introduzione: –
L'apprendimento automatico sta guidando le meraviglie tecnologiche di oggi, come le auto senza conducente, Volo spaziale, Accredito immagine e voce. Nonostante questo, Un professionista della scienza dei dati avrebbe bisogno di un grande volume di dati per creare un modello di apprendimento automatico solido e affidabile per tali problemi aziendali..

Il data mining o la raccolta dei dati è un passaggio molto primitivo nel ciclo di vita della scienza dei dati. In base alle esigenze aziendali, Potrebbe essere necessario raccogliere dati da fonti quali server, record, banche dati, API, Repository SAP online o web.
Strumenti di web scraping come Selenium possono raschiare un grande volume di dati, come testo e immagini, in un tempo relativamente breve.
Sommario: –
- Cos'è il web scraping?
- Perché il Web Scraping
- In che modo il Web Scraping è utile
- Cos'è il selenio?
- Impostazioni e strumenti
- Implementazione del web scraping delle immagini utilizzando Selenium Python
- Browser Chrome headless
- Mettendolo completamente
- Note finali
Cos'è il web scraping?? : –
Web Scrapping, Chiamato anche “inseguimento” oh “ragno” è la tecnica per raccogliere automaticamente i dati da una fonte online, In forma generale di portale web. Sebbene il Web Scrapping sia un modo semplice per ottenere un grande volume di dati in un periodo di tempo relativamente breve., Aggiunge stress al server in cui è ospitata l'origine.
Questo è anche uno dei motivi principali per cui molti siti Web non consentono di raschiare tutto sul loro portale web.. Nonostante questo, purché non interrompa la funzione principale della fonte online, è abbastanza accettabile.
Perché il Web Scraping? –
C'è un enorme volume di dati sul Web che le persone possono utilizzare per soddisfare le esigenze aziendali. Perché, È necessario uno strumento o una tecnica per raccogliere queste informazioni dal web. Ed è qui che entra in gioco il concetto di Web-Scrapping..
Quanto è utile il Web Scraping? –
Il web scraping può aiutarci a estrarre un'enorme quantità di dati sui clienti, prodotti, persone, Mercati azionari, eccetera.
I dati raccolti da un portale web possono essere utilizzati, come portale di e-commerce, Portali di lavoro, Canali di social media per comprendere i modelli di acquisto dei clienti, Comportamento di abbandono dei dipendenti e sentimenti dei clienti, e l'elenco potrebbe continuare.
Le librerie o i framework più popolari utilizzati in Python per il Web – La rottamazione è BeautifulSoup, Scrappy e Selenio.
In questo post, parleremo del web scraping usando il Selenio in Python. E la ciliegina sulla torta vedremo come possiamo raccogliere immagini dal Web che puoi usare per creare dati di addestramento per il tuo progetto di deep learning..
Cos'è il selenio?
Selenio è uno strumento di automazione open source basato sul web. Il selenio viene utilizzato principalmente per i test nell'industria, ma può anche essere usato per raschiare il tessuto. Useremo il browser Chrome ma puoi provarlo in qualsiasi browser, È quasi lo stesso.

Ora vediamo come usare il selenio per il Web Scraping.
Impostazioni e strumenti: –
- Installazione:
- Installare il selenio usando pip
pip installare selenio
- Installare il selenio usando pip
- Scarica il driver di Chrome:
Per scaricare i driver Web, È possibile selezionare uno dei seguenti metodi:- È possibile scaricare direttamente il driver Chrome dal seguente link:
https://chromedriver.chromium.org/downloads - Oppure puoi scaricarlo direttamente utilizzando la riga di codice successiva:Driver = WebDriver. Cromo (ChromeDriverManager (). installare ())
- È possibile scaricare direttamente il driver Chrome dal seguente link:
La documentazione completa sul selenio può essere trovata qui. La documentazione è autoesplicativa, quindi assicurati di leggerlo per sfruttare il selenio con Python.
I seguenti metodi ci aiuteranno a trovare elementi in una pagina Web (Questi metodi restituiranno un elenco):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
Ora, scrivere codice Python per estrarre immagini dal web.
Implementazione del web scraping delle immagini utilizzando Selenium Python: –
passo 1: – Importa librerie
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import ElementClickInterceptedException
passo 2: – Installare il driver
#Installa driver driver = webdriver. Cromo(ChromeDriverManager().installare())
passo 3: – Specificare l'URL di ricerca
#Specificare l'URL di ricerca search_url="https://www.google.com/search?q={Q}&tbm=isch&tbs=sur:fc&hl=it&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&BiH=568" driver.get(search_url.formato(q='Auto'))
Ho usato questo URL specifico in modo da non avere problemi per l'utilizzo di immagini protette da copyright o con licenza. Caso opposto, Puoi usare https://google.com anche come URL di ricerca.
