Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
Nós vamos! Todos nós amamos bolos. Se você der uma olhada mais de perto no processo de cozimento, você notará como a combinação certa de vários ingredientes e um agente de levedura inteligente, fermento em pó, você pode decidir a ascensão e queda do seu bolo.
“Asse o bolo” pode parecer deslocado no white paper, mas acho que é bastante identificável e uma analogia deliciosa para entender a importância da EDA no processo de ciência de dados.
Ao assar o bolo é para pipeline de ciência de dados, entonces Agente de Fermento Inteligente (fermento em pó) é para análise exploratória de dados.
Antes que você fique com água na boca por um bolo como o meu, vamos entender.
O que exatamente é análise exploratória de dados?
A análise exploratória de dados é uma abordagem de análise de dados que emprega uma variedade de técnicas para:
- Obtenha informações sobre os dados.
- Faça verificações de sanidade. (Para ter certeza de que os insights que extraímos vêm realmente do conjunto de dados correto).
- Descubra onde faltam dados.
- Verifique se há outliers.
- Resuma os dados.
Pegue o famoso estudo de caso de “VENDAS DE SEXTA-FEIRA PRETA” para compreender, Por que precisamos de EDA?

O problema central é entender o comportamento do cliente ao prever o valor da compra. Mas, Não é muito abstrato e deixa você perplexo sobre o que fazer com os dados, especialmente quando você tem tantos produtos diferentes com várias categorias?
Antes de continuar lendo, pense um pouco sobre esta questão: Você colocaria todos os ingredientes disponíveis na cozinha já que está no forno para assar o bolo?
Obviamente, a resposta é não! Antes de pegar o conjunto de dados completo, pois é necessário cozinhá-lo no modelo de aprendizado de máquina, vai querer
- Extraia informações importantes
- Identificação de variável (se os dados contêm variáveis categóricas ou numéricas ou uma combinação de ambas).
- O comportamento das variáveis (se as variáveis têm valores de 0 uma 10 tributo 0 uma 1 milhão).
- Relação entre variáveis (como as variáveis dependem umas das outras).
-
Verifique a consistência dos dados
- Para garantir que todos os dados estejam presentes. (Se tivermos coletado dados por três anos, qualquer semana em falta pode ser um problema em fases posteriores).
- Existe algum valor ausente presente?
- Existem outliers no conjunto de dados? (por exemplo: uma pessoa com 2000 anos é definitivamente uma anomalia)
- Engenharia de funções
- Engenharia de recursos (para criar novos recursos a partir de recursos brutos existentes no conjunto de dados).
** EDA, em essência, pode quebrar ou fazer qualquer modelo de aprendizado de máquina. **
Etapas na análise exploratória de dados

Existem 5 etapas em EDA: ->
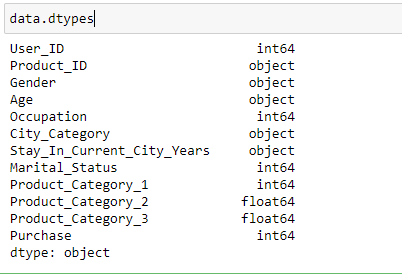
- Identificação de variável: Nesta etapa, nós identificamos cada variável descobrindo seu tipo. De acordo com nossas necessidades, podemos mudar o tipo de dados de qualquer variável.

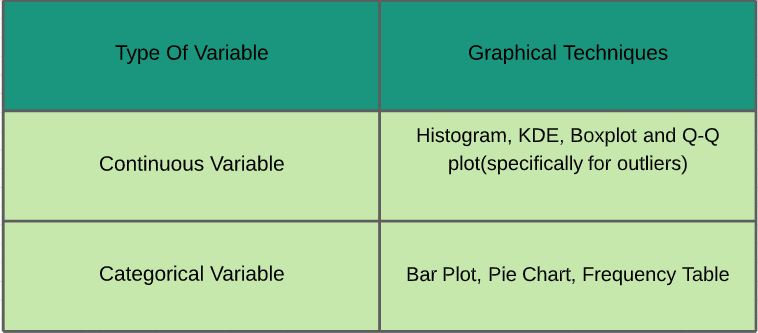
~ As estatísticas desempenham um papel importante na análise de dados. É um conjunto de regras e conceitos para a análise e interpretação de dados. Existem diferentes tipos de análises que devem ser realizadas, dependendo dos requisitos. ~ Vamos estudá-los - Análise univariada: Na análise univariada, estudamos as características individuais de cada característica / variável disponível no conjunto de dados. Existem dois tipos de funções: contínuo e categórico. Na imagem abaixo, Eu dei uma folha de dicas de várias técnicas gráficas que podem ser aplicadas para analisá-los.

