Introdução
De vez em quando, foi desenvolvida uma biblioteca Python que tem o potencial de mudar a paisagem no campo do aprendizado profundo. PyTorch é uma dessas bibliotecas.
Nas ultimas semanas, Eu tenho experimentado PyTorch um pouco. Fiquei impressionado com a facilidade de entender. Entre as várias estruturas de aprendizado profundo que usei até hoje, PyTorch tem sido o mais flexível e fácil de todos.
![]()
Neste artigo, vamos explorar PyTorch com uma abordagem mais prática, cobrindo o básico junto com um estudo de caso. Também compararemos uma rede neural construída do zero no numpy e no PyTorch para ver suas semelhanças na implementação..
Vamos continuar!
Observação: este artigo pressupõe que você tenha um conhecimento básico de aprendizado profundo. Se você quiser se atualizar no aprendizado profundo, leia este artigo primeiro.
O que mais, se você quiser uma explicação mais detalhada do PyTorch a partir do zero, entender como funcionam os tensores, como você pode realizar operações matemáticas e matriciais com PyTorch, Recomendo enfaticamente que você consulte o Guia para iniciantes em PyTorch e como funciona do zero.
Tabela de conteúdo
- Uma visão geral de PyTorch
- Mergulhe nos detalhes técnicos
- Construindo uma rede neural em Numpy vs. PyTorch
- Comparação com outras bibliotecas de aprendizagem profunda
- Estudo de caso: resolvendo um problema de reconhecimento de imagem com PyTorch
Se você preferir abordar os seguintes conceitos em um formato estruturado, Você pode se inscrever neste curso gratuito em PyTorch e siga-os por capítulos.
Uma visão geral de PyTorch
Os criadores do PyTorch dizem que têm uma filosofia: eles querem ser imperativos. Isso significa que executamos nosso cálculo imediatamente. Isso se encaixa perfeitamente na metodologia de programação Python, O que não temos que esperar que todo o código seja escrito antes de saber se funciona ou não. Podemos facilmente executar uma parte do código e inspecioná-lo em tempo real. Para mim, como um depurador de rede neural, Isso é uma benção!
PyTorch é uma biblioteca baseada em Python criada para fornecer flexibilidade como uma plataforma de desenvolvimento de aprendizagem profunda. O fluxo de trabalho do PyTorch é o que há de mais próximo da biblioteca de computação científica do Python: entorpecido.
Agora eu posso perguntar, Por que usaríamos o PyTorch para construir modelos de aprendizado profundo? Posso listar três coisas que podem ajudar a responder a isso:
- API fácil de usar – É tão simples quanto Python pode ser.
- Suporte Python – Como mencionado anteriormente, PyTorch se integra perfeitamente com a pilha de ciência de dados Python. É tão semelhante ao entorpecido que você pode nem notar a diferença.
- Gráficos de cálculo dinâmico – Em vez de gráficos predefinidos com funcionalidades específicas, PyTorch fornece uma estrutura para construirmos gráficos computacionais à medida que avançamos, e nós até os mudamos durante o tempo de execução. Isso é valioso para situações em que não sabemos quanta memória será necessária para criar uma rede neural..
Algumas outras vantagens de usar PyTorch são seu suporte multiGPU, carregadores de dados personalizados e pré-processadores simplificados.
Desde o seu lançamento no início de janeiro 2016, muitos pesquisadores a adotaram como uma biblioteca de referência devido à sua facilidade na criação de gráficos novos e até extremamente complexos. Dito isto, ainda falta algum tempo antes que o PyTorch seja adotado pela maioria dos profissionais de ciência de dados devido ao seu novo e “em construção”.
Mergulhe nos detalhes técnicos
Antes de mergulharmos nos detalhes, vamos ver o fluxo de trabalho do PyTorch.
PyTorch usa um paradigma imperativo / ansioso. Quer dizer, cada linha de código necessária para construir um gráfico define um componente desse gráfico. Podemos realizar cálculos independentemente sobre esses componentes, mesmo antes de seu gráfico estar totalmente construído. Isso é chamado de “definição por execução”.