Quindi cerchiamo Auto nel nostro URL di ricerca. Incollare il collegamento nella funzione driver.get (“Il tuo link qui”) ed eseguire la cella. Si aprirà una nuova finestra del browser per quel link..
passo 4: – Scorri fino alla fine della pagina.
#Scorri fino alla fine della pagina
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
tempo.dormire(5)#sleep_between_interactions
Questa riga di codice ci aiuterebbe ad arrivare in fondo alla pagina. E poi gli diamo un tempo di inattività di 5 secondi in modo da non avere problemi, dove stiamo cercando di leggere gli elementi nella pagina, che non è ancora stato caricato.
passo 5: – Individuare le immagini da raschiare dalla pagina.
#Individua le immagini da estrarre dalla pagina corrente
imgResults = driver.find_elements_by_xpath("//img[contiene(@class,'Q4LuWd')]")
totalResults=len(imgRisultati)
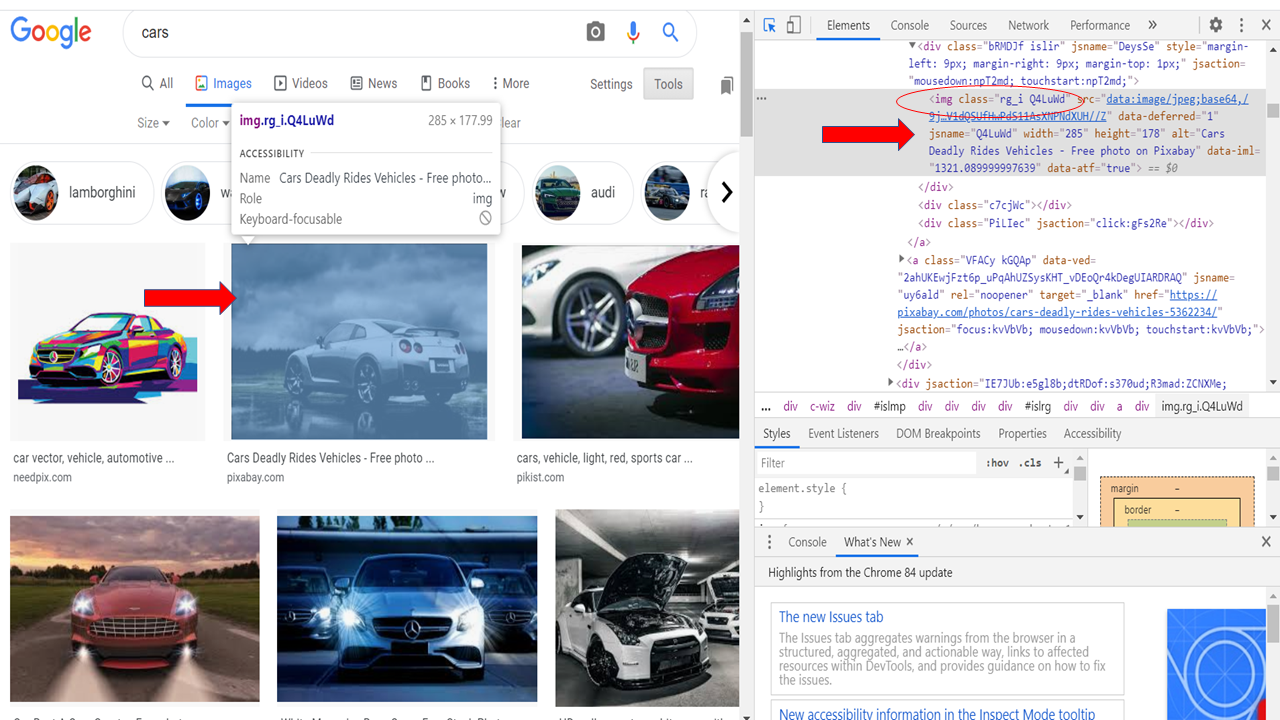
Ora cercheremo tutti i link alle immagini presenti in quella particolare pagina. Creeremo un “lista” Per salvare tali collegamenti. Quindi, per farlo, Vai alla finestra del browser, Fare clic con il tasto destro sulla pagina e selezionare "Ispeziona articolo"’ o abilitare gli strumenti di sviluppo utilizzando Ctrl + Spostare + io.