Variável contínua:
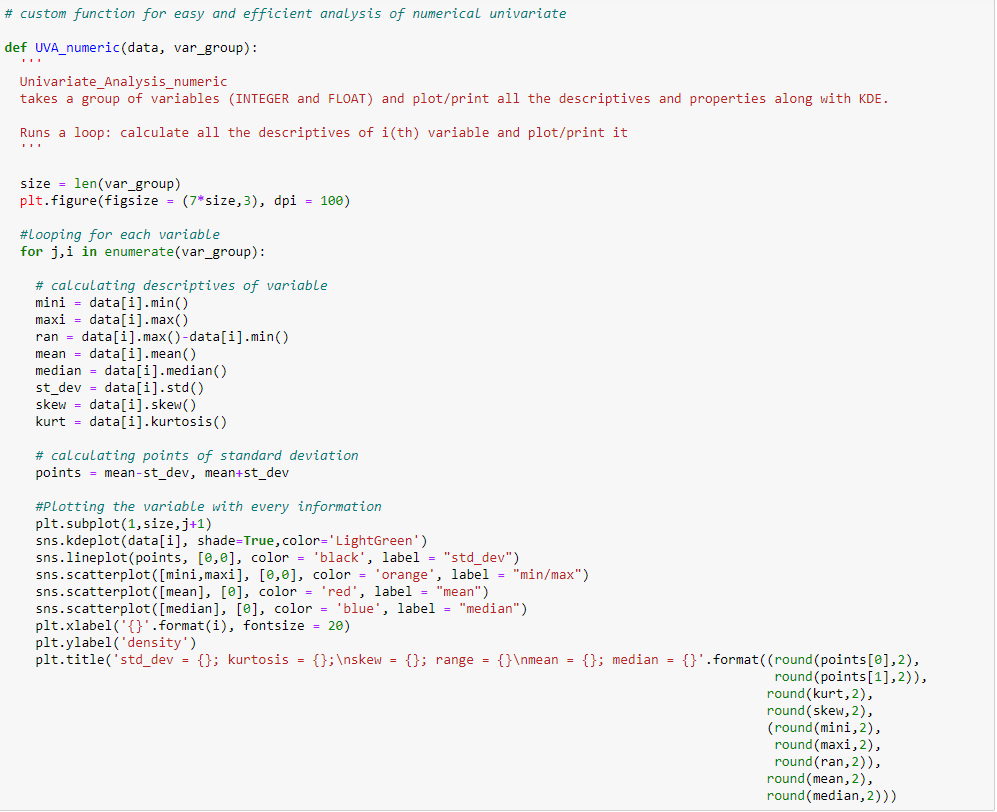
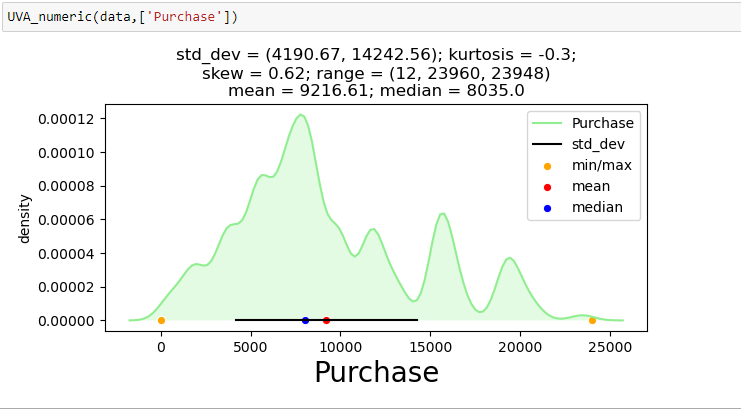
Para mostrar a análise univariada em uma das variáveis contínuas do conjunto de dados de venda da Black Friday: “Compra”, Eu criei uma função que recebe dados como entrada e desenha um gráfico do KDE que explica as características da função.