Fonte: http://pytorch.org/about/
Instalar o PyTorch é muito fácil. Você pode seguir as etapas mencionadas no documentos oficiais e execute o comando de acordo com as especificações do seu sistema. Por exemplo, este foi o comando que usei com base nas opções que escolhi:
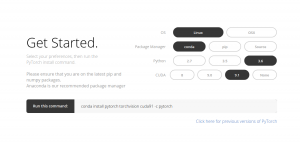
conda install pytorch torchvision cuda91 -c pytorch
Os principais elementos que devemos saber ao começar com PyTorch são:
- Tensores PyTorch
- Operações matemáticas
- Módulo de autoavaliação
- Módulo Optim e
- modul nn
A seguir, vamos dar uma olhada em cada um deles com alguns detalhes.
Tensores PyTorch
Tensores nada mais são do que matrizes multidimensionais. Os tensores em PyTorch são semelhantes aos ndarrays em numpy, com a adição de que os tensores também podem ser usados em uma GPU. Compatível com PyTorch vários tipos de tensores. Se você estiver familiarizado com outras estruturas de aprendizado profundo, também deve ter encontrado tensores no TensorFlow. De fato, você também pode implementar as seguintes tarefas no Tensorflow e fazer sua própria comparação entre PyTorch e TensorFlow.
Você pode definir uma matriz unidimensional simples, conforme mostrado abaixo:
# import pytorch importar tocha # definir um tensor tocch.FloatTensor([2])
2 [tocha.FloatTensor de tamanho 1]
Operações matemáticas
Tal como acontece com entorpecido, é muito importante que uma biblioteca de computação científica tenha implementações eficientes de funções matemáticas. PyTorch oferece uma interface semelhante, com mais de 200 operações matemáticas você pode usar.
Abaixo está um exemplo de uma operação de adição simples em PyTorch:
a = torch.FloatTensor([2]) b = tocch.FloatTensor([3]) uma + b
5 [tocha.FloatTensor de tamanho 1]
Isso não parece uma abordagem Python essencial? Também podemos realizar várias operações de matriz nos tensores PyTorch que definimos. Por exemplo, vamos transpor uma matriz bidimensional:
matrix = torch.randn(3, 3) matriz 0.7162 1.0152 1.1525 -0.3503 -0.9452 -1.0861 -0.1093 -0.0927 -0.0476 [tocha.FloatTensor de tamanho 3x3] matrix.t() 0.7162 -0.3503 -0.1093 1.0152 -0.9452 -0.0927 1.1525 -1.0861 -0.0476 [tocha.FloatTensor de tamanho 3x3]
Módulo de autoavaliação
PyTorch usa uma técnica chamada diferenciação automática. Quer dizer, temos um gravador que grava as operações que realizamos e as reproduz para calcular nossos gradientes. Esta técnica é especialmente poderosa ao construir redes neurais, uma vez que economizamos tempo em uma época ao calcular a diferenciação dos parâmetros na passagem direta.
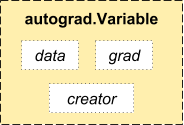
Fonte: http://pytorch.org/about/
from torch.autograd import Variável x = Variável(train_x) y = variável(train_y, requer_grad = falso)
Módulo ideal
torch.optim é um módulo que implementa vários algoritmos de otimização usados para construir redes neurais. A maioria dos métodos mais comumente usados já são suportados, então não temos que criá-los do zero (A não ser que você queira!).
Abaixo está o código para usar um otimizador Adam:
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
modul nn
PyTorch o autograd facilita a definição de gráficos computacionais e a obtenção de gradientes, mas o autogrado bruto pode ser um nível muito baixo para definir redes neurais complexas. É aqui que o módulo nn pode ajudar.
O pacote nn define um conjunto de módulos, que podemos considerar como uma camada de rede neural que produz uma saída da entrada e pode ter alguns pesos treináveis.
Você pode considerar um módulo nn como o duro de PyTorch!
importar tocha # definir modelo model = torch.nn.Sequential( torch.nn.Linear(input_num_units, unidades_de_num_ocultas), torch.nn.ReLU(), torch.nn.Linear(unidades_de_num_ocultas, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss()
Agora que você conhece os componentes básicos do PyTorch, você pode facilmente construir sua própria rede neural do zero. Siga-o se quiser saber como!
Construindo uma rede neural em Numpy vs. PyTorch
Mencionei acima que PyTorch e Numpy são muito semelhantes. Vamos ver porque. Nesta secção, veremos uma implementação de uma rede neural simples para resolver um problema de classificação binária (você pode ler este artigo para uma explicação detalhada).
