
R Estás pronto? Vamos aprender a agrupar em R.
http: // www.pags: //www.rstudio.com/products/rstudio/download/
Visualização de dados usando R
Nos tempos atuais, as imagens falam mais alto que os números ou a análise de palavras. sim, gráficos e diagramas são mais atraentes e fáceis de identificar para o olho humano. É aqui que entra a importância da análise de dados R.. Os clientes entendem melhor a representação gráfica de seu crescimento / avaliação / Distribuição de produtos. Portanto, a ciência de dados está crescendo hoje em dia e R é uma daquelas linguagens que oferece flexibilidade em plotagem e gráficos, pois tem funções e pacotes específicos para tais tarefas. RStudio é um software onde dados e visualização acontecem lado a lado, o que o torna muito favorável para um analista de dados. Diagramas de dispersão, plotagens de caixaDiagramas de caixa, Também conhecido como diagramas de caixa e bigode, são ferramentas estatísticas que representam a distribuição de um conjunto de dados. Esses diagramas mostram a mediana, Quartis e outliers, permitindo que a variabilidade e a simetria dos dados sejam visualizadas. Eles são úteis na comparação entre diferentes grupos e na análise exploratória, facilitando a identificação de tendências e padrões nos dados...., gráficos de barras, gráficos de linha, gráficos de linha, mapas de calor, etc. são possíveis em R com apenas uma função simples, por exemplo: o histograma pode ser traçado usando a função hist (nome dos dados) com parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... Como xlab (x tag), cor, deve, etc.
Aproveitando esta conveniência, Vamos passar para um método de Aprendizado não supervisionadoO aprendizado não supervisionado é uma técnica de aprendizado de máquina que permite que os modelos identifiquem padrões e estruturas em dados sem rótulos predefinidos. Por meio de algoritmos como k-means e análise de componentes principais, Essa abordagem é usada em uma variedade de aplicações, como segmentação de clientes, detecção de anomalias e compactação de dados. Sua capacidade de revelar informações ocultas o torna uma ferramenta valiosa no...: agrupamento.
Aprendizagem supervisionada e não supervisionada
Existem dois tipos de aprendizagem na análise de dados: aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em... e não supervisionado.
Aprendizagem supervisionada – Os dados marcados são uma entrada para a máquina de aprendizagem. Regressão, a classificação, Árvores de decisão, etc. são métodos de aprendizagem supervisionados.
Exemplo de aprendizagem supervisionada:
A regressão linear é onde há apenas um variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... dependente. Equação: y = mx + c, y depende de x.
Por exemplo: a idade e o perímetro de uma árvore são os 2 rótulos como conjunto de dados de entrada, a máquina precisa prever a idade de uma árvore com uma circunferência como entrada após conhecer o conjunto de dados que foi alimentado. A idade depende da circunferência.
Por tanto, a aprendizagem é monitorada com base em tags.
Aprendizagem não supervisionada – Os dados não rotulados são enviados para a máquina para encontrar um padrão por conta própria. Clustering é um método de aprendizagem não supervisionado que possui modelos: KMeans, agrupamento hierárquico, DBSCAN, etc.
A representação visual dos clusters mostra os dados em um formato de fácil compreensão, pois agrupa elementos de um grande conjunto de dados de acordo com suas semelhanças. Isso torna a análise mais fácil. Porém, a aprendizagem não supervisionada nem sempre é precisa e é um processo complexo para a máquina, uma vez que os dados não são rotulados.
Vamos agora continuar com um exemplo de agrupamentoo "agrupamento" É um conceito que se refere à organização de elementos ou indivíduos em grupos com características ou objetivos comuns. Este processo é usado em várias disciplinas, incluindo psicologia, Educação e biologia, para facilitar a análise e compreensão de comportamentos ou fenômenos. No campo educacional, por exemplo, O agrupamento pode melhorar a interação e o aprendizado entre os alunos, incentivando o trabalho.. usando o conjunto de dados de flores da íris.
