Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
Clustering ou clustering é um algoritmo de aprendizagem de máquina não supervisionado que agrupa conjuntos de dados sem rótulo. Seu objetivo é formar clusters ou clusters usando os pontos de dados em um conjunto de dados de tal forma que haja uma alta semelhança entre os clusters e uma baixa semelhança entre os clusters.. Em termos simples, o cluster tem como objetivo formar subconjuntos ou grupos dentro de um conjunto de dados que consiste em pontos de dados que são realmente semelhantes uns aos outros e os grupos ou subconjuntos ou clusters formados podem diferir significativamente uns dos outros.
Por que grupo?
Suponha que tenhamos um conjunto de dados e não saibamos nada sobre isso.. Então, un algoritmo de agrupamentoo "agrupamento" É um conceito que se refere à organização de elementos ou indivíduos em grupos com características ou objetivos comuns. Este processo é usado em várias disciplinas, incluindo psicologia, Educação e biologia, para facilitar a análise e compreensão de comportamentos ou fenômenos. No campo educacional, por exemplo, O agrupamento pode melhorar a interação e o aprendizado entre os alunos, incentivando o trabalho.. puede descubrir grupos de objetos donde las distancias promedio entre los miembros / pontos de dados de cada grupo estão mais próximos do que os membros / pontos de dados em outros grupos.
Algumas das aplicações práticas de Clustering na vida real, como:
1) SegmentaçãoA segmentação é uma técnica de marketing chave que envolve a divisão de um mercado amplo em grupos menores e mais homogêneos. Essa prática permite que as empresas adaptem suas estratégias e mensagens às características específicas de cada segmento, melhorando assim a eficácia de suas campanhas. A segmentação pode ser baseada em critérios demográficos, psicográfico, geográfico ou comportamental, facilitando uma comunicação mais relevante e personalizada com o público-alvo.... de clientes: Encontrar un grupo de clientes con un comportamiento similar dada una gran base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... de clientes (um exemplo prático é dado usando segmentação de clientes bancários)
2) Classificação de tráfego de rede: Agrupando características da fonte de tráfego. Os tipos de tráfego podem ser facilmente classificados usando clusters.
3) Filtro de spam: Os dados são agrupados em diferentes seções (cabeçalho, remetente e conteúdo) e, em seguida, eles podem ajudar a classificar quais deles são spam.
4)Planejamento urbano: Agrupamento de casas de acordo com sua localização geográfica, valor e tipo de casa.
Diferentes tipos de algoritmos de agrupamento
1) Agrupamento de meias K – Usando este algoritmo, classificamos um determinado conjunto de dados através de um certo número de clusters padrão ou “k” Clusters.
2) Agrupamento hierárquico – Segue duas abordagens divisivas e de aglomeração.
A aglomeração considera cada observação como um único grupo e, em seguida, agrupa pontos de dados semelhantes até que eles se fundem em um único grupo e a Divisão funciona bem na frente dele..
3) Fuzzy C significa Clustering – A operação do algoritmo FCM é quase semelhante ao algoritmo de agrupamento k-means, a principal diferença é que no fcm um ponto de dados pode ser colocado em mais de um grupo.
4) Agrupamento espacial baseado em densidade – Útil en las áreas de aplicación donde requerimos estructuras de cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... no lineales, com base puramente na densidade.
Agora, aqui neste artigo, vamos nos concentrar profundamente no algoritmo de agrupamento k-meios, explicações teóricas do funcionamento dos k-means, vantagens e desvantagens, e um problema de agrupamento prático resolvido que vai melhorar a compreensão teórica e dar-lhe uma visão adequada. como o clustering k-media funciona.
Este isto é k-metade Clustering?
La agrupación de K-Means es un algoritmo de Aprendizado não supervisionadoO aprendizado não supervisionado é uma técnica de aprendizado de máquina que permite que os modelos identifiquem padrões e estruturas em dados sem rótulos predefinidos. Por meio de algoritmos como k-means e análise de componentes principais, Essa abordagem é usada em uma variedade de aplicações, como segmentação de clientes, detecção de anomalias e compactação de dados. Sua capacidade de revelar informações ocultas o torna uma ferramenta valiosa no..., que é usado para agrupar o conjunto de dados sem rótulo em diferentes grupos / subconjuntos.
Agora você deve estar se perguntando o que 'k significa’ e 'significa’ no k-significa Clustering significa ??