## Rede neural em numpy
importar numpy como np
#Input array
X = np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Saída
y = np.array([[1],[1],[0]])
#Função sigmóide
def sigmóide (x):
Retorna 1/(1 + np.exp(-x))
#Derivada da função sigmóide
def derivados_sigmoid(x):
retornar x * (1 - x)
#Inicialização de variável
epoch = 5000 #Definindo iterações de treinamento
lr = 0.1 #Definindo a taxa de aprendizagem
inputlayer_neurons = X.shape[1] #número de recursos no conjunto de dados
hiddenlayer_neurons = 3 #número de camadas ocultas de neurônios
output_neurons = 1 #número de neurônios na camada de saída
#peso e inicialização de polarização
wh = np.random.uniform(tamanho =(inputlayer_neurons,hiddenlayer_neurons))
bh = np.random.uniform(tamanho =(1,hiddenlayer_neurons))
wout = np.random.uniform(tamanho =(hiddenlayer_neurons,output_neurons))
bout = np.random.uniform(tamanho =(1,output_neurons))
para eu no alcance(época):
#Propagação para a frente
entrada_camada_oculta1 = np.dot(X,wh)
hidden_layer_input = hidden_layer_input1 + bh
hiddenlayer_activations = sigmoid(hidden_layer_input)
output_layer_input1 = np.dot(hiddenlayer_activations,estrada)
output_layer_input = output_layer_input1 + ataque
output = sigmóide(output_layer_input)
#Retropropagação
E = saída y
slope_output_layer = derivados_sigmoid(saída)
slope_hidden_layer = derivados_sigmoid(hiddenlayer_activations)
d_output = E * slope_output_layer
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout + = hiddenlayer_activations.T.dot(d_output) *lr
bout + = np.sum(d_output, eixo = 0, keepdims = True) *lr
wh + = X.T.dot(d_hiddenlayer) *lr
bh + = np.sum(d_hiddenlayer, eixo = 0, keepdims = True) *lr
imprimir('real :n ', e, 'n')
imprimir('previsto :n ', saída)
Agora, tente detectar a diferença em uma implementação super simples do mesmo em PyTorch (as diferenças são mencionadas em negrito no código a seguir).
## rede neural em pytorch
importar tocha
#Matriz de entrada
X = tocha.Tensor([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
#Saída
y = tocha.Tensor([[1],[1],[0]])
#Função sigmóide
def sigmóide (x):
Retorna 1/(1 + torch.exp(-x))
#Derivada da função sigmóide
def derivados_sigmoid(x):
retornar x * (1 - x)
#Inicialização de variável
epoch = 5000 #Definindo iterações de treinamento
lr = 0.1 #Definindo a taxa de aprendizagem
inputlayer_neurons = X.shape[1] #número de recursos no conjunto de dados
hiddenlayer_neurons = 3 #número de camadas ocultas de neurônios
output_neurons = 1 #número de neurônios na camada de saída
#peso e inicialização de polarização
wh =torch.randn(inputlayer_neurons, hiddenlayer_neurons).modelo(tocch.FloatTensor)
bh =torch.randn(1, hiddenlayer_neurons).modelo(tocch.FloatTensor)
estrada =torch.randn(hiddenlayer_neurons, output_neurons)
luta =torch.randn(1, output_neurons)
para eu no alcance(época):
#Propagação para a frente
hidden_layer_input1 = tocha.mm(X, wh)
hidden_layer_input = hidden_layer_input1 + bh
hidden_layer_activations = sigmóide(hidden_layer_input)
output_layer_input1 = tocha.mm(atividades_camadas_ocultas, estrada)
output_layer_input = output_layer_input1 + ataque
output = sigmóide(output_layer_input1)
#Retropropagação
E = saída y
slope_output_layer = derivados_sigmoid(saída)
slope_hidden_layer = derivados_sigmoid(atividades_camadas_ocultas)
d_output = E * slope_output_layer
Error_at_hidden_layer = tocha.mm(d_output, wout.t())
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout + = tocha.mm(hidden_layer_activations.t(), d_output) *lr
ataque + = d_output.sum() *lr
wh + = tocha.mm(X.t(), d_hiddenlayer) *lr
bh + = d_output.sum() *lr
imprimir('real :n ', e, 'n')
imprimir('previsto :n ', saída)
Comparação com outras bibliotecas de aprendizagem profunda
Em um script de benchmarking, PyTorch demonstrou com sucesso superar todas as outras grandes bibliotecas de aprendizagem profunda no treinamento de uma rede de memória de longo e curto prazo (LSTM) tendo o menor tempo mediano por época (consulte a imagem abaixo).