Variável categórica
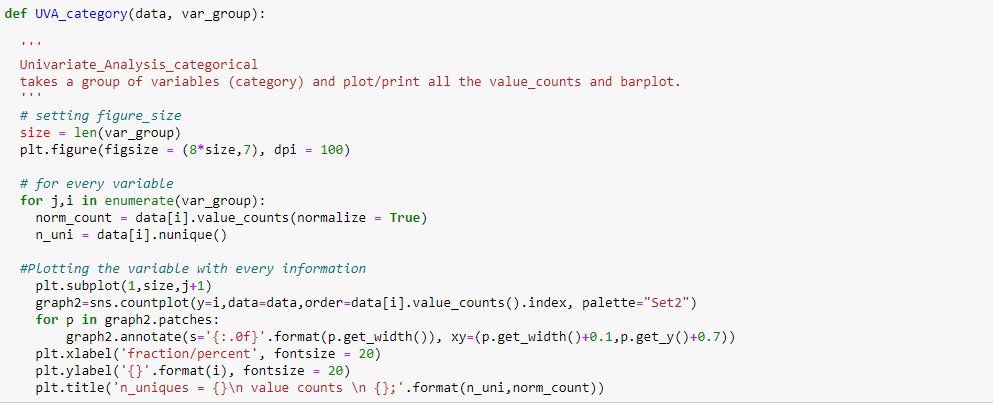
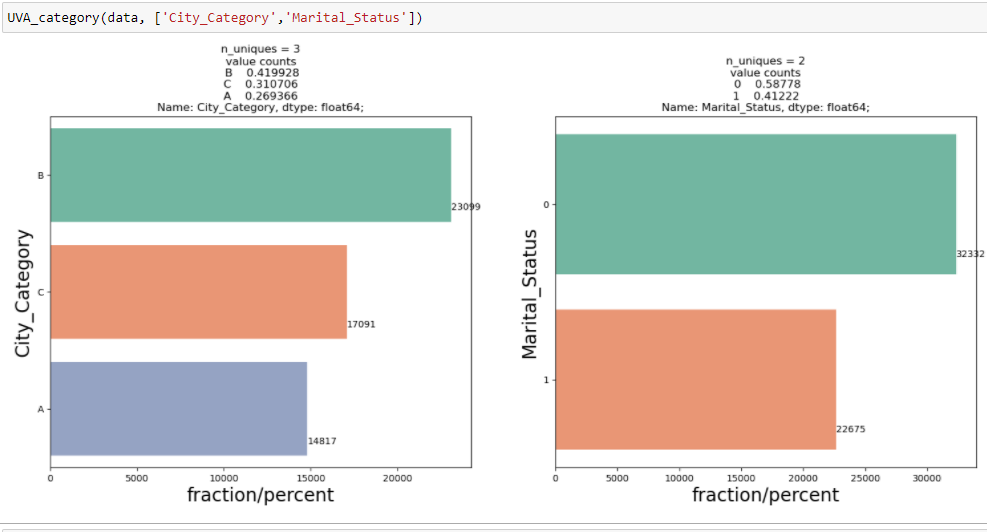
Para exibir uma análise univariada em variáveis categóricas no conjunto de dados de venda da Black Friday: `City_Category` y` Marital_Status`, Eu criei uma função que leva dados e características como entrada que retorna um gráfico de contagem explicando a frequência das categorias na característica.