Deixando de lado todas as suas suposições aqui, 'k’ define o número de grupos predefinidos a serem criados no processo de agrupamento, vamos dizer se k = 2, haverá dois grupos, e para k = 3, haverá três grupos e assim por diante. Como é um algoritmo baseado em centroid, 'meias’ no agrupamento de k-means está relacionado com o centroid dos pontos de dados onde cada grupo está associado a um centroide. O conceito de um algoritmo baseado em centroid será explicado na explicação de trabalho dos k-means.
Principalmente, o algoritmo de clustering k-means executa duas tarefas:
- Determina o valor mais ideal para pontos centrais ou centroides K usando um processo repetitivo.
- Atribua cada ponto de dados ao k-center mais próximo. O cluster é criado com pontos de dados próximos ao centro k particular.
Como funciona o agrupamento k-significa??
Suponha que temos duas variáveis X1 e X2, Diagrama de dispersãoO gráfico de dispersão é uma ferramenta gráfica usada em estatística para visualizar a relação entre duas variáveis. Consiste em um conjunto de pontos em um plano cartesiano, onde cada ponto representa um par de valores correspondentes às variáveis analisadas. Este tipo de gráfico permite identificar padrões, Tendências e possíveis correlações, facilitando a interpretação dos dados e a tomada de decisão com base nas informações visuais apresentadas.... a seguir:
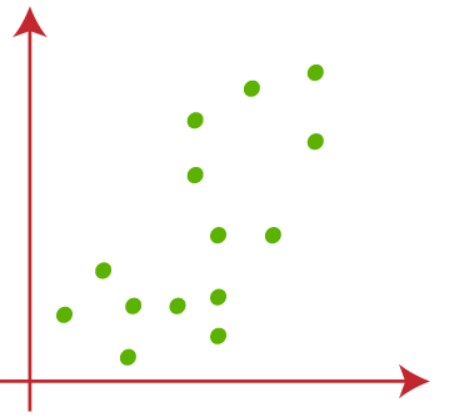
(1) Suponha o valor de k, que é o número de grupos predefinidos, isto é 2 (k = 2), então aqui vamos agrupar nossos dados em 2 grupos.
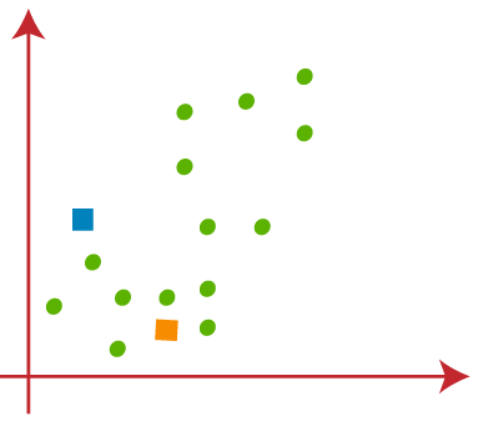
É necessário escolher k pontos aleatórios para formar os grupos. Não pode haver restrições na seleção de k pontos aleatórios de dentro dos dados ou do exterior. Então, aqui estamos considerando 2 pontos como pontos K (que não fazem parte do nosso conjunto de dados) que se muestran en la siguiente figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas....:
(2) o próximo passo é mapear cada ponto de dados no conjunto de dados no gráfico de dispersão até o ponto k mais próximo, esto se hará calculando la distancia euclidiana entre cada punto con un punto k y dibujando una medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos.... entre ambos centroides, mostrado na figura abaixo-
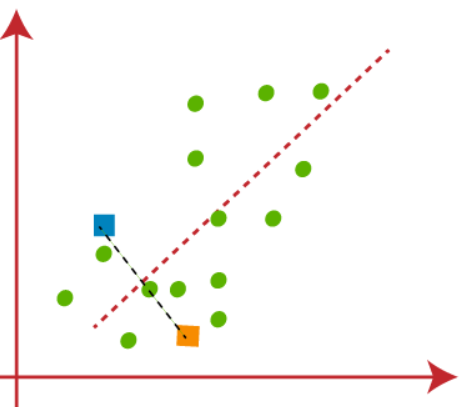
Podemos observar claramente que o ponto à esquerda da linha vermelha é perto de K1 ou o centroide azul e os pontos à direita da linha vermelha estão perto de K2 ou do centroide laranja.