APIs para carregamento de dados são bem projetadas no PyTorch. As interfaces são especificadas em um conjunto de dados, um amostrador e um carregador de dados.
Ao comparar ferramentas para carregamento de dados no TensorFlow (leitores, colas, etc.), eu encontrei PyTorchMódulos de carregamento de dados são bastante fáceis de usar. O que mais, PyTorch é perfeito ao tentar construir uma rede neural, para que não tenhamos que depender de bibliotecas de terceiros de alto nível, como keras.
Por outro lado, Eu ainda não recomendaria usar PyTorch para implementação. PyTorch ainda não evoluiu. Como os desenvolvedores do PyTorch disseram, “O que estamos vendo é que os usuários primeiro criam um modelo PyTorch. Quando eles estiverem prontos para implantar seu modelo na produção, basta torná-lo um modelo Caffe 2 e então eles enviam para uma plataforma móvel ou outra ".
Estudo de caso: Resolvendo um problema de reconhecimento de imagem em PyTorch
Para se familiarizar com o PyTorch, vamos resolver o problema de prática de aprendizagem profunda do DataPeaker: Identifique os dígitos. Vamos dar uma olhada em nossa declaração de problema:
Nosso problema é um problema de reconhecimento de imagem, para identificar os dígitos de uma determinada imagem de 28 x 28. Temos um subconjunto de imagens para treinamento e o resto para testar nosso modelo.
Primeiro, baixe o trem e os arquivos de teste. O conjunto de dados contém um arquivo compactado de todas as imagens e train.csv e test.csv são nomeados de acordo com o trem e as imagens de teste correspondentes. Recursos adicionais não são fornecidos nos conjuntos de dados, apenas imagens brutas são fornecidas no formato ‘.png’.
Vamos começar:
PASO 0: Preparando-se
uma) Importar todas as bibliotecas necessárias
# módulos de importação % pylab inline importar os importar numpy como np importar pandas como pd de scipy.misc import imread de sklearn.metrics import precision_score
b) Vamos definir um valor de semente, para que possamos controlar a aleatoriedade de nossos modelos
# Para parar a aleatoriedade potencial semente = 128 rng = np.random.RandomState(semente)
c) A primeira etapa é definir os caminhos do diretório, Para sua proteção!
root_dir = os.path.abspath('.')
data_dir = os.path.join(root_dir, 'dados')
# verificar a existência
os.path.exists(root_dir), os.path.exists(data_dir)
PASO 1: Carregamento e pré-processamento de dados
uma) Agora vamos ler nossos conjuntos de dados. Eles estão em formatos .csv e têm um nome de arquivo junto com as tags correspondentes.
# carregar conjunto de dados train = pd.read_csv(os.path.join(data_dir, 'Trem', 'train.csv')) test = pd.read_csv(os.path.join(data_dir, 'Test.csv')) sample_submission = pd.read_csv(os.path.join(data_dir, 'Sample_Submission.csv')) train.head()
| nome do arquivo | rótulo | |
|---|---|---|
| 0 | 0.png | 4 |
| 1 | 1.png | 9 |
| 2 | 2.png | 1 |
| 3 | 3.png | 7 |
| 4 | 4.png | 3 |
b) Vamos ver como são nossos dados!! Nós lemos nossa imagem e mostramos.
# imprimir uma imagem
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'Trem', 'Imagens', 'Comboio', img_name)
img = imread(caminho de arquivo, flatten = True)
pylab.imshow(img, cmap = 'cinza')
pilab.axis('desligado')
pylab.show()

d) Para facilitar a manipulação de dados, nós armazenamos todas as nossas imagens como matrizes entorpecidas
# carregar imagens para criar trem e conjunto de teste
temp = []
para img_name em train.filename:
image_path = os.path.join(data_dir, 'Trem', 'Imagens', 'Comboio', img_name)
img = imread(caminho_da_imagem, flatten = True)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temp)
train_x / = 255.0
train_x = train_x.reshape(-1, 784).astype('float32')
temp = []
para img_name em test.filename:
image_path = os.path.join(data_dir, 'Trem', 'Imagens', 'teste', img_name)
img = imread(caminho_da_imagem, flatten = True)
img = img.astype('float32')
temp.append(img)
test_x = np.stack(temp)
test_x / = 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = train.label.values
e) Como é um problema típico de AA, para testar o funcionamento correto do nosso modelo, criamos um conjunto de validação. Vamos pegar um tamanho de divisão de 70:30 para o conjunto de trens versus o conjunto de validação
# criar conjunto de validação split_size = int(train_x.shape[0]*0.7) train_x, val_x = train_x[:split_size], train_x[split_size:] train_y, val_y = train_y[:split_size], train_y[split_size:]
PASO 2: Construção de maquete
uma) Agora vem a parte principal! Vamos definir nossa arquitetura de rede neural. Definimos uma rede neural com 3 camadas de entrada, escondido e saia. O número de neurônios de entrada e saída é fixo, uma vez que a entrada é a nossa imagem de 28 x 28 e a saída é um vetor de 10 x 1 o que a classe representa. Nós levamos 50 neurônios na camada oculta. Aqui usamos Adão como nossos algoritmos de otimização, que é uma variante eficiente do algoritmo Gradient Descent.
