Introdução:
Neste artigo, aprenderemos todos os conceitos estatísticos importantes que são necessários para funções de ciência de dados.
Tabela de conteúdo:
- Diferença entre parâmetro e estatística
- Estatísticas e seus tipos
- Tipos de dados e níveis de medição
- Momentos de decisão de negócios
- Teorema do limite central (CLT)
- Distribuições de probabilidade
- Representações gráficas
- Testando hipóteses
1. Diferença entre parâmetro e estatística
No nosso dia a dia continuamos falando sobre População e shows. Então, é muito importante conhecer a terminologia para representar a população e a amostra.
Um parâmetro é um número que descreve os dados da população. E uma estatística é um número que descreve os dados em uma amostra.
2. Estatísticas e seus tipos
A definição de Estatísticas da Wikipedia afirma que “é uma disciplina que trata da compilação, organização, análise, interpretação e apresentação de dados”.
Significa que, como parte da análise estatística, nós coletamos, organizar e extrair informações significativas dos dados, seja por meio de visualizações ou explicações matemáticas.
As estatísticas são amplamente classificadas em dois tipos:
- Estatísticas descritivas
- Estatística inferencial
Estatísticas descritivas:
Como o nome sugere em Estatísticas Descritivas, Descrevemos os dados usando as distribuições médias, Desvio padrão, Gráficos ou probabilidade.
Basicamente, como parte das estatísticas descritivas, nós medimos o seguinte:
- Frequência: não. número de vezes que um ponto de dados ocorre
- Tendência central: a centralidade dos dados: meios de comunicação, meio e modo.
- Dispersão: a extensão dos dados: classificação, variância e desvio padrão
- A medida da posição: percentis e intervalos de quantis
Estatística inferencial:
Em estatísticas inferenciais, nós estimamos os parâmetros populacionais. Ou realizamos testes de hipóteses para avaliar as suposições feitas sobre os parâmetros populacionais..
Em termos simples, interpretamos o significado das estatísticas descritivas inferindo-as para a população.
Por exemplo, estamos conduzindo uma pesquisa sobre o número de veículos de duas rodas em uma cidade. Suponha que a cidade tenha uma população total de 5L de pessoas. Portanto, pegamos uma amostra de 1000 pessoas, pois é impossível realizar uma análise de todos os dados da população.
Da pesquisa realizada, é encontrado que 800 pessoas de 1000 (800 a partir de 1000 isto é 80%) eles são veículos de duas rodas. Então, podemos inferir esses resultados para a população e concluir que as pessoas 4L da população 5L são duas rodas.
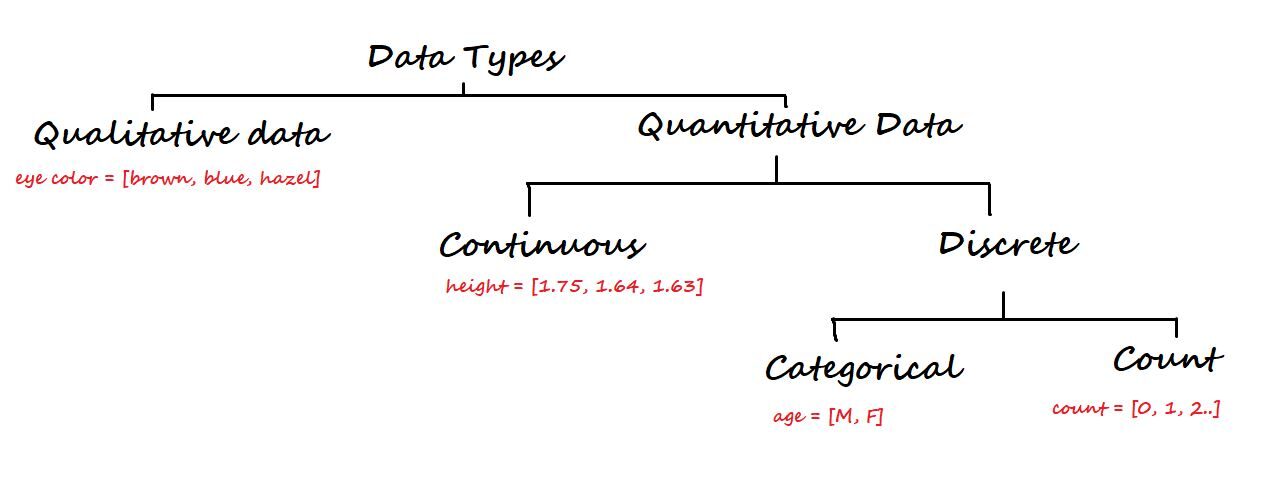
3. Tipos de dados e nível de medição
Em um nível superior, os dados são classificados em dois tipos: Qualitativo e Quantitativo.