Agrupamento
Clusters eles são um grupo dos mesmos elementos ou elementos, como um cacho de estrelas ou um cacho de uvas ou um cacho de redes e assim por diante …
Usando clustering no mundo real:
É usado em sites de comércio eletrônico para formar grupos de clientes com base em seus perfis, como idade, sexo, gastando, regularidade, etc. É útil em marketing e vendas, pois ajuda a agrupar o público-alvo do produto. A filtragem de spam em e-mails e muitos outros são aplicativos de cluster do mundo real.
Clustering em R refere-se à assimilação do mesmo tipo de dados em grupos ou clusters para distinguir um grupo dos outros. (coleta do mesmo tipo de dados). Isso pode ser representado em formato gráfico por meio de R. Usamos o modelo KMeans neste processo.
O que é o algoritmo K Means?
K Means é um algoritmo de agrupamento que atribui repetidamente um grupo entre os k grupos presentes a um ponto de dados de acordo com as características do ponto. É um método de agrupamento baseado em centróides.
O número de clusters é decidido, centros de cluster são selecionados aleatoriamente mais distantes uns dos outros, a distância entre cada ponto de dados e o centro é calculada usando a distância euclidiana, o ponto de dados é atribuído ao cluster cujo centro está mais próximo desse ponto. Este processo é repetido até que o centro dos grupos não mude e os pontos de dados permaneçam no mesmo grupo..
Isso tudo é teoria, mas na prática, R tem um pacote de empacotamento que calcula as etapas acima.
Paso 1
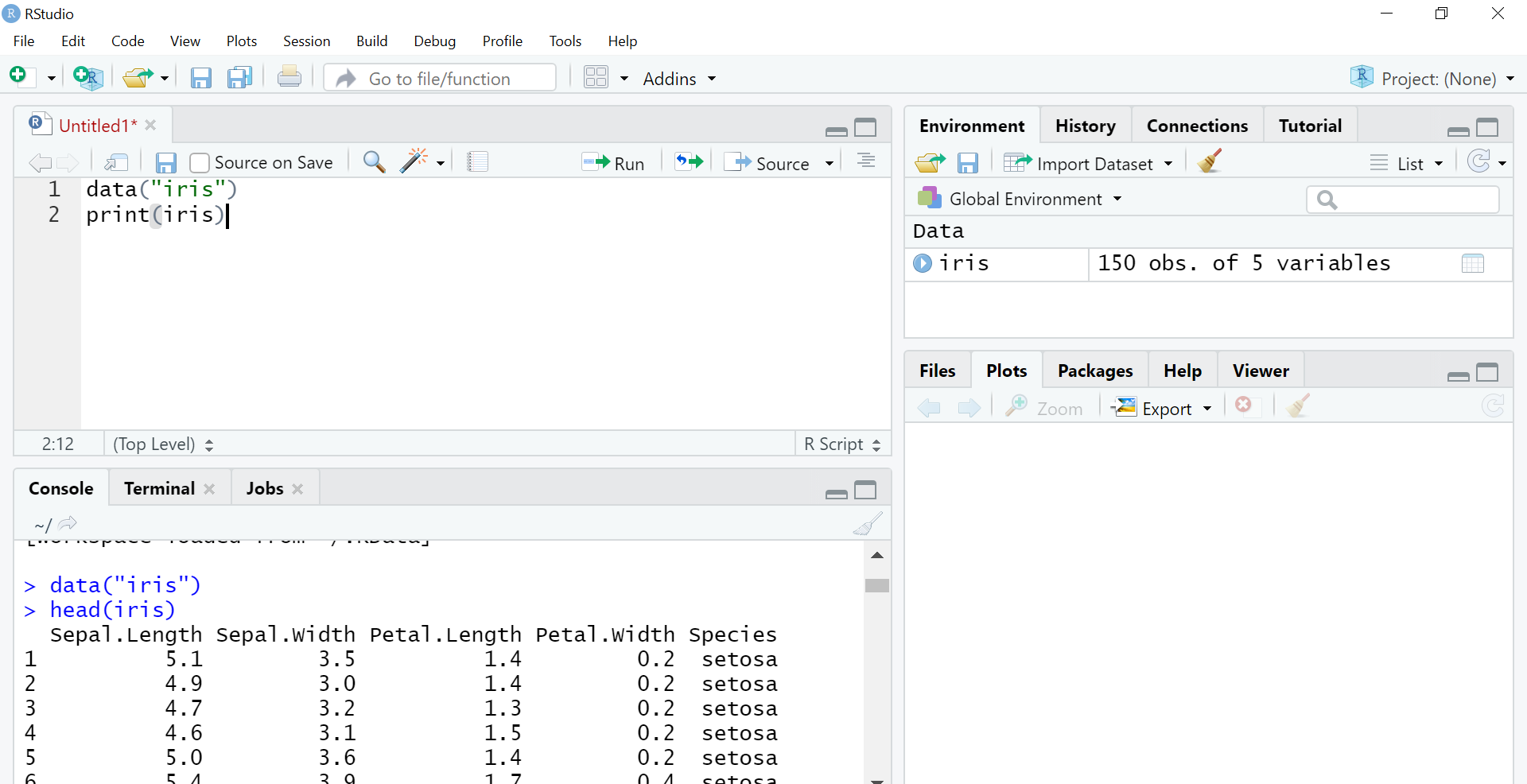
Vou trabalhar no conjunto de dados Iris, que é um conjunto de dados embutido em R usando o pacote Cluster. Tenho 5 colunas, a saber: comprimento sépala, largura sépala, comprimento da pétala, largura da pétala e espécie. Iris é uma flor e aqui neste