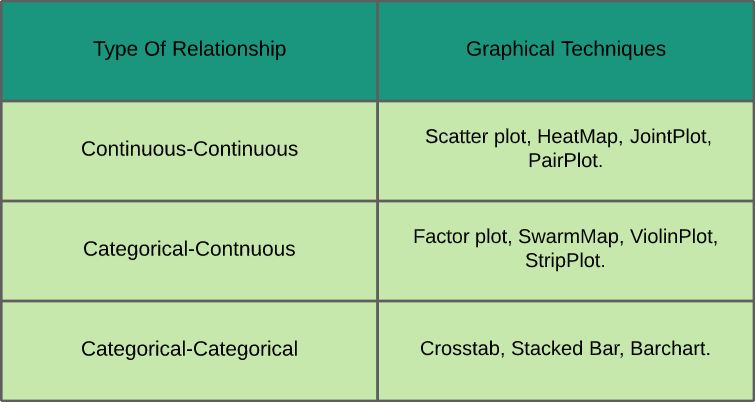
- Análise bivariada: Na análise bivariada, estudamos a relação entre quaisquer duas variáveis que podem ser categóricas-contínuas, categórico-categórico ou contínuo-contínuo (conforme mostrado na folha de referência mostrada abaixo, juntamente com as técnicas gráficas usadas para analisá-los).

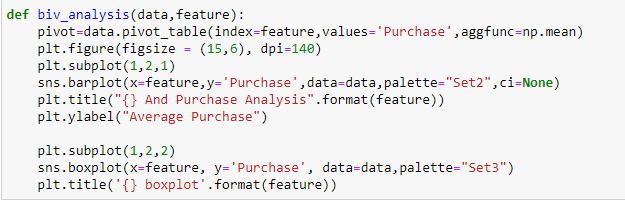
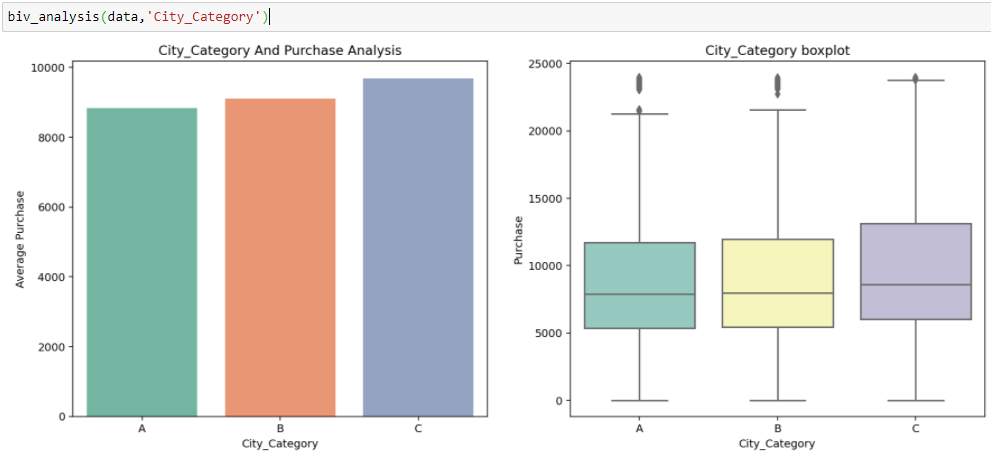
Vendas na Black Friday, temos variáveis independentes categóricas e variáveis-alvo contínuas, para que possamos fazer análises categóricas contínuas para entender a relação entre eles.

Inferência:
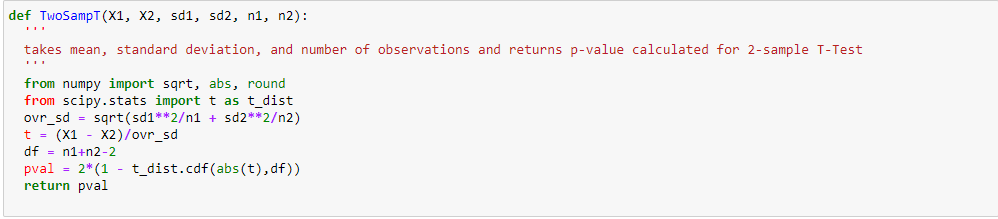
Das duas análises anteriores, Observamos na análise univariada que um número de clientes é máximo na categoria de cidade B. Mas a análise bivariada quando realizada entre `Cidade_Categoria` e` Compra` mostra uma história diferente de que a compra média é máxima da categoria C da cidade. Portanto, essas inferências podem nos dar uma melhor intuição sobre os dados, o que, por sua vez, ajuda a uma melhor preparação de dados e engenharia de recursos de recursos.É importante observar que simplesmente confiar na análise univariada e bivariada pode ser bastante enganoso., então, para verificar as inferências tiradas desses dois, você pode validar com Testando hipóteses. Podemos fazer um teste t, teste qui-quadrado, Anova que nos permite quantificar se duas amostras são significativamente semelhantes ou diferentes uma da outra. Aqui, criei uma função para analisar relacionamentos contínuos e categóricos que retornam o valor da estatística t.


