Questo articolo è stato pubblicato nell'ambito del Blogathon sulla scienza dei dati.
introduzione
La visualizzazione dei dati in Python è forse una delle funzionalità più utilizzate per la scienza dei dati con Python oggi.. Le librerie in Python sono dotate di molte funzionalità diverse che consentono agli utenti di creare grafica altamente personalizzata, elegante e interattivo.
In questo articolo, tratteremo l'uso di Matplotlib, Seaborn, così come un'introduzione ad altri pacchetti alternativi che possono essere utilizzati nella visualizzazione Python.
All'interno di Matplotlib e Seaborn, tratteremo alcuni dei grafici più utilizzati nel mondo della scienza dei dati per una facile visualizzazione.
Più avanti nell'articolo, esamineremo un'altra potente funzionalità nelle visualizzazioni Python, la subtrama, e abbiamo trattato un tutorial di base per la creazione di sottotrame.
Pacchetti utili per le visualizzazioni in python
Matplotlib
Matplotlib è una libreria di visualizzazione Python per diagrammi array 2D. Matplotlib è scritto in Python e fa uso della libreria NumPy. Può essere utilizzato in shell Python e IPython, Laptop Jupyter e server di applicazioni web. Matplotlib viene fornito con un'ampia varietà di grafici come la linea, sbarra, dispersione, istogramma, eccetera. che può aiutarci ad approfondire la nostra comprensione delle tendenze, modelli e correlazioni. È stato introdotto da John Hunter in 2002.
Seaborn
Seaborn è una libreria orientata ai set di dati per eseguire rappresentazioni statistiche in Python. È sviluppato su matplotlib e per creare diverse visualizzazioni. È integrato con le strutture dati dei panda. La libreria esegue la mappatura e l'aggregazione internamente per creare visual informativi. Si consiglia di utilizzare un'interfaccia Jupyter / IPython e modo matplotlib.
bokeh
Bokeh è una libreria di visualizzazione interattiva per i browser Web moderni. È adatto per lo streaming o per grandi risorse di dati e può essere utilizzato per sviluppare grafici e dashboard interattivi. C'è una vasta gamma di grafici intuitivi nella libreria che possono essere sfruttati per sviluppare soluzioni. Funziona a stretto contatto con gli strumenti PyData. La libreria è adatta per creare immagini personalizzate in base ai casi d'uso richiesti. Le immagini possono anche essere rese interattive per fungere da ipotetico modello di scenario. Tutto il codice è open source e disponibile su GitHub.
Altair
Altair è una libreria di visualizzazione statistica dichiarativa per Python. Altair API è facile da usare e coerente, y está construida sobre la especificación Vega-Lite JSONJSON, o Notazione degli oggetti JavaScript, Si tratta di un formato di scambio dati leggero e facile da leggere e scrivere per gli esseri umani, e facile da analizzare e generare per le macchine. Viene comunemente utilizzato nelle applicazioni Web per inviare e ricevere informazioni tra un server e un client. La sua struttura si basa su coppie chiave-valore, rendendolo versatile e ampiamente adottato nello sviluppo di software... La libreria dichiarativa indica che durante la creazione di qualsiasi oggetto visivo, dobbiamo definire i collegamenti tra le colonne di dati e i canali (asse X, asse y, dimensione, colore). Con l'aiuto di Altair, le immagini informative possono essere create con un codice minimo. Altair ha una grammatica dichiarativa sia di visualizzazione che di interazione.
tramamente
plotly.py è una libreria di visualizzazione interattiva, open source, alto livello, dichiarativo e basato su browser per Python. Contiene una varietà di visualizzazioni utili tra cui grafici scientifici, Grafica 3D, grafici statistici, grafici finanziari, tra gli altri. La grafica della trama può essere visualizzata nei taccuini Jupyter, file HTML autonomi o ospitati online. La libreria Plotly offre opzioni per l'interazione e la modifica. La robusta API funziona perfettamente sia in modalità web che browser locale.
ggplot
ggplot è un'implementazione Python della grammatica grafica. La grammatica grafica si riferisce alla mappatura dei dati in attributi estetici (colore, forma, dimensione) e oggetti geometrici (punti, Linee, barre). Gli elementi costitutivi di base secondo la grammatica dei grafici sono i dati, geome (oggetti geometrici), statistiche (trasformazioni statistiche), scala, sistema di coordinate e sfaccettatura.