importar tocha from torch.autograd import Variável
# número de neurônios em cada camada input_num_units = 28*28 hidden_num_units = 500 output_num_units = 10 # definir as variáveis restantes épocas = 5 batch_size = 128 learning_rate = 0.001
b) É hora de treinar nosso modelo
# definir modelo model = torch.nn.Sequential( torch.nn.Linear(input_num_units, unidades_de_num_ocultas), torch.nn.ReLU(), torch.nn.Linear(unidades_de_num_ocultas, output_num_units), ) loss_fn = torch.nn.CrossEntropyLoss() # definir algoritmo de otimização optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate)
## funções auxiliares
# pré-processar um lote de conjunto de dados
def preproc(impuro_batch_x):
"""Converter valores para intervalo 0-1"""
temp_batch = unclean_batch_x / unclean_batch_x.max()
return temp_batch
# criar um lote
def batch_creator(tamanho do batch):
dataset_name ="Comboio"
dataset_length = train_x.shape[0]
batch_mask = rng.choice(dataset_length, tamanho do batch)
batch_x = eval(dataset_name + '_x')[batch_mask]
batch_x = preproc(batch_x)
if dataset_name == 'train':
batch_y = eval(dataset_name).ix[batch_mask, 'rótulo'].valores
retornar batch_x, batch_y
# rede de trem
total_batch = int(train.shape[0]/tamanho do batch)
para época no intervalo(épocas):
avg_cost = 0
para eu no alcance(total_batch):
# criar lote
batch_x, batch_y = batch_creator(tamanho do batch)
# passe aquele lote para treinamento
x, y = variável(torch.from_numpy(batch_x)), Variável(torch.from_numpy(batch_y), requer_grad = falso)
antes = modelo(x)
# obter perda
perda = perda_fn(pred, e)
# realizar retropropagação
loss.backward()
optimizer.step()
avg_cost + = loss.data[0]/total_batch
imprimir(época, avg_cost)
# obter precisão de treinamento x, y = variável(torch.from_numpy(preproc(train_x))), Variável(torch.from_numpy(train_y), requer_grad = falso) antes = modelo(x) final_pred = np.argmax(pred.data.numpy(), eixo = 1) precisão_pontuação(train_y, final_pred)
# obter precisão de validação x, y = variável(torch.from_numpy(preproc(val_x))), Variável(torch.from_numpy(val_y), requer_grad = falso) antes = modelo(x) final_pred = np.argmax(pred.data.numpy(), eixo = 1) precisão_pontuação(val_y, final_pred)
A pontuação do treinamento acabou sendo:
0.8779008746355685
enquanto a pontuação de validação é:
0.867482993197279
Esta é uma pontuação impressionante!, especialmente quando treinamos uma rede neural muito simples por apenas cinco épocas!
Notas finais
Espero que este artigo tenha dado uma ideia de como a estrutura PyTorch pode mudar a perspectiva da construção de modelos de aprendizagem profunda. Neste artigo, nós apenas arranhamos a superfície. Aprofundar, você pode leia a documentação e tutoriais na própria página oficial de PyTorch.
Nos próximos artigos, eu vou aplicar PyTorch para análise de áudio e tentaremos criar modelos de aprendizagem profunda para processamento de fala. Fique ligado!
Você usou o PyTorch para construir um aplicativo ou em algum de seus projetos de ciência de dados? Deixe-me saber nos comentários abaixo..