conjunto de dados ela é mencionada 3 de sua espécie Setosa, Versicolor, Verginica. Vamos agrupar as flores de acordo com suas espécies. O código para carregar o conjunto de dados:
dados("íris")
cabeça(íris) #vai mostrar o topo 6 linhas apenas

Paso 2
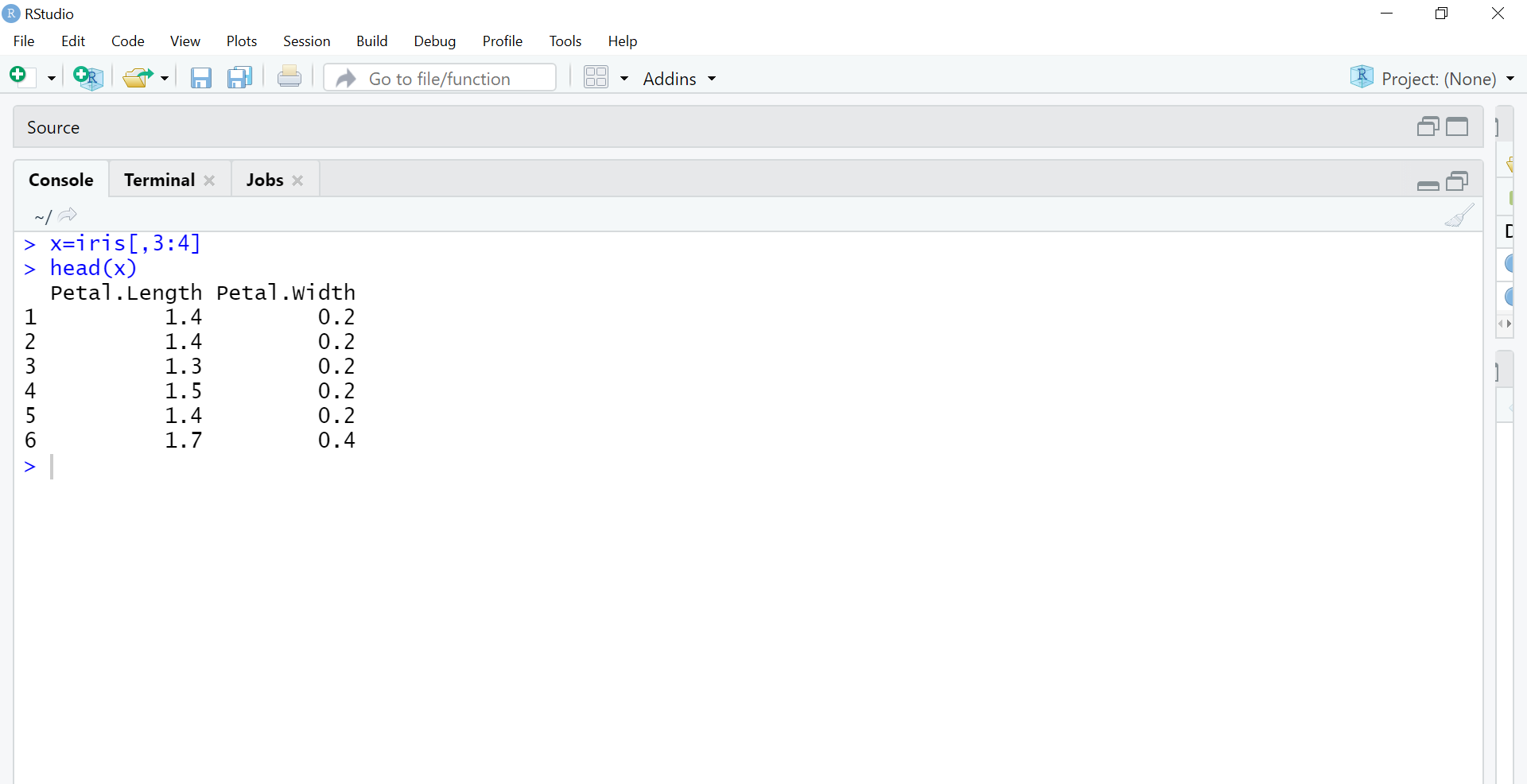
A próxima etapa é separar as colunas 3 e 4 em um objeto x separado, uma vez que estamos usando o método de aprendizagem não supervisionado. Estamos removendo rótulos para que a máquina use a enorme entrada de colunas de comprimento e largura de pétalas para agrupamento autônomo.
x = íris[,3:4] #usando apenas colunas de comprimento e largura de pétalas cabeça(x)
Paso 3
O próximo passo é usar o algoritmo K Means. K Means é o método que usamos que tem parâmetros (dados, não. De clusters o grupos). Aqui nossos dados são o objeto x e teremos k = 3 grupos, como não 3 espécies no conjunto de dados.