L'uso di ggplot in Python ti consente di sviluppare visualizzazioni informative in modo incrementale, comprendere prima le sfumature dei dati e poi regolare i componenti per migliorare le rappresentazioni visive.
Come utilizzare la visualizzazione corretta?
Per estrarre le informazioni richieste dai diversi elementi visivi che creiamo, è essenziale utilizzare la rappresentazione corretta in base al tipo di dati e alle domande che stiamo cercando di capire. Prossimo, esamineremo una serie di rappresentazioni più utilizzate e come possiamo usarle nel modo più efficace.
Grafico a barre
un grafico a barreIl grafico a barre è una rappresentazione visiva dei dati che utilizza barre rettangolari per mostrare confronti tra diverse categorie. Ogni barra rappresenta un valore e la sua lunghezza è proporzionale ad esso. Questo tipo di grafico è utile per visualizzare e analizzare le tendenze, facilitare l'interpretazione delle informazioni quantitative. È ampiamente utilizzato in varie discipline, come le statistiche, Marketing e ricerca, Grazie alla sua semplicità ed efficacia.... Se utiliza cuando queremos comparar valores métricos en diferentes subgrupos de datos. Se abbiamo un numero maggiore di gruppi, Un grafico a barre è preferito a un istogramma.
Grafico a barre con Matplotlib
#Creating the dataset df = sns.load_dataset('titanico') df=df.groupby('chi')['tariffa'].somma().to_frame().reset_index() #Creating the bar chart plt.barh(df['chi'],df['tariffa'],colore = ['#F0F8FF','#E6E6FA','#B0E0E6']) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
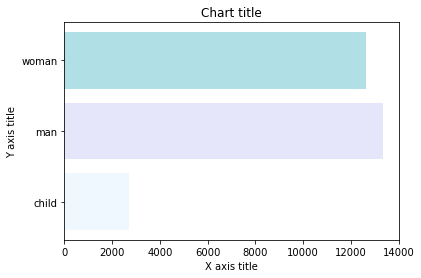
Grafico a barre con Seaborn
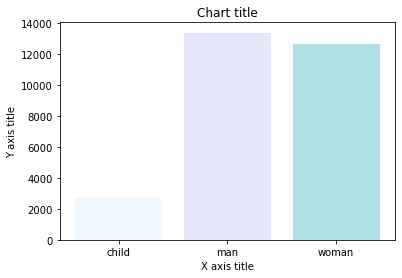
#Creating bar plot sns.barplot(x = 'tariffa',y = 'chi',dati = titanic_dataset,tavolozza = "Blues") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
Istogramma
Gli istogrammi vengono utilizzati principalmente quando è necessario confrontare una singola categoria di dati tra singoli sottoelementi., ad esempio, quando si confronta il reddito tra le regioni.