 Na Análise Univariada, observamos que há uma diferença significativa entre o número de clientes casados e solteiros. Do teste t, obtemos o valor da estatística t 0.89, que é maior do que o nível de significância, quer dizer, 0.05, o que mostra que não há diferença significativa entre a compra média de solteiros e casados.
Na Análise Univariada, observamos que há uma diferença significativa entre o número de clientes casados e solteiros. Do teste t, obtemos o valor da estatística t 0.89, que é maior do que o nível de significância, quer dizer, 0.05, o que mostra que não há diferença significativa entre a compra média de solteiros e casados. - Tratamento de valor perdido : A principal razão para esta etapa é descobrir se há alguma razão específica pela qual esses valores estão ausentes e como os tratamos. Porque se não os tratamos, pode interferir no padrão executado nos dados, que por sua vez pode degradar o desempenho do modelo. Algumas das maneiras que os valores ausentes podem ser tratados são: – Encha-os com mídia, mediana, modo e pode usar impuidores.
- Remoção de outlier : É essencial que entendamos a presença de outliers, como alguns dos modelos preditivos são sensíveis a eles e devemos tratá-los de acordo.

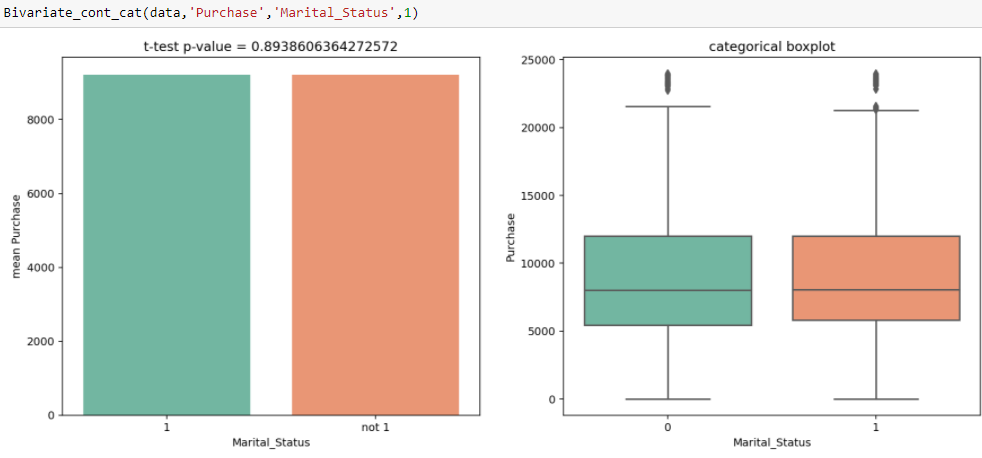 Na Análise Univariada, observamos que há uma diferença significativa entre o número de clientes casados e solteiros. Do teste t, obtemos o valor da estatística t 0.89, que é maior do que o nível de significância, quer dizer, 0.05, o que mostra que não há diferença significativa entre a compra média de solteiros e casados.
Na Análise Univariada, observamos que há uma diferença significativa entre o número de clientes casados e solteiros. Do teste t, obtemos o valor da estatística t 0.89, que é maior do que o nível de significância, quer dizer, 0.05, o que mostra que não há diferença significativa entre a compra média de solteiros e casados.Notas finais
Neste artigo, Discuti brevemente a importância da EDA no pipeline de ciência de dados e as etapas que estão envolvidas na análise adequada. Também mostrei como a análise incorreta ou incompleta pode ser bastante enganosa e afetar significativamente o desempenho dos modelos de aprendizado de máquina..
“Se você não dourar seus dados, você é apenas mais uma pessoa com uma opinião”;)