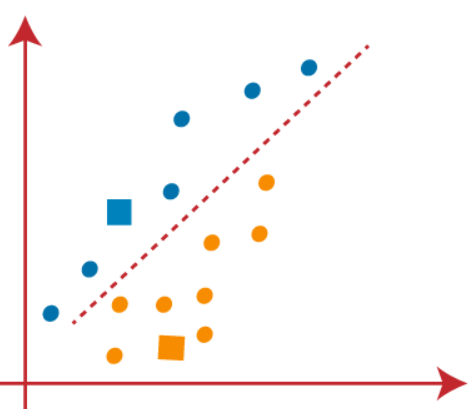
(3) Como precisamos encontrar o ponto mais próximo, vamos repetir o processo escolhendo um novo centroid. Para escolher os novos centroides, vamos calcular o centro de gravidade desses centroids e encontrar novos centroids como mostrado abaixo:
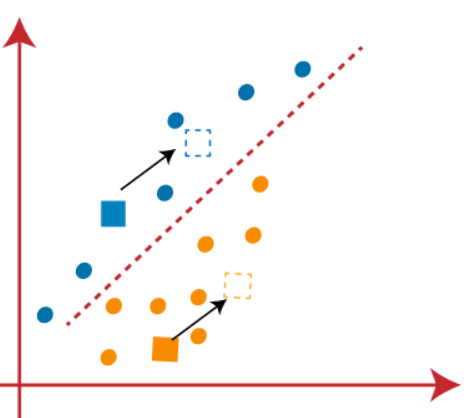
(4) Agora, precisamos reatribuir cada ponto de dados para um novo centroid. Para isso, temos que repetir o mesmo processo de encontrar uma linha média. A mediana será tão abaixo:
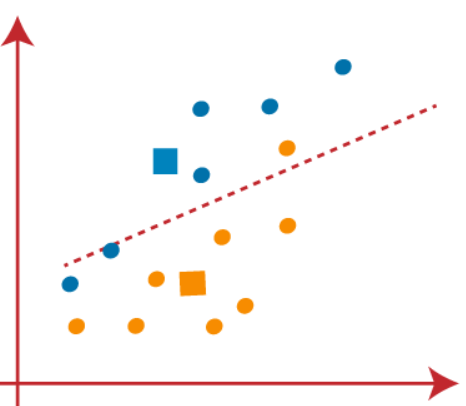
Na foto acima, podemos ver, um ponto laranja está no lado esquerdo da linha e dois pontos azuis estão bem na linha. Então, esses três pontos serão atribuídos a novos centroids

Continuaremos a encontrar novos centrosids até que não haja pontos diferentes em ambos os lados da linha..
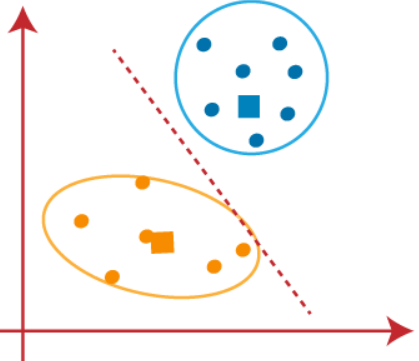
Agora podemos eliminar os centrosids presumido, e os dois últimos grupos serão como mostrado na imagem abaixo
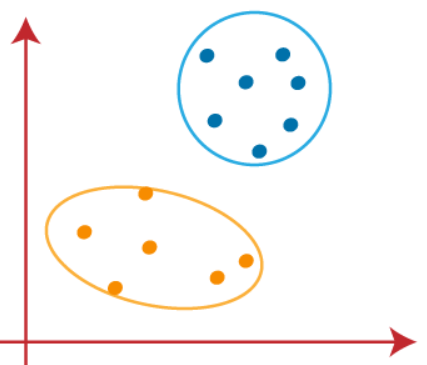
Até agora vimos como o algoritmo k-media funciona e os diferentes passos envolvidos para chegar ao destino final dos clusters diferenciados.
Agora todos devem estar se perguntando como escolher o valor do número k de clusters.
El rendimiento del algoritmo de agrupación de K-means depende en gran mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... de las agrupaciones que forma. Escolher o número ideal de clusters é uma tarefa difícil. Existem várias maneiras de encontrar o número ideal de clusters, mas aqui estamos discutindo dois métodos para encontrar o número de clusters ou o valor de K que é o Método do cotovelo e pontuação de silhueta.
Método de cotovelo para encontrar 'k’ número de grupos:[1]
O método Elbow é o mais popular para encontrar um número ideal de clusters, este método usa wcss (Soma de praças dentro de conglomerados) representando as variações totais dentro de um cluster.
WCSS = ∑Pi em Cluster1 distância (Peu C1)2 + ∑Pi em Cluster2distância (Peu C2)2+ ∑Pi em CLuster3 distância (Peu C3)2
Na fórmula acima ∑Pi em Cluster1 distância (Peu C1)2 é a soma do quadrado das distâncias entre cada ponto de dados e seu centroide dentro de um grupo1 semelhante para os outros dois termos na fórmula acima.