Ora identifica qualsiasi attributo come classe, ID, eccetera. Che è comune in tutte queste immagini.
Nel nostro caso, class="'Q4LuWd" è comune in tutte queste immagini.
passo 6: – Estrai il rispettivo link da ogni immagine
Come possiamo, Le immagini visualizzate sulla pagina sono ancora le miniature, non l'immagine originale. Quindi, per scaricare ogni immagine, Dobbiamo fare clic su ogni miniatura ed estrarre le informazioni rilevanti relative a quell'immagine.
#Clicca su ogni immagine per estrarre il link corrispondente da scaricare
img_urls = insieme()
per io in gamma(0,len(imgRisultati)):
img=imgRisultati[io]
Tentativo:
img.click()
tempo.dormire(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
per actual_image in actual_images:
Se actual_image.get_attribute('src') e 'https' in actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
tranne ElementClickInterceptedException o Metodo ElementNotInteractableException come errare:
Stampa(errare)
Quindi, nel frammento di codice sopra, Stiamo eseguendo le seguenti attività:
- Ripetere ogni miniatura e quindi fare clic su di essa.
- Fai in modo che il nostro browser stia dormendo durante 2 secondi (: P).
- Cerca il tag HTML univoco corrispondente a quell'immagine per posizionarlo nella pagina
- Otteniamo ancora più di un risultato per una particolare immagine. Ma siamo tutti interessati al link per scaricare quell'immagine.
- Quindi, Iteriamo ogni risultato per quell'immagine ed estraiamo l'attributo 'src'’ dello stesso e poi vediamo se “https” è presente nella 'CRS'’ o no. Poiché regolarmente il collegamento web inizia con 'https'.
passo 7: – Scarica e salva ogni immagine nella directory di destinazione
os.chdir(«C:/Qurantine/Blog/WebScrapping/Dataset1') baseDir=os.getcwd()
per io, URL in enumerare(img_urls):
file_name = f"{io:150}.jpg"
Tentativo:
image_content = requests.get(URL).contenuto
tranne Eccezione come e:
Stampa(F"ERRORE - IMPOSSIBILE SCARICARE {URL} - {e}")
Tentativo:
image_file = io. BytesIO(image_content)
immagine = immagine.open(image_file).Convertire('RGB')
file_path = os.path.join(baseDir, nome del file)
insieme a aprire(file_path, 'wb') come F:
immagine.save(F, "JPEG", qualità=85)
Stampa(F"SALVATO - {URL} - A: {file_path}")
tranne Eccezione come e:
Stampa(F"ERRORE - IMPOSSIBILE SALVARE {URL} - {e}")
Ora in sintesi hai estratto l'immagine per il tuo progetto 😀
Nota: – Una volta scritto il codice giusto, Il browser non è essenziale, può raccogliere dati senza un browser, Quella che viene chiamata una finestra del browser headless, perché, Sostituire il codice riportato di seguito con quello precedente.
Browser Chrome headless
#Browser Chrome headless
a partire dal selenio importare webdriver
opts = webdriver.ChromeOptions()
opts.headless =Vero
Driver = WebDriver. Cromo(ChromeDriverManager().installare())
Per questo caso, Il browser non verrà eseguito in background, che è molto utile quando si implementa una soluzione in produzione.
Mettiamo tutto questo codice in un'unica funzione per renderlo più organizzabile e implementare la stessa idea per scaricare 100 Immagini per ogni categoria (come esempio, automobili, Cavalli).
E questa volta scriveremo il nostro codice usando l'idea del cromo headless..
Mettere tutto insieme:
passo 1: Importa tutte le librerie essenziali
importare tu
importare selenio
a partire dal selenio importare WebDriver
importare tempo
a partire dal PIL importare Immagine
importare Io
importare Richieste
a partire dal webdriver_manager.chrome importare ChromeDriverManager
os.chdir(«C:/Qurantine/Blog/WebScrapping')
passo 2: installare il driver di Chrome
#Installare il driver opts=webdriver. ChromeOptions() opts.headless=Vero driver = webdriver. Cromo(ChromeDriverManager().installare() ,options=opts)
In questo passaggio, installiamo un driver Chrome e utilizziamo un browser headless per raschiare il web.
passo 3: specificare l'URL di ricerca
search_url = "https://www.google.com/search?q={Q}&tbm=isch&tbs=sur:fc&hl=it&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&BiH=568" driver.get(search_url.formato(q='Auto'))
Ho usato questo URL specifico per estrarre immagini royalty-free.
passo 4: Scrivi una funzione per portare il cursore in fondo alla pagina
def scroll_to_end(autista):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
tempo.dormire(5)#sleep_between_interactions
Questo frammento di codice scorrerà la pagina verso il basso.
passo 5. Scrivi una funzione per ottenere l'URL di ogni immagine.