Istogramma con Matplotlib
#Creating the dataset df = sns.load_dataset('titanico') df=df.groupby('chi')['tariffa'].somma().to_frame().reset_index() #Creating the column plot plt.bar(df['chi'],df['tariffa'],colore = ['#F0F8FF','#E6E6FA','#B0E0E6']) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
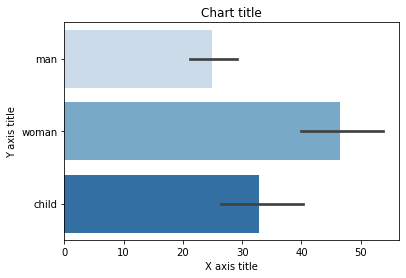
Istogramma con Seaborn
#Reading the dataset titanic_dataset = sns.load_dataset('titanico') #Creating column chart sns.barplot(x = 'chi',y = 'tariffa',dati = titanic_dataset,tavolozza = "Blues") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
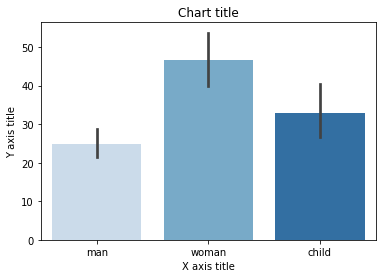
Grafico a barre raggruppato
Un grafico a barre raggruppato viene utilizzato quando si desidera confrontare i valori in determinati gruppi e sottogruppi.
Grafico delle barre raggruppate utilizzando Matplotlib
#Creating the dataset df = sns.load_dataset('titanico') df_pivot = pd.pivot_table(df, valori="Tariffa",indice="chi",colonne="classe", aggfunc=np.mean) #Creating a grouped bar chart ax = df_pivot.plot(gentile="bar",alfa=0,5) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
Tabella delle barre raggruppate con Seaborn
#Reading the dataset titanic_dataset = sns.load_dataset('titanico') #Creating the bar plot grouped across classes sns.barplot(x = 'chi',y = 'tariffa',tonalità="classe",dati = titanic_dataset, tavolozza = "Blues") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
Grafico a barre in pila
Un grafico a barre in pila viene utilizzato quando vogliamo confrontare le dimensioni totali dei gruppi disponibili e la composizione dei diversi sottogruppi.
Grafico a barre in pila con Matplotlib
# Stacked bar chart #Creating the dataset df = pd.DataFrame(colonne=["UN","B", "C","D"], dati=[["E",0,1,1], ["F",1,1,0], ["G",0,1,0]]) df.plot.bar(x='A', y =["B", "C","D"], stacked=Vero, larghezza = 0,4,alfa=0,5) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
Grafico a barre impilato con Seaborn
dataframe = pd.DataFrame(colonne=["UN","B", "C","D"],
dati=[["E",0,1,1],
["F",1,1,0],
["G",0,1,0]])
dataframe.set_index('UN').T.trama(tipo='bar', stacked=Vero)
#Adding the aesthetics
plt.title('Titolo del grafico')
plt.xlabel('Titolo asse X')
plt.ylabel('Titolo asse Y')
# Show the plot
plt.show()
Grafico a linee
Se utiliza un grafico a lineeIl grafico a linee è uno strumento visivo utilizzato per rappresentare i dati nel tempo. È costituito da una serie di punti collegati da linee, che permette di osservare le tendenze, Fluttuazioni e modelli nei dati. Questo tipo di grafico è particolarmente utile in aree come l'economia, Meteorologia e ricerca scientifica, semplificando il confronto di diversi set di dati e l'identificazione dei comportamenti su tutta la linea.. para la representación de puntos de datos continuos. Questo elemento visivo può essere utilizzato efficacemente quando vogliamo capire l'andamento nel tempo..
Grafico a linee con Matplotlib
#Creating the dataset df = sns.load_dataset("iris") df=df.groupby('sepal_length')['sepal_width'].somma().to_frame().reset_index() #Creating the line chart plt.plot(df['sepal_length'], df['sepal_width']) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
Grafico a linee con Seaborn
#Creating the dataset cars = ['AUDI', 'BMW', 'NISSAN', 'TESLA', 'HYUNDAI', 'HONDA'] dati = [20, 15, 15, 14, 16, 20] #Creating the pie chart plt.pie(dati, etichette = automobili,colori = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B']) #Adding the aesthetics plt.title('Titolo del grafico') #Show the plot plt.show()
Grafico a torta
I grafici a torta possono essere utilizzati per identificare le proporzioni dei diversi componenti in un dato insieme.