Os dados qualitativos não são numéricos. Alguns dos exemplos são a cor dos olhos, Marca de carro, a cidade, etc.
Por outro lado, os dados quantitativos são numéricos e novamente divididos em dados contínuos e discretos.
Dados contínuos: Pode ser representado em formato decimal. Alguns exemplos são altura, peso, clima, distância, etc.
Dados discretos: Não pode ser representado em formato decimal. Alguns exemplos são o número de laptops, o número de alunos em uma classe.
Os dados discretos são divididos em dados categóricos e de contagem.
Dados categóricos: representam o tipo de dados que podem ser divididos em grupos. Alguns exemplos são idade, sexo, etc.
Dados de contagem: Esses dados contêm inteiros não negativos. Exemplo: número de filhos que um parceiro tem.
Nível de medição
Nas estatísticas, o nível de medição é uma classificação que descreve a relação entre os valores de uma variável.
Temos quatro níveis fundamentais de medição. Filho:
- Escala nominal
- Escala ordinal
- Escala de intervalo
- Escala de proporção
1. Escala nominal: Esta escala contém a menor quantidade de informações, uma vez que os dados só têm nomes / rótulos. Pode ser usado para classificação. Não podemos realizar operações matemáticas em dados nominais porque não há valor numérico para as opções (os números associados aos nomes só podem ser usados como rótulos).
Exemplo: A que país você pertence? Índia, Japão, Coréia.
2. Escala ordinal: Comparado com a escala nominal, a escala ordinal tem mais informações porque junto com os rótulos, tem ordem / Morada.
Exemplo: Nível de renda: alta renda, renda média, baixa renda.
3. Escala de intervalo: É uma escala numérica. A escala de intervalo tem mais informações do que as escalas ordinais nominais. Junto com o pedido, nós sabemos a diferença entre as duas variáveis (o intervalo indica a distância entre duas entidades).
A média pode ser usada, a mediana e o modo para descrever os dados.
Exemplo: temperatura, renda, etc.
4. Escala de razão: A escala de proporção tem mais informações sobre os dados. Ao contrário das outras três escalas, a escala de razão pode acomodar um verdadeiro ponto zero. Diz-se simplesmente que a escala de razão é a combinação de escalas nominais, Ordinal e Intercal.
Exemplo: peso atual, altura, etc.
4. Momentos de decisão de negócios
Temos quatro momentos de decisão de negócios que nos ajudam a entender os dados.
4.1. Medidas de tendência central
(Também conhecido como uma decisão de negócios em primeiro lugar)
Fale sobre a centralidade dos dados. Para simplificarlo, faz parte da análise estatística descritiva em que um único valor no centro representa todo o conjunto de dados.
A tendência central de um conjunto de dados pode ser medida por:
Significar: É a soma de todos os pontos de dados dividida pelo número total de valores no conjunto de dados. A média nem sempre é confiável porque é influenciada por outliers.
Mediana: É o valor intermediário de um conjunto de dados ordenado / limpo. Se o tamanho do conjunto de dados for uniforme, a mediana é calculada tomando a média dos dois valores médios.
Caminho: É o valor mais repetido no conjunto de dados. Dados com apenas um modo são chamados de unimodal, dados com dois modos são chamados de bimodais e dados com mais de dois modos são chamados de multimodais.
4.2. Medidas de dispersão
(Também conhecido como uma segunda decisão de negócios)
Fale sobre a disseminação de dados do seu centro.
A dispersão pode ser medida usando:
Diferença: É a distância quadrada média de todos os pontos de dados de sua média. O problema com a variância é que as unidades também serão quadradas.