#Nessun problema di licenza
def getImageUrls(nome,totalImgs,autista):
search_url = "https://www.google.com/search?q={Q}&tbm=isch&tbs=sur:fc&hl=it&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&BiH=568"
driver.get(search_url.formato(q=nome))
img_urls = insieme()
img_count = 0
results_start = 0
mentre(img_count<totalImgs): #Estrai immagini reali ora
scroll_to_end(autista)
thumbnail_results = driver.find_elements_by_xpath("//img[contiene(@class,'Q4LuWd')]")
totalResults=len(thumbnail_results)
Stampa(F"Fondare: {totalRisultati} Risultati della ricerca. Estrazione di collegamenti da{results_start}:{totalRisultati}")
per img in thumbnail_results[results_start:totalRisultati]:
img.click()
tempo.dormire(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
per actual_image in actual_images:
Se actual_image.get_attribute('src') e 'https' in actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
img_count=len(img_urls)
Se img_count >= totalImgs:
Stampa(F"Fondare: {img_count} Link alle immagini")
rottura
altro:
Stampa("Fondare:", img_count, "Alla ricerca di altri link di immagini ...")
load_more_button = driver.find_element_by_css_selector(".mye4qd")
driver.execute_script("document.querySelector('.mye4qd').clic();")
results_start = len(thumbnail_results)
Restituzione img_urls
Questa funzione restituirebbe un elenco di URL per ogni categoria (come esempio, Auto, cavalli, eccetera.)
passo 6: Scrivi una funzione per scaricare ogni immagine
def downloadImmagini(folder_path,nome del file,URL):
Tentativo:
image_content = requests.get(URL).contenuto
tranne Eccezione come e:
Stampa(F"ERRORE - IMPOSSIBILE SCARICARE {URL} - {e}")
Tentativo:
image_file = io. BytesIO(image_content)
immagine = immagine.open(image_file).Convertire('RGB')
file_path = os.path.join(folder_path, nome del file)
insieme a aprire(file_path, 'wb') come F:
immagine.save(F, "JPEG", qualità=85)
Stampa(F"SALVATO - {URL} - A: {file_path}")
tranne Eccezione come e:
Stampa(F"ERRORE - IMPOSSIBILE SALVARE {URL} - {e}")
Questo frammento di codice scaricherà l'immagine di ogni URL.
passo 7: – Digitare una funzione per salvare ogni immagine nella directory di destinazione
def saveInDestFolder(searchNames,destDir,totalImgs,autista):
per nome in elenco(searchNames):
percorso=os.path.join(destDir,nome)
Se non os.path.isdir(il percorso):
os.mkdir(il percorso)
Stampa('Percorso attuale',il percorso)
totalLinks=getImageUrls(nome,totalImgs,autista)
Stampa('totalLinks',totalLinks)
Se totalLinks è Nessuno:
Stampa('immagini non trovate per :',nome)
Continua
altro:
per io, collegamento in enumerare(totalLinks):
file_name = f"{io:150}.jpg"
downloadImmagini(il percorso,nome del file,collegamento)
searchNames=['Auto','cavalli']
destDir=f'./Dataset2/'
totalImgs=5
saveInDestFolder(searchNames,destDir,totalImgs,autista)
Questo frammento di codice salverà ogni immagine nella directory di destinazione.
Note finali
Ho fatto la mia parte per spiegare Web Scraping usando Selenium con Python nel modo più semplice possibile. Sentiti libero di commentare le tue domande. Sarò più che felice di risponderti.
Puoi clonare il mio repository Github per scaricare tutto il codice e i dati, Clicca qui!!
Circa l'autore

Praveen Kumar Anwla
Ho lavorato come data scientist con società di revisione basate su prodotti e big. 4 per quasi 5 anni. Ho lavorato su diversi framework di PNL, Machine learning e deep learning all'avanguardia per risolvere i problemi aziendali. Non esitate a rivedere Il mio blog personale, dove tratterò argomenti dal machine learning: intelligenza artificiale, Chatbot agli strumenti di visualizzazione (Quadro, QlikView, eccetera.) e varie piattaforme cloud come Azure, IBM e il cloud AWS.





