Este artigo foi publicado como parte do Data Science Blogathon
No mundo atual impulsionado pela tecnologia, a cada segundo uma grande quantidade de dados é gerada. O monitoramento constante e a análise correta de tais dados são necessários para obter informações significativas e úteis..
Tempo real Dados do sensor, Dispositivos IoT, arquivos de log, redes sociais, etc. deve ser monitorado de perto e processado imediatamente. Portanto, para análise de dados em tempo real, precisamos de um mecanismo de transmissão de dados altamente escalonável, confiável e tolerante a falhas.
Transmissão de dados
O fluxo de dados é uma forma de coletar dados continuamente em tempo real de várias fontes de dados na forma de fluxos de dados.. Você pode pensar no Datastream como uma tabela que é continuamente agregada.
A transmissão de dados é essencial para lidar com grandes quantidades de dados ao vivo. Esses dados podem vir de uma variedade de fontes, como transações online, arquivos de log, sensores, atividades do jogador no jogo, etc.
Existem várias técnicas de transmissão de dados em tempo real, O que Apache KafkaO Apache Kafka é uma plataforma de mensagens distribuídas projetada para lidar com fluxos de dados em tempo real. Originalmente desenvolvido por LinkedIn, Oferece alta disponibilidade e escalabilidade, tornando-o uma escolha popular para aplicativos que exigem o processamento de grandes volumes de dados. O Kafka permite que os desenvolvedores publiquem, Assinar e armazenar logs de eventos, facilitando a integração do sistema e a análise em tempo real...., Spark Streaming, Apache FlumeFlume é um software de código aberto projetado para a recolha e transporte de dados. Utiliza uma abordagem baseada em fluxos, o que permite mover dados de várias fontes para sistemas de armazenamento como o Hadoop. Su arquitetura modular y escalable facilita la integración con múltiples orígenes de datos, lo que lo convierte en una herramienta valiosa para el procesamiento y análisis de grandes volúmenes de información en tiempo real.... etc. Neste post, vamos discutir a transmissão de dados usando Spark Streaming.
Spark Streaming
Spark Streaming é parte integrante de API central de Spark para realizar análises de dados em tempo real. Nos permite construir um aplicativo escalonável de transmissão ao vivo, alto desempenho e tolerante a falhas.
Spark Streaming suporta processamento de dados em tempo real de várias fontes de entrada e armazenamento dos dados processados em vários receptores de saída.
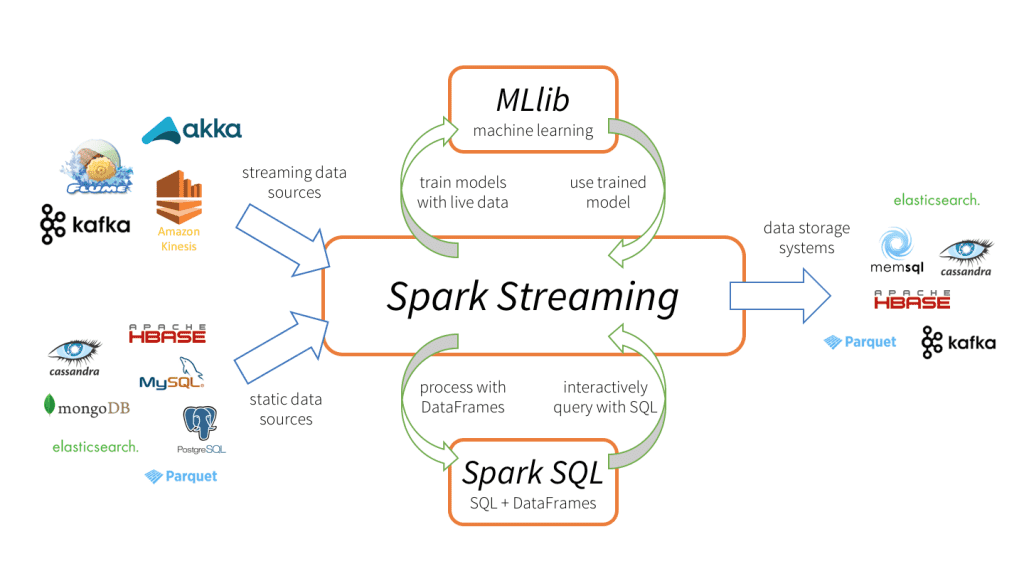
Spark Streaming tiene 3 componentes principais, como mostrado na imagem acima.
-
Fontes de dados de entrada: Fontes de dados de streaming (como Kafka, Flume, Kinesis, etc.), fontes de dados estáticos (como MySQL, MongoDB, Cassandra, etc.), sockets TCP, Twitter, etc.
-
Motor Spark Streaming: Para processar dados de entrada usando várias funções integradas, algoritmos complexos. O que mais, podemos verificar as transmissões ao vivo, aplicar aprendizado de máquina usando Spark SQL e MLlib respectivamente.
-
Pias de saída: Os dados processados podem ser armazenados em sistemas de arquivos, bases de dados (relacional e NoSQL), painéis ao vivo, etc.
Esses recursos exclusivos de processamento de dados, formato de entrada e saída fazem Spark Streaming mais atrativo, levando a uma rápida adoção.
Vantagens do Spark Streaming
-
Estrutura de transmissão unificada para todas as tarefas de processamento de dados (incluindo aprendizado de máquina, processamento gráfico, Operações SQL) em fluxos de dados ao vivo.
-
Balanceamento de carga dinâmico e melhor gerenciamento de recursos, equilibrando com eficiência a carga de trabalho entre os trabalhadores e iniciando a tarefa em paralelo.
-
Profundamente integrado com bibliotecas de processamento avançado como Spark SQL, MLlib, GraphX.
-
Recuperação mais rápida de falhas reiniciando tarefas com falha em paralelo em outros nós livres.
Noções básicas de streaming do Spark
O Spark Streaming divide os fluxos de dados de entrada ao vivo em lotes que são então processados por Motor de faísca.