Desvio padrão: É a raiz quadrada da variância. Ajuda a recuperar unidades originais.
Distância: É a diferença entre os valores máximo e mínimo de um conjunto de dados.
A medida |
População |
Shows |
| Significar | µ = (Σ Xeu)/NORTE | x̄ = (Σ xeu)/Norte |
| Mediana | O valor médio dos dados | O valor médio dos dados |
| Caminho | Valor mais ocorrido | Valor mais ocorrido |
| Diferença | σ2 = (Σ Xeu – µ)2/NORTE | s2 = (Σ xeu – X )2/ (n-1) |
| Desvio padrão | σ = raiz quadrada ((Σ Xeu – µ)2/NORTE) | s = raiz quadrada ((Σ xeu – X )2/ (n-1)) |
| Distância | Máximo mínimo | Máximo mínimo |
4.3. Obliquidade
(Também é conhecido como uma decisão de negócios no terceiro momento)
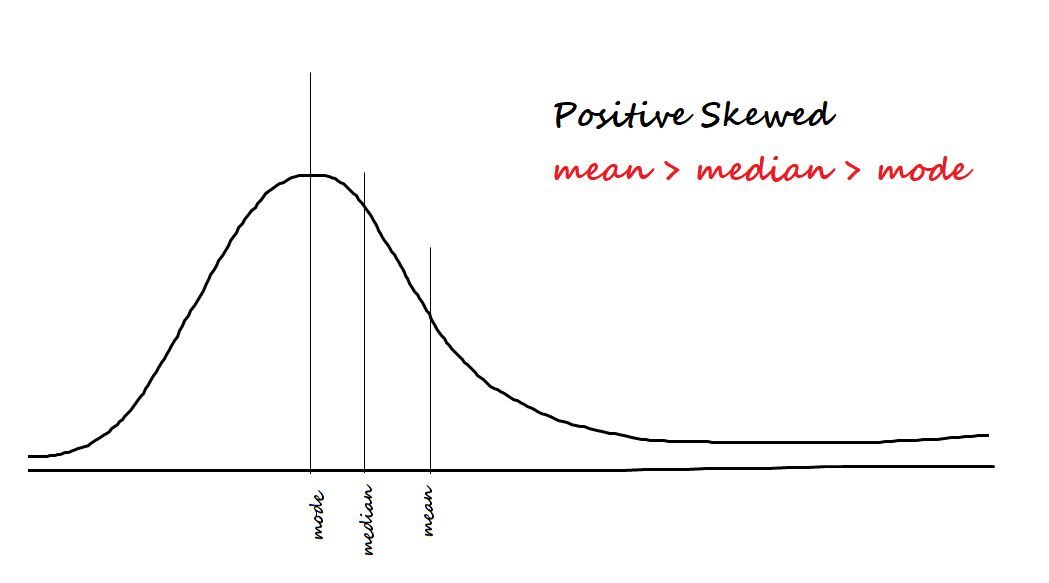
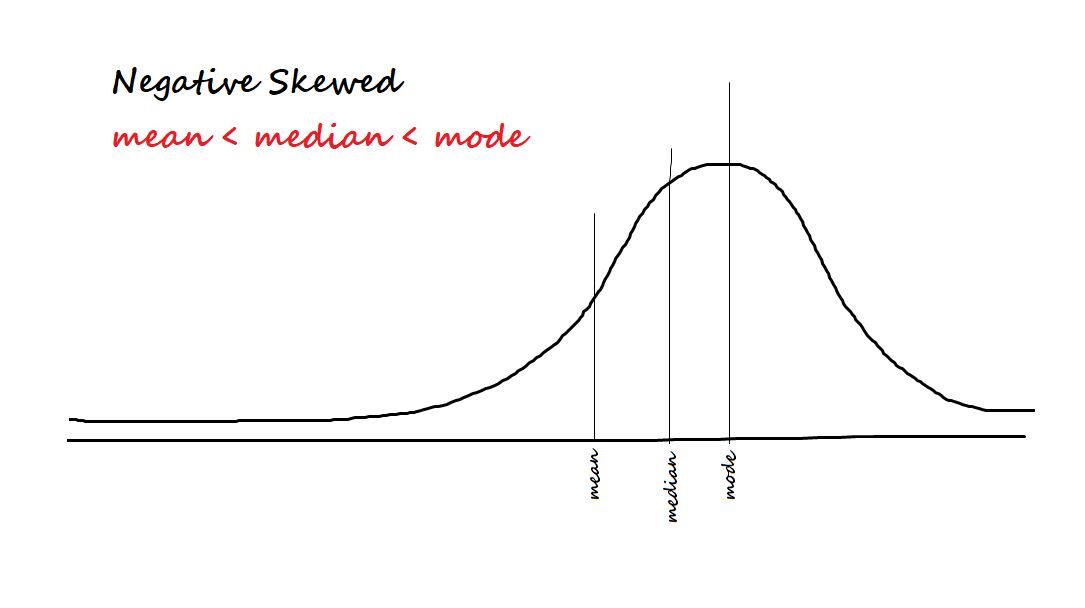
Medir assimetria nos dados. Os dois tipos de assimetria são:
Positivo / inclinado para a direita: Os dados são considerados positivamente tendenciosos se a maioria dos dados estiver concentrada no lado esquerdo e tiver uma cauda à direita.
