quali sono le tue linee guida di produzione e cosa puoi permetterti in produzione?
Quindi ho preso 10 come esempio, ma puoi anche usare qualsiasi altro numero. Re-impilamento. Quindi abbiamo avuto queste previsioni da tre diversi tipi di modelli. Quindi questo diventa il mio nuovo set di dati del treno.
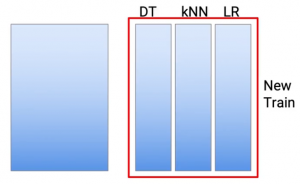
e le previsioni che ho avuto nel mio test sono diventate il mio nuovo set di dati di test. E ora creo un modello su questi set di dati di test e treno per arrivare alle mie previsioni finali.

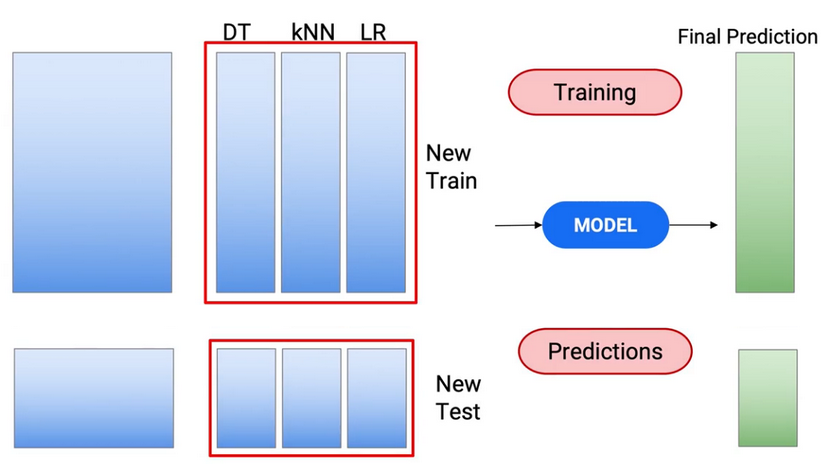
Quindi usiamo questo nuovo treno per creare il modello del treno e fare previsioni nel mio test per ottenere le mie previsioni del test finale.
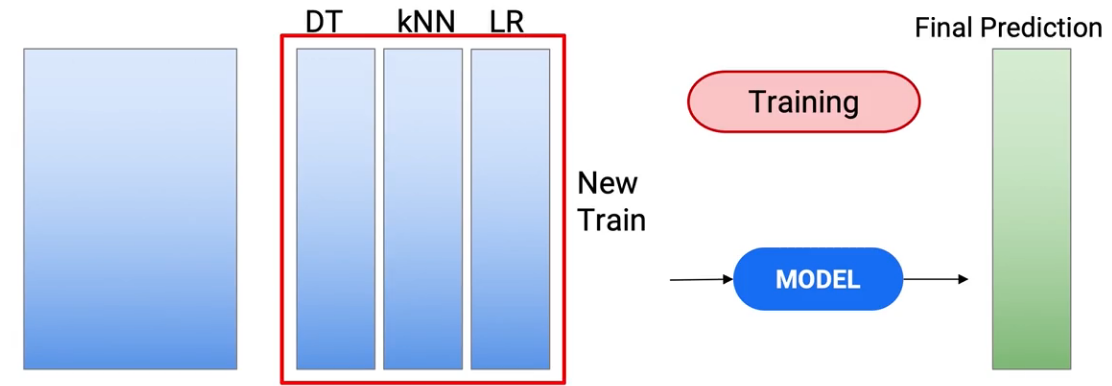

Quindi, questa è la variante più popolare di impilamento, che viene utilizzato nel settore. Diamo un'occhiata ad altre varianti, che può essere usato:
1. Utilizza le funzioni fornite insieme ai nuovi pronostici.
Quindi attualmente, se ci pensi, abbiamo usato solo le nuove previsioni come caratteristiche del nostro modello finale. Quello che posso anche fare è includere le funzioni originali insieme alla nuova funzione. Quindi, invece di usare questa scatola rossa per allenarti e testare,
Posso usare la funzione completa per addestrare il mio modello, le funzioni che c'erano originariamente e le previsioni che ne sono uscite. Quindi sto aprendo il mio set di dati del treno per includere più funzioni.