Grafico a torta con Matplotlib
#Creating the dataset cars = ['AUDI', 'BMW', 'NISSAN', 'TESLA', 'HYUNDAI', 'HONDA'] dati = [20, 15, 15, 14, 16, 20] #Creating the pie chart plt.pie(dati, etichette = automobili,colori = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B']) #Adding the aesthetics plt.title('Titolo del grafico') #Show the plot plt.show()
Grafico ad area
I grafici ad area vengono utilizzati per tenere traccia delle modifiche nel tempo per uno o più gruppi. I grafici ad area sono preferiti ai grafici a linee quando vogliamo acquisire modifiche nel tempo per più di un gruppo.
Grafico ad area con Matplotlib
#Reading the dataset x=range(1,6) y =[ [1,4,6,8,9], [2,2,7,10,12], [2,8,5,10,6] ] #Creating the area chart ax = plt.gca() ax.stackplot(X, e, etichette=['UN','B','C'],alfa=0,5) #Adding the aesthetics plt.legend(loc ="superiore sinistro") plt.titolo('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
Grafico ad area con Seaborn
# Data years_of_experience =[1,2,3] stipendio=[ [6,8,10], [4,5,9], [3,5,7] ] # Plot plt.stackplot(years_of_experience,stipendio, etichette=[«Società A»,«Società B»,«Società C»]) plt.legend(loc ="superiore sinistro") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
Istogramma della colonna
Il istogrammiGli istogrammi sono rappresentazioni grafiche che mostrano la distribuzione di un set di dati. Sono costruiti dividendo l'intervallo di valori in intervalli, oh "Bidoni", e il conteggio della quantità di dati che cadono in ogni intervallo. Questa visualizzazione consente di identificare i modelli, tendenze e variabilità dei dati in modo efficace, facilitare l'analisi statistica e il processo decisionale informato in varie discipline.... De columna se utilizan para observar la distribución de una sola variabileIn statistica e matematica, un "variabile" è un simbolo che rappresenta un valore che può cambiare o variare. Esistono diversi tipi di variabili, e qualitativo, che descrivono caratteristiche non numeriche, e quantitativo, che rappresentano quantità numeriche. Le variabili sono fondamentali negli esperimenti e negli studi, poiché consentono l'analisi delle relazioni e dei modelli tra elementi diversi, facilitare la comprensione di fenomeni complessi.... con pocos puntos de datos.
Istogramma con Matplotlib
#Creating the dataset penguins = sns.load_dataset("pinguini") #Creating the column histogram ax = plt.gca() ax.hist(pinguini['flipper_length_mm'], colore="blu",alfa=0,5, contenitori=10) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
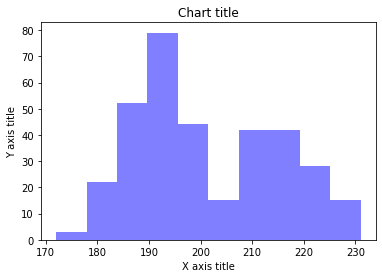
Istogramma con Seaborn
#Reading the dataset penguins_dataframe = sns.load_dataset("pinguini") #Plotting bar histogram sns.distplot(penguins_dataframe['flipper_length_mm'], kde = falso, colore="blu", contenitori=10) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
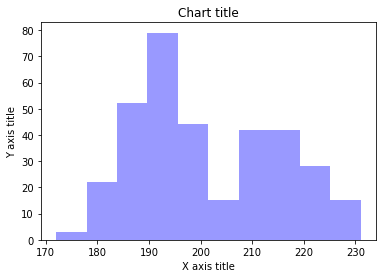
Istogramma lineare
Gli istogrammi di linea vengono utilizzati per osservare la distribuzione di una singola variabile con molti punti dati.