Negativo / inclinado para a esquerda: Os dados são considerados enviesados negativamente se a maioria dos dados estiver concentrada no lado direito e tiver uma cauda à esquerda.
A fórmula de assimetria é mim [(X - µ)/ σ ]) 3 = Z3
4.4. Curtosis
(Também conhecido como decisão de negócios de quarto momento)
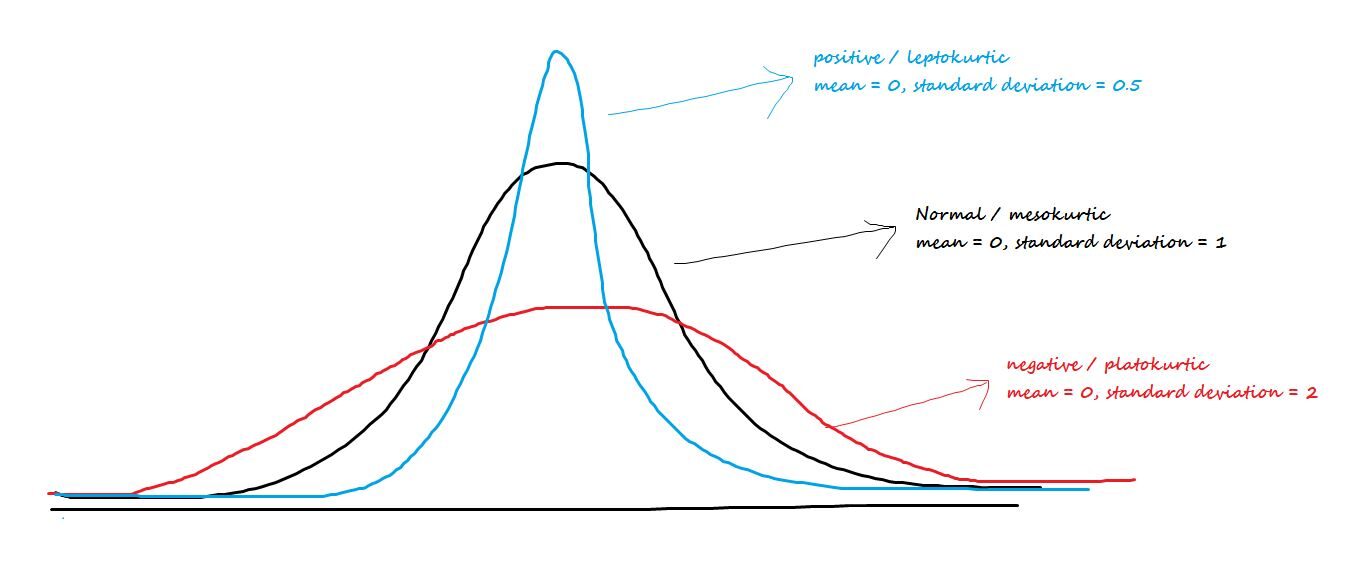
Fale sobre o pico central ou a maciez das caudas. Os três tipos de curtose são:
Positivo / leptocúrtico: Tem bicos pontiagudos e caudas mais claras.