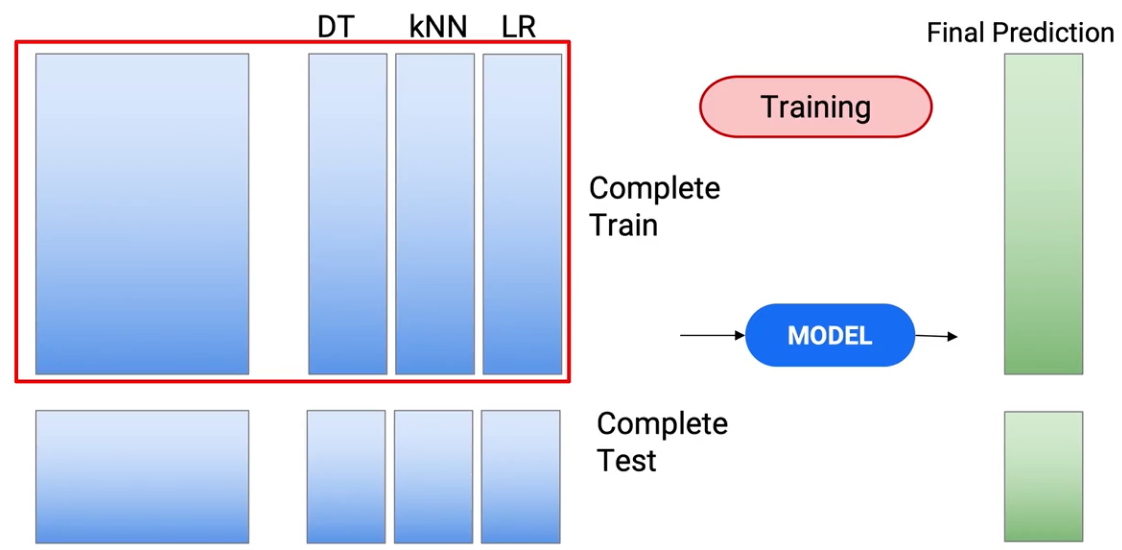
E faccio lo stesso con i test. E questo mi dà una nuova serie di previsioni.

Quindi questo è un modo in cui viene implementato anche lo stacking.
2. Genera più previsioni da testare e aggiungile
Il secondo modo per implementare lo stacking è fare previsioni multiple sul set di dati di test e aggregarle. Ancora, se ricordi cosa abbiamo fatto, li creiamo noi 10 previsioni per ciascuno di questi file di addestramento e utilizziamo uno dei modelli completi per creare le previsioni dal set di dati del test. Ora, quello che potresti fare anche tu è farlo per 10, ognuno di questi 10 Modelli, che sono stati creati, e poi aggiungili al posto dell'intero modello.
Quindi, ancora, gli stessi modelli che stava usando per fare le previsioni per 1, 2 e ciascuno di questi set di dati, Uso lo stesso modello per creare le mie previsioni per il test. E poi li ho mediati per arrivare al mio test finale, cosa userò per il modello finale?.
Ancora, come ho detto, questi sono tutti modelli diversi e modi diversi per implementare l'impilamento e l'assemblaggio. Hai la completa libertà di essere creativo e trovare nuovi modi per ridurre il sovradattamento. Perciò, gli obiettivi generali sono di garantire che:
- La nostra precisione aumenta
- La complessità rimane il più bassa possibile
- Ed evitiamo il sovradattamento
Finché fai qualcosa per raggiungere questi tre obiettivi, sarebbe una valida strategia, verità?