Grafico a istogramma lineare con Matplotlib
#Creating the dataset df_1 = np.random.normal(0, 1, (1000, )) densità = stats.gaussian_kde(df_1) #Creating the line histogram n, X, _ = plt.hist(df_1, bins=np.linspace(-3, 3, 50), histtype=u'step', densità=Vero) plt.trama(X, densità(X)) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
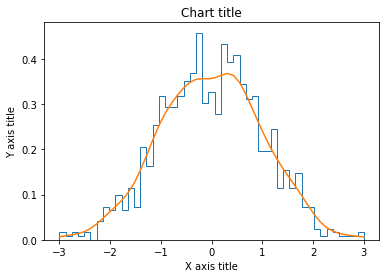
Grafico a istogramma a linee con Seaborn
#Reading the dataset penguins_dataframe = sns.load_dataset("pinguini") #Plotting line histogram sns.distplot(penguins_dataframe['flipper_length_mm'], hist = Falso, kde = Vero, etichetta="Africa") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
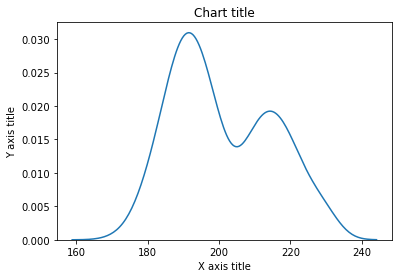
Grafico a dispersione
I grafici a dispersione possono essere sfruttati per identificare le relazioni tra due variabili. può essere utilizzato in modo efficace in circostanze in cui la variabile dipendente può avere più valori per la variabile indipendente.
Grafico a dispersione utilizzando Matplotlib
#Creating the dataset df = sns.load_dataset("Suggerimenti") #Creating the scatter plot plt.scatter(df['fattura_totale'],df['suggerimento'],alfa=0,5 ) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
Grafico a dispersione utilizzando Seaborn
#Reading the dataset bill_dataframe = sns.load_dataset("Suggerimenti") #Creating scatter plot sns.scatterplot(data=bill_dataframe, x="total_bill", y ="mancia") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
Grafico a bolle
I grafici a dispersione possono essere utilizzati per rappresentare e visualizzare le relazioni tra tre variabili.
Grafico a bolle con Matplotlib
#Creating the dataset np.random.seed(42) N = 100 x = np.random.normal(170, 20, n) y = x + np.random.normal(5, 25, n) colori = np.random.rand(n) area = (25 * np.random.rand(n))**2 df = pd.DataFrame({ 'X': X, 'Y': e, 'Colori': colori, "bubble_size":la zona}) #Creating the bubble chart plt.scatter('X', 'Y', s="bubble_size",alfa=0,5, dati=df) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
Gráfico de burbujas con Seaborn
#Reading the dataset bill_dataframe = sns.load_dataset("Suggerimenti") #Creating bubble plot sns.scatterplot(data=bill_dataframe, x="total_bill", y ="mancia", tonalità="dimensione", taglia="dimensione") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
Trama scatola
Se utiliza un diagrama de caja para mostrar la forma de la distribución, su valor central y su variabilidad.