Etapas envolvidas no método do cotovelo:
- K- significa que o agrupamento é feito para diferentes valores de k (a partir de 1 uma 10).
- WCSS é calculado para cada grupo.
- Uma curva é desenhada entre os valores WCSS e o número de clusters k.
- O ponto de curvatura afiada ou um ponto de trama parece um braço, então esse ponto é considerado como o melhor valor de K.
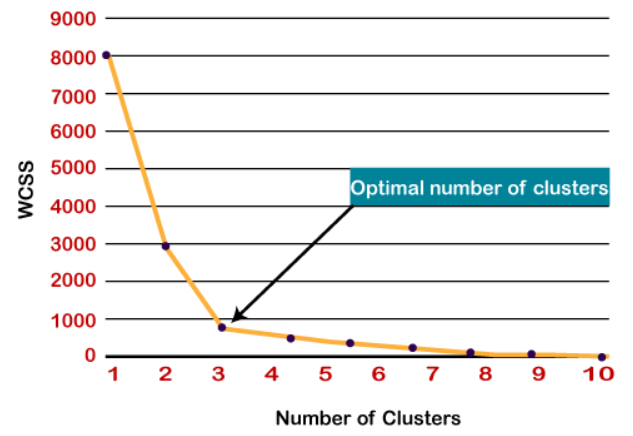
Então aqui, como podemos ver, uma curva afiada está em k = 3, então o número ideal de grupos é 3.
Avaliações de usuários para silhueta Método para encontrar 'k’ número de clusters
O valor da silhueta é uma medida de quão semelhante um objeto é ao seu próprio grupo. (coesão) em comparação com outros grupos (separação). A silhueta varia de -1 uma +1, onde um alto valor indica que o objeto corresponde bem ao seu próprio grupo e não aos grupos vizinhos. Se a maioria dos objetos tem um alto valor, em seguida, a configuração de agrupamento é apropriada. Se muitos pontos têm um valor baixo ou negativo, então a configuração de clustering pode ter muitos ou poucos clusters.
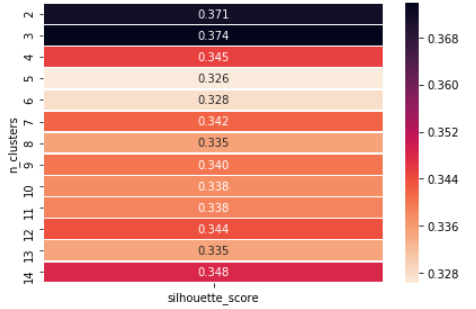
Exemplo mostrando como podemos escolher o valor de 'k', uma vez que podemos ver que em n = 3 temos a pontuação máxima de silhueta, portanto, escolhemos o valor de k = 3.
Vantagens do uso de clustering k-means
- Fácil de implementar.
- Com um grande número de variáveis, K-Means pode ser computacionalmente mais rápido do que o agrupamento hierárquico (se K é pequeno).
- k-significa pode produzir agrupamentos maiores do que agrupamentos hierárquicos.
Desvantagens do uso de agrupamento k-meio
É difícil prever o número de agrupamentos (Valor K).
As sementes iniciais têm um forte impacto nos resultados finais.
Implementação prática do algoritmo de clustering k-means usando Python (segmentação de clientes bancários)
Aqui estamos importando as bibliotecas necessárias para nossa análise.
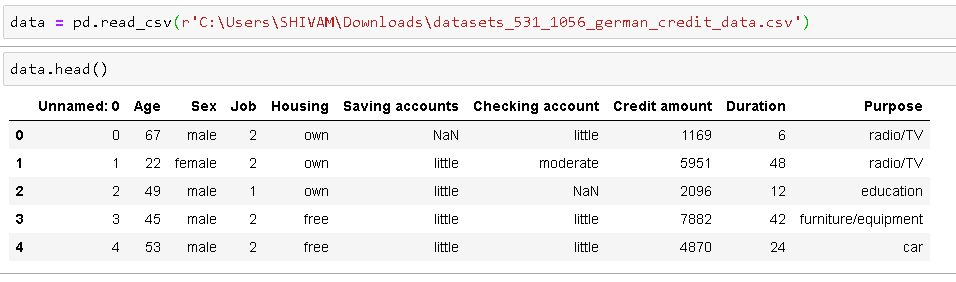
Leia os dados e obtenha o 5 melhores observações para dar uma olhada no conjunto de dados
Código para EDA não incluído (Análise exploratória de dados), O EDA foi realizado com esses dados e uma análise outlier foi realizada para limpar os dados e torná-lo adequado para nossa análise.