Então o ‘pacote de cluster se chama. O agrupamento em R é feito usando este pacote embutido que fará toda a matemática. A função Clusplot cria um gráfico 2D dos clusters.
model = kmeans(x,3) biblioteca(cacho) clusplot(x,modelo $ cluster)
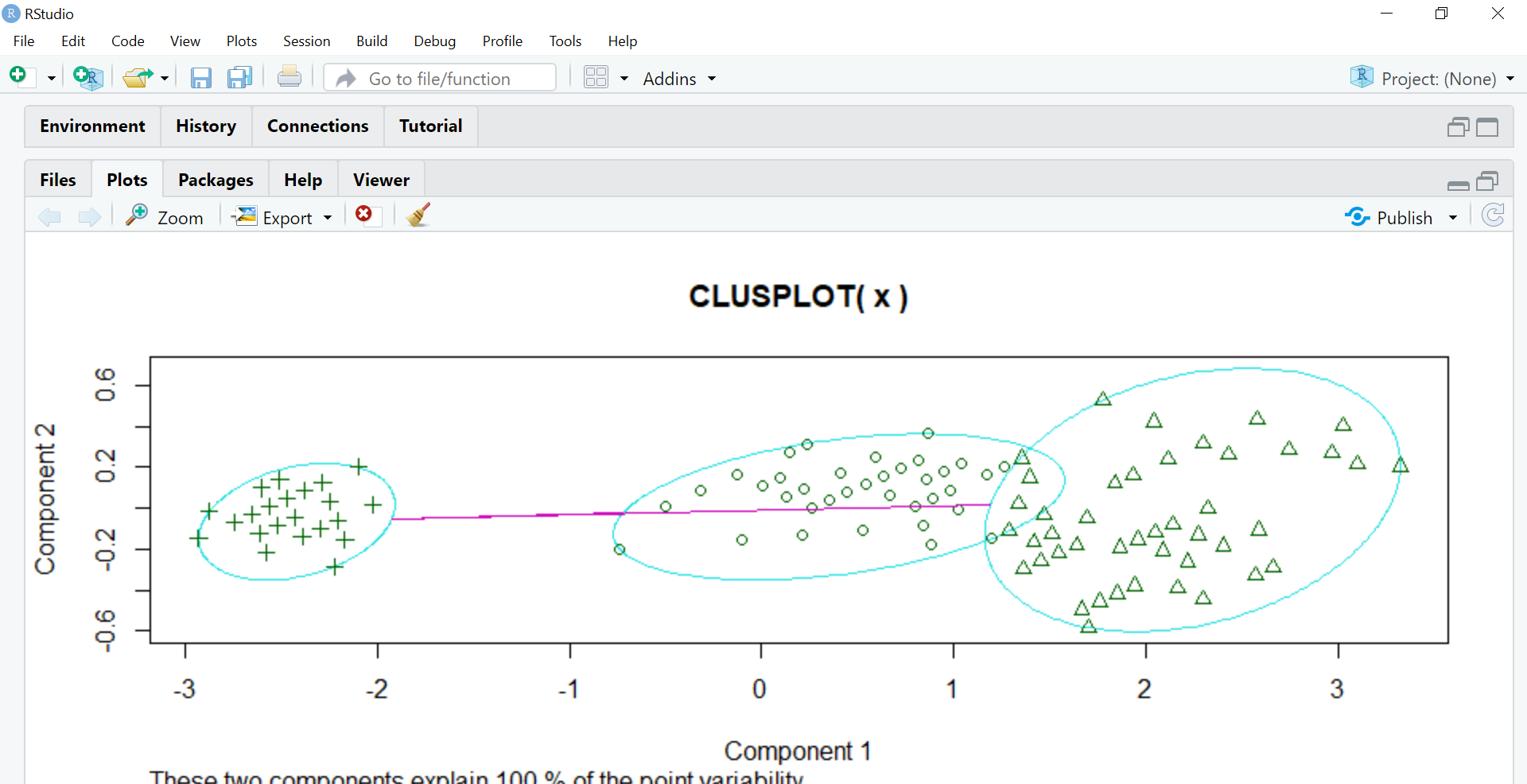
O componente 1 e o componente 2 visto no gráfico são os dois componentes do PCA (análise do componente principal), que é basicamente um método de extração de recursos que usa os componentes importantes e remove o resto. Reduz a dimensionalidade dos dados para facilitar a aplicação de KMeans. Tudo isso é feito pelo cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... um R.
Esses dois componentes explicam a variabilidade do 100% na saída, o que significa que o objeto de dados x fornecido ao PCA foi preciso o suficiente para formar grupos claros usando KMeans e há uma sobreposição mínima (insignificante) entre eles.