Diagrama de caja usando Matplotlib
from past.builtins import xrange #Creating the dataset df_1 = [[1,2,5], [5,7,2,2,5], [7,2,5]] df_2 = [[6,4,2], [1,2,5,3,2], [2,3,5,1]] #Creating the box plot ticks = ['UN', 'B', 'C'] plt.figure() bpl = plt.boxplot(df_1, positions=np.array(xrange(len(df_1)))*2.0-0.4, sym='', larghezze=0,6) bpr = plt.boxplot(df_2, positions=np.array(xrange(len(df_2)))*2.0+0.4, sym='', larghezze=0,6) plt.trama([], c="#D7191C ·", etichetta="Etichetta 1") plt.trama([], c="#2C7BB6 ·", etichetta="Etichetta 2") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') plt.legend() plt.xticks(xrange(0, len(Zecche) * 2, 2), Zecche) plt.xlim(-2, len(Zecche)*2) plt.ylim(0, 8) plt.tight_layout() #Show the plot plt.show()
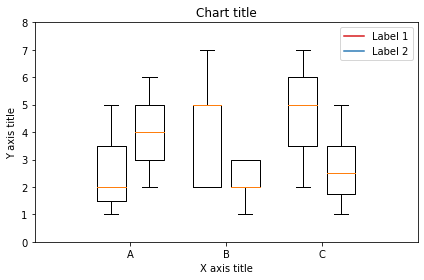
Diagrama de caja utilizando Seaborn
#Reading the dataset bill_dataframe = sns.load_dataset("Suggerimenti") #Creating boxplots ax = sns.boxplot(x="giorno", y ="total_bill", tonalità="fumatore", data=bill_dataframe, tavolozza="Set3") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
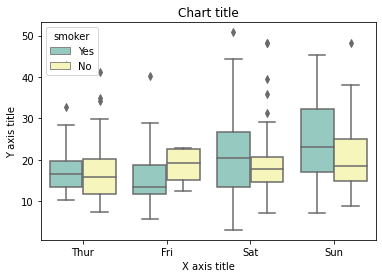
Gráfico de cascada
Un grafico a cascata può essere utilizzato per spiegare la transizione graduale nel valore di una variabile soggetta a incrementi o diminuzioni..
#Reading the dataset test = pd.Series(-1 + 2 * np.random.rand(10), index=elenco('abcdefghij')) #Function for makig a waterfall chart def waterfall(serie): df = pd.DataFrame({'pos':np.maximum(serie,0),'negativo':np.minimum(serie,0)}) blank = series.cumsum().spostare(1).riempire(0) df.plot(tipo='bar', stacked=Vero, bottom=vuoto, colore=['R','B'], alfa=0,5) passo = blank.reset_index(drop=Vero).ripetere(3).spostare(-1) fare un passo[1::3] = np.nan plt.plot(step.index, step.values,'k') #Creating the waterfall chart waterfall(test) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') #Show the plot plt.show()
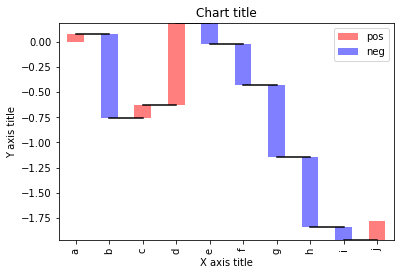
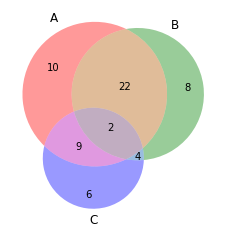
Diagramma di Venn
I diagrammi di Venn vengono utilizzati per visualizzare le relazioni tra due o tre insiemi di elementi. Evidenzia somiglianze e differenze
from matplotlib_venn import venn3
#Making venn diagram
venn3(sottoinsiemi = (10, 8, 22, 6,9,4,2))
plt.mostra()
Mappa ad albero
Le mappe ad albero vengono utilizzate principalmente per visualizzare i dati raggruppati e nidificati in una struttura gerarchica e osservare il contributo di ciascun componente.
import squarify sizes = [40, 30, 5, 25, 10] squarify.plot(taglie) #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') # Show the plot plt.show()
Grafico a barre 100% Accatastato
È possibile sfruttare un grafico a barre in pila di 100% Quando vogliamo mostrare le differenze relative all'interno di ciascun gruppo per i diversi sottogruppi disponibili.
