Este artigo foi publicado como parte do Data Science Blogathon.
Visão geral
- Saiba mais sobre o algoritmo de árvore de decisão em aprendizado de máquina para problemas de classificação.
- aqui nós cobrimos entropia, ganho de informação e impureza de Gini
Algoritmo de árvore de decisão
algoritmos. Isso pode ser usado tanto para um problema de classificação quanto para um problema de regressão.
O objetivo deste algoritmo é criar um modelo que preveja o valor de uma variável de destino, para o qual a árvore de decisão usa a representação da árvore para resolver o problema em que o nó folha corresponde a um rótulo de classe e os atributos são representados no nó interno. da árvore.
Vamos pegar um conjunto de dados de amostra para ir mais longe ....
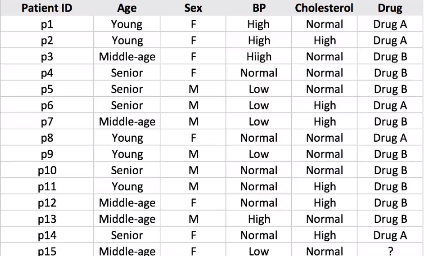
Suponha que temos uma amostra de 14 conjuntos de dados do paciente e temos que prever qual medicamento sugerir ao paciente A ou B.
Digamos que escolhemos o colesterol como o primeiro atributo para dividir os dados
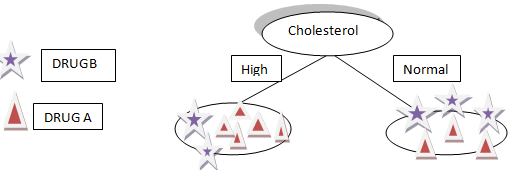
Ele vai dividir nossos dados em dois ramos Alto e Normal de acordo com o colesterol, como você pode ver na figura acima.
Suponha que nosso novo paciente tenha colesterol alto da divisão acima de nossos dados que não podemos dizer qualquer O medicamento B ou A será apropriado para o paciente.
O que mais, se o colesterol do paciente é normal, ainda não temos uma ideia ou informação para determinar se o medicamento A ou B é adequado para o paciente.
Vamos dar outra era de atributo, como podemos ver, idade tem três categorias: Homem jovem, meia idade e mais velhos, vamos tentar dividir.
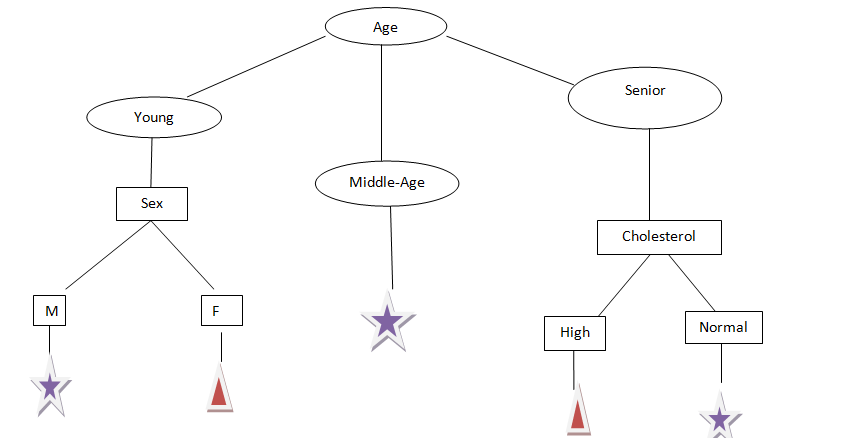
Da figura anterior, agora podemos dizer que podemos prever facilmente qual medicamento administrar a um paciente com base em seus relatórios.
Suposições que fazemos ao usar a árvore de decisão:
– No princípio, consideramos todo o conjunto de treinamento como a raiz.
-Valores característicos são preferidos para serem categóricos, se os valores continuarem, são convertidos em discretos antes de construir o modelo.
-Com base em valores de atributo, os registros são distribuídos recursivamente.
-Usamos um método estatístico para ordenar atributos como nó raiz ou nó interno.
Matemática por trás do algoritmo da árvore de decisão: Antes de passar para o ganho de informação, primeiro temos que entender a entropia.
Entropia: Entropia são as medidas de impureza, transtorno, o incerteza em muitos exemplos.
Objetivo da entropia:
A entropia controla como uma árvore de decisão decide separar os dados. Afeta como um Árvore de decisão desenhe seus limites.
"Os valores de entropia variam de 0 a 1 ”, menos o valor de entropia é mais confiável.

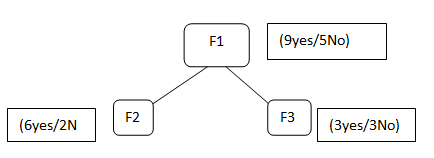
Suponha que temos as características F1, F2, F3, selecionamos a característica F1 como nosso nó raiz
F1 contém 9 etiqueta sim e 5 sem rótulo, depois de dividir o F1, obtemos F2, que tem 6 sim / 2 Não e F3 você tem 3 sim / 3 não.
Agora, se tentarmos calcular a entropia de ambos F2 usando a fórmula de entropia …
Colocando os valores na fórmula:
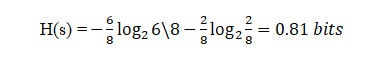
Aqui, 6 é o número de sim considerados positivos, uma vez que estamos