Paso 4
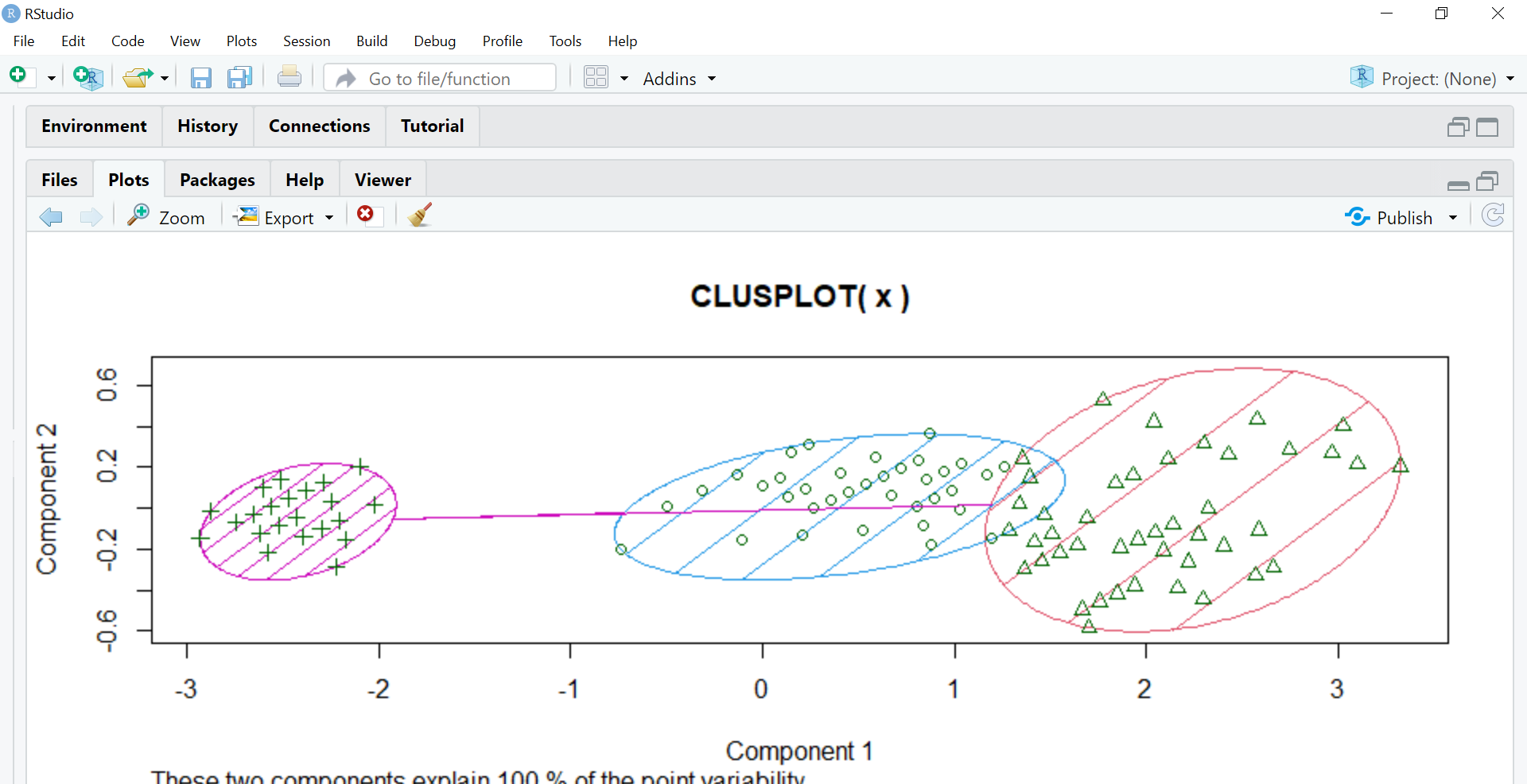
O próximo passo é atribuir cores diferentes aos grupos e sombrear, portanto, usamos os parâmetros de cor e sombra configurando-os para T, o que significa verdade.
clusplot(x,modelo $ cluster,color = T,sombra = T)
conclusão
Tudo isso resume o básico do agrupamento em R. Aqui eu uso um conjunto de dados integrado, mas conjuntos de dados importados também podem ser usados para clustering. Por exemplo: agrupar usuários de um site com base em itens favoritos, etc. É muito útil para fazer comparações de negócios.
Importar conjuntos de dados para R:
conjunto de dados <- read.csv("path.csv")
Visualizar(conjunto de dados)
anexar(conjunto de dados)
Obrigado por dedicar seu tempo e ler este artigo.,Sinta-se à vontade para comentar o que pode ser melhorado, já que aprender é um processo diário.depois detodo o mundo..
LigarcommimsobreLinkedIn:https://www.linkedin.com/in/akansha-bose-149b14164/
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