#Reading the dataset r = [0,1,2,3,4] raw_data = {'greenBars': [20, 1.5, 7, 10, 5], 'orangeBars': [5, 15, 5, 10, 15],'blueBars': [2, 15, 18, 5, 10]} df = pd.DataFrame(raw_data) # From raw value to percentage totals = [i+j+k per i,J,k in zip(df['greenBars'], df['orangeBars'], df['blueBars'])] greenBars = [io / J * 100 per me,j in zip(df['greenBars'], Totali)] orangeBars = [io / J * 100 per me,j in zip(df['orangeBars'], Totali)] blueBars = [io / J * 100 per me,j in zip(df['blueBars'], Totali)] # plot barWidth = 0.85 nomi = ('UN','B','C','D',"E") # Create green Bars plt.bar(R, greenBars, colore="#b5ffb9", bordocolore="bianco", width=barLarghezza) # Create orange Bars plt.bar(R, orangeBars, bottom=greenBars, colore="#F9bc86", bordocolore="bianco", width=barLarghezza) # Create blue Bars plt.bar(R, blueBars, in basso=[i+j per i,j in zip(greenBars, orangeBars)], colore="#a3acff", bordocolore="bianco", width=barLarghezza) # Custom x axis plt.xticks(R, nomi) plt.xlabel("gruppo") #Adding the aesthetics plt.title('Titolo del grafico') plt.xlabel('Titolo asse X') plt.ylabel('Titolo asse Y') plt.mostra()
Trame marginali
I grafici marginali vengono utilizzati per valutare la relazione tra due variabili ed esaminarne le distribuzioni. Tali grafici a dispersione che hanno istogrammi, box plotDiagrammi a scatola, Conosciuto anche come diagrammi a scatola e baffi, sono strumenti statistici che rappresentano la distribuzione di un dataset. Questi diagrammi mostrano la mediana, quartili e valori anomali, Consentire la visualizzazione della variabilità e della simmetria dei dati. Sono utili nel confronto tra diversi gruppi e nell'analisi esplorativa, Rendendo più facile identificare tendenze e modelli nei dati.... o diagramas de puntos en los márgenes de los ejes xey respectivos
#Reading the dataset iris_dataframe = sns.load_dataset('iris') #Creating marginal graphs sns.jointplot(x=iris_dataframe["sepal_lunghezza"], y=iris_dataframe["larghezza_sepalo"], kind='scatter') # Show the plot plt.show()
Sottoparcella
Le sottotrame sono potenti visualizzazioni che facilitano il confronto tra fotogrammi
#Creating the dataset df = sns.load_dataset("iris") df=df.groupby('sepal_length')['sepal_width'].somma().to_frame().reset_index() #Creating the subplot fig, assi = plt.sottotrame(nrows=2, ncols=2) ax=df.plot('sepal_length', 'sepal_width',ax=assi[0,0]) ax.get_legend().rimuovere() #Adding the aesthetics ax.set_title('Titolo del grafico') ax.set_xlabel('Titolo asse X') ax.set_ylabel('Titolo asse Y') ax=df.plot('sepal_length', 'sepal_width',ax=assi[0,1]) ax.get_legend().rimuovere() ax=df.plot('sepal_length', 'sepal_width',ax=assi[1,0]) ax.get_legend().rimuovere() ax=df.plot('sepal_length', 'sepal_width',ax=assi[1,1]) ax.get_legend().rimuovere() #Show the plot plt.show()
In conclusione, ci sono una varietà di librerie diverse che possono essere sfruttate al massimo del loro potenziale comprendendo il caso d'uso e i requisiti. La sintassi e la semantica variano da pacchetto a pacchetto ed è essenziale comprendere le sfide e i vantaggi delle diverse librerie. Buona visione!
Científico de datos y entusiasta de la analiticoL'analisi si riferisce al processo di raccolta, Misura e analizza i dati per ottenere informazioni preziose che facilitano il processo decisionale. In vari campi, come business, Salute e sport, L'analisi può identificare modelli e tendenze, Ottimizza i processi e migliora i risultati. L'utilizzo di strumenti avanzati e tecniche statistiche è fondamentale per trasformare i dati in conoscenze applicabili e strategiche....
Il supporto mostrato in questo articolo non è di proprietà di Analytics Vidhya e viene utilizzato a discrezione dell'autore.