Negativo / Platokúrtico: Tem bicos largos e caudas mais grossas.
Mesocúrtico: Distribuição normal
A fórmula de curtose é mim [(X - µ)/ σ ]) 4-3 = Z4– 3
Juntos, assimetria e curtose são chamadas de estatísticas de forma.
5. Teorema do limite central (CLT)
Em vez de analisar os dados de toda a população, nós sempre pegamos uma amostra para análise. O problema com a amostragem é que "a média da amostra é uma variável aleatória, varia para diferentes amostras ". E a amostra aleatória que extraímos nunca pode ser uma representação exata da população. Este fenômeno é chamado de variação da amostra.
Para cancelar a variação da amostra, usamos o teorema do limite central. E de acordo com o teorema do limite central:
1. A distribuição das médias da amostra segue uma distribuição normal se a população for normal.
2. a distribuição das médias da amostra segue uma distribuição normal, embora a população não seja normal. Mas o tamanho da amostra deve ser grande o suficiente.
3. A grande média de todos os valores médios da amostra nos dá a média da população.
4. Teoricamente, o tamanho da amostra deve ser 30. E praticamente, a condição sobre o tamanho da amostra (n) isto é:
n> 10 (k3)2, onde k3 é a assimetria da amostra.
n> 10 (k4), onde K4 é a amostra de curtose.
6. Distribuições de probabilidade
Em termos estatísticos, uma função de distribuição é uma expressão matemática que descreve a probabilidade de diferentes resultados possíveis para um experimento.
Por favor, leia este meu artigo sobre os diferentes tipos de distribuições de probabilidade.
7. Representações gráficas
A representação gráfica refere-se ao uso de tabelas ou gráficos para visualizar, analisar e interpretar dados numéricos.
Para uma única variável (análise univariada), nós temos um gráfico de barras, um diagrama de linha, um diagrama de frequência, um gráfico de pontos, um gráfico de caixa e o gráfico QQ normal.
Vamos discutir o gráfico de caixa e o gráfico QQ normal.
7.1. Box plot
Um gráfico de caixa é uma maneira de visualizar a distribuição de dados com base em um resumo de cinco números. Usado para identificar outliers nos dados.
Os cinco números são mínimos, primeiro quartil (T1), mediana (Q2), terceiro quartil (3º T) e máximo.
A região da caixa conterá o 50% dos dados. o 25% a parte inferior da região de dados é chamada de Whisker inferior e a parte inferior 25% topo da região de dados é chamado Top Whisker.
A região interquartil (IQR) é a diferença entre o terceiro e o primeiro quartil. IQR = Q3 – T1.
Outliers são os pontos de dados abaixo do bigode inferior e além do bigode superior.
A fórmula para encontrar os outliers é Outlier = Q ± 1,5 * (IQR)
Outliers abaixo do bigode inferior são dados como T1 – 1,5 * (IQR)
Outliers além do bigode superior são dados como 3º T + 1.5 * (IQR)
Veja meu artigo sobre a detecção de outliers usando um gráfico de caixa.
7.2. Gráfico QQ normal
Um diagrama QQ normal é um tipo de diagrama de dispersão desenhado pela criação de dois conjuntos de quantis.. É usado para verificar se os dados são normais ou não.
No eixo x temos as pontuações Z e no eixo y temos os quantis reais da amostra. Se o gráfico de dispersão formar uma linha reta, os dados são considerados normais.
8. Testando hipóteses
O teste de hipóteses em estatísticas é uma forma de testar as suposições feitas sobre os parâmetros populacionais.
Veja meu artigo sobre teste de hipótese para lê-lo em detalhes.
Notas finais:
Obrigado por ler até a conclusão. No final deste artigo, estamos familiarizados com conceitos estatísticos importantes.
Espero que este artigo seja informativo. Sinta-se à vontade para compartilhar com seus colegas estudantes.
Outros posts meus
Sinta-se à vontade para verificar minhas outras postagens do meu perfil do DataPeaker.
Você pode me encontrar em LinkedIn, Twitter no caso de você querer se conectar. Eu adoraria me conectar com você.
Para uma troca imediata de pensamentos, escreva para mim [e-mail protegido].
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