3. Aumenta il numero di livelli per impilare i modelli.
Quindi, la terza variante di impilamento è dove, invece di mantenere un unico modello in tutte le previsioni, Ho finito per creare i livelli del modello. Quindi, ad esempio, in questo caso particolare-
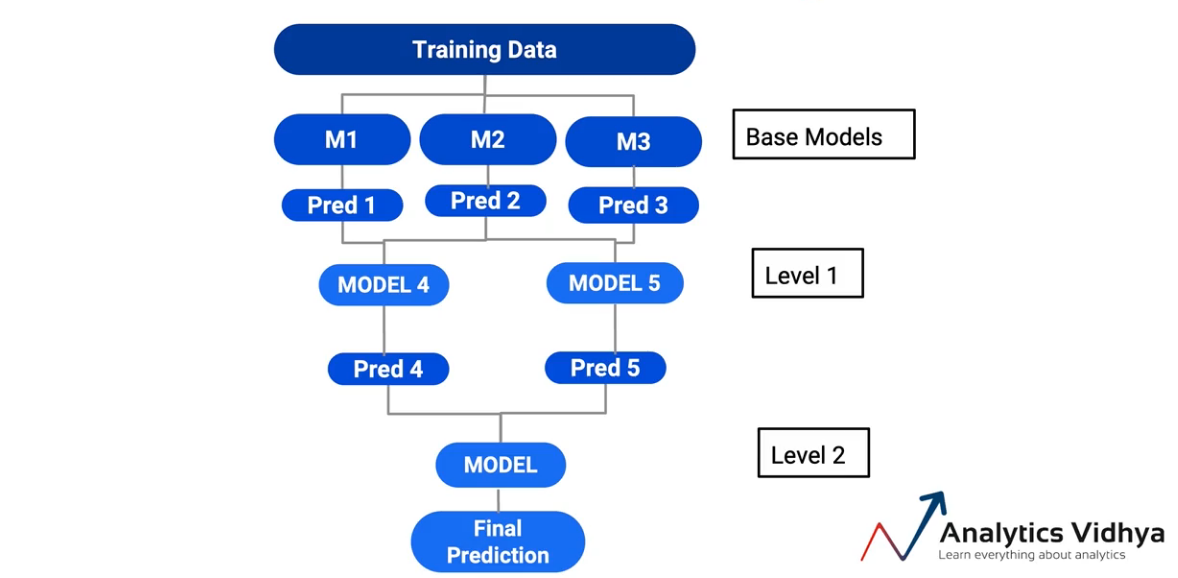
Ho preso le previsioni da M1 e M2 e le ho passate a un altro modello, M4. Allo stesso modo, preso previsioni dal Modello 2 e il modello 3 e li ha dati in pasto alla Modella 5. E il modello finale era in realtà un modello nel Modello 4 e il modello 5. Così ho finito per creare due livelli di modelli nei miei modelli base. E di nuovo, è un modo valido per impilare. E a seconda della situazione, puoi scegliere questi.
Quindi queste erano le varianti di impilamento, come ho detto, fintanto che ti assicuri che tutti e tre i requisiti di assemblaggio siano soddisfatti, che noi: assicurandoti di non sovradimensionare i tuoi modelli, assicurandosi di mantenere i modelli il più semplici possibile, e aumenta la tua precisione. Ricorda che puoi essere il più creativo possibile con l'impilamento o qualsiasi altro modello di insieme se tieni a mente solo questi tre punti..
Note finali
Ho coperto alcune varianti per l'impilamento. Quindi sentiti libero di usarli. E con quei tre limiti o con quei pensieri, qualsiasi variazione a cui puoi pensare sarebbe una variazione valida.
Se stai cercando di iniziare il tuo viaggio nella scienza dei dati e desideri tutti gli argomenti sotto lo stesso tetto, la tua ricerca si ferma qui. Dai un'occhiata alle certificazioni AI e ML BlackBelt di DataPeaker Più Programma
Se hai qualche domanda, fammi sapere nella sezione commenti!