Como sabemos, Os k-means são realizados apenas em dados numéricos, então escolhemos as colunas numéricas para nossa análise.

Agora, para realizar o agrupamento k-means como discutido anteriormente neste artigo, precisamos encontrar o valor do número 'k’ de agrupamentos e podemos fazê-lo usando o seguinte código, aqui usamos vários valores de k para agrupamento e, em seguida, selecionar usando o Método do cotovelo.

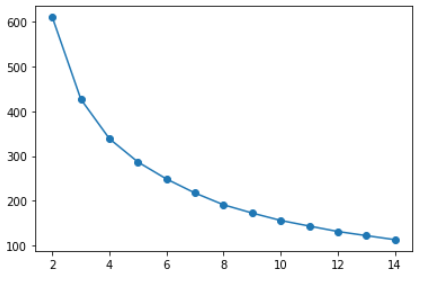
À medida que o número de clusters aumenta, a variância (soma de quadrados dentro do conglomerado) Diminui. O cotovelo em 3 o 4 os grupos representam o equilíbrio mais parcimonioso entre minimizar o número de grupos e minimizar a variância dentro de cada grupo., para que possamos escolher um valor de k para ser 3 o 4
Agora ele mostra como podemos usar o método de valor da silhueta para encontrar o valor de 'k'.

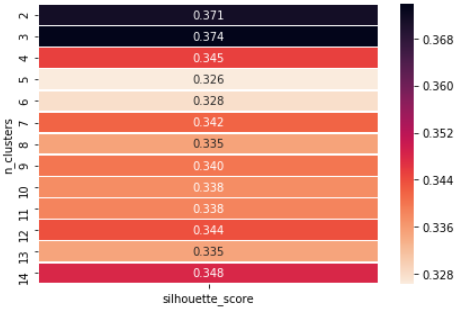
Se observarmos, temos o número ideal de clusters em n = 3, então, finalmente, podemos escolher o valor de k = 3.
Agora, ajustar o algoritmo de k significa usar o valor de k = 3 y trazar el mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas.... para los clústeres.
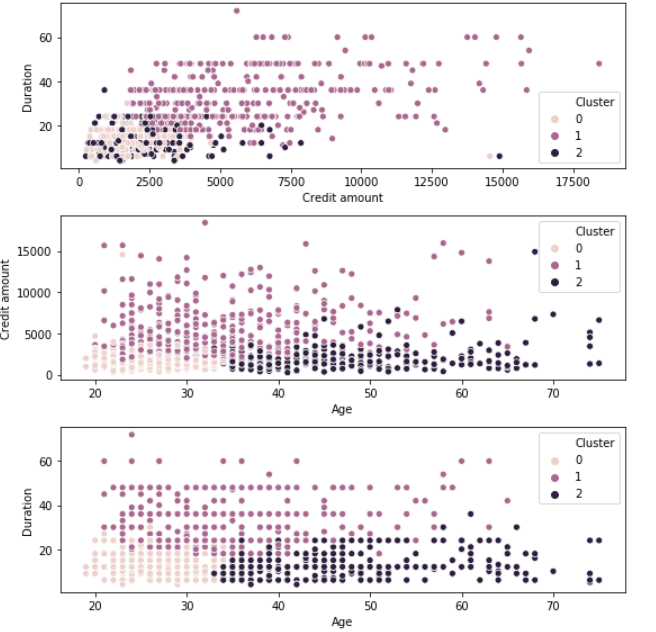

Análise final
Cluster 0: clientes jovens que recebem empréstimos de baixo crédito por um curto período de tempo
Grupo 1: Clientes de meia-idade que recebem empréstimos de alto crédito por um período prolongado
Grupo 2: Clientes idosos que recebem empréstimos de crédito médio por um curto período
conclusão
Nós discutimos o que é clustering, seus tipos e sua aplicação em diferentes indústrias. Discutimos o que é o agrupamento k-means, a operação do algoritmo de agrupamento k-médio, dois métodos para selecionar o número 'k’ de agrupamentos, e suas vantagens e desvantagens. Mais tarde, passamos pela implementação prática do algoritmo de clustering k-media usando o problema de segmentação de clientes de bancos em Python.
Referências:
(1) img (1) para img (8) e [1] , referência tomada de “Algoritmo de clustering de mídia K”
https://www.javatpoint.com/k-means-clustering-algorithm-in-machine-learning