DStream (fluxo discretizado)
DStream é uma abstração de alto nível fornecida pelo Spark Streaming, basicamente, significa o fluxo contínuo de dados. Pode ser criado a partir de fontes de dados de streaming (como Kafka, Flume, Kinesis, etc.) ou realizando operações de alto nível em outros DStreams.
Internamente, DStream é um fluxo RDD e este fenômeno permite que o Spark Streaming se integre com outros componentes do Spark, como MLlib, GraphX, etc.

Ao criar um aplicativo de streaming, também precisamos especificar a duração do lote para criar novos lotes em intervalos regulares de tempo. Normalmente, a duração do lote varia de 500 ms a vários segundos. Por exemplo, filho 3 segundos, então os dados de entrada são coletados a cada 3 segundos.
O Spark Streaming permite que você escreva código em linguagens de programação populares como Python, Scala e Java. Vamos dar uma olhada em um exemplo de aplicativo de streaming que usa o PySpark.
Aplicativo de amostra
Como discutimos anteriormente, Spark Streaming também permite receber fluxos de dados através de sockets TCP. Então, vamos escrever um programa de streaming simples para receber streams de texto em uma porta particular, realizar uma limpeza básica de texto (como remover espaços em branco, parar a remoção de palavras, lematización, etc.) e imprimir o texto limpo na tela.
Agora vamos começar a implementar isso seguindo as etapas abaixo.
1. Criar um contexto para transmitir e receber fluxos de dados
StreamingContext é o principal ponto de entrada para qualquer aplicativo de streaming. Ele pode ser criado instanciando StreamingContext classe de pyspark.streaming módulo.
de importação do pyspark SparkContext de pyspark.streaming import StreamingContext
Ao criar StreamingContext podemos especificar a duração do lote, por exemplo, aqui a duração do lote é 3 segundos.
sc = SparkContext(appName = "Limpeza de Texto") strc = StreamingContext(sc, 3)
Uma vez o StreamingContext é criado, podemos começar a receber dados na forma de DStream por meio do protocolo TCP em uma porta específica. Por exemplo, aqui o nome do host é especificado como “localhost” e a porta usada é 8084.
text_data = strc.socketTextStream("localhost", 8084)
2. Execução de operações em fluxos de dados
Depois de criar um DStream objeto, podemos realizar operações de acordo com os requisitos. Aqui, escrevemos uma função de limpeza de texto personalizada.
Esta função primeiro converte o texto de entrada em minúsculas, em seguida, remova os espaços extras, caracteres não alfanuméricos, links / URL, palavras irrelevantes e, em seguida, alterando o texto usando a biblioteca NLTK.
importar re
de nltk.corpus import stopwords
stop_words = set(stopwords.words('inglês'))
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
def clean_text(frase):
frase = frase.lower()
frase = re.sub("s +"," ", frase)
frase = re.sub("C"," ", frase)
frase = re.sub(r"httpS +", "", frase)
frase =" ".Junte(palavra por palavra em frase.() se a palavra não estiver em stop_words)
frase = [lemmatizer.lemmatize(símbolo, "v") para token em frase.split()]
frase = " ".Junte(frase)
return frase.strip()
3. Iniciar serviço de streaming
O serviço de streaming ainda não começou. Use o começar() função no topo do StreamingContext objeto para iniciá-lo e continuar a receber dados de transmissão até o comando de terminação (Ctrl + C o Ctrl + COM) não ser recebido por awaitTermination () Função.
strc.start() strc.awaitTermination()
NOTA – O código completo pode ser baixado de aqui.
Agora, primeiro temos que executar o ‘Carolina do Norte'comando (Netcat Utilitário) para enviar os dados de texto do servidor de dados para o servidor de streaming Spark. Netcat é um pequeno utilitário disponível em sistemas do tipo Unix para ler e escrever em conexões de rede através de portas TCP ou UDP. Suas duas opções principais são:
-
-eu: Deixar Carolina do Norte para ouvir uma conexão de entrada em vez de iniciar uma conexão com um host remoto.
-
-k: Dinheiro Carolina do Norte para ficar atento para outra conexão depois que a conexão atual for concluída.
Então execute o seguinte Carolina do Norte comando no terminal.
nc -lk 8083
de forma similar, execute o script pyspark em um terminal diferente usando o seguinte comando para realizar a limpeza de texto nos dados recebidos.
spark-submit streaming.py localhost 8083
De acordo com esta demonstração, qualquer texto digitado no terminal (correndo netcat servidor) será limpo e o texto limpo será impresso em outro terminal a cada 3 segundos (duração do lote).


Notas finais
Neste artigo, discutimos Spark Streaming, seus benefícios na transmissão de dados em tempo real e um aplicativo de amostra (utilizando sockets TCP) para receber fluxos de dados ao vivo e processá-los de acordo com os requisitos.
A mídia mostrada neste artigo sobre a implementação de modelos de aprendizado de máquina que tiram proveito do CherryPy e do Docker não é propriedade do DataPeaker e é usada a critério do autor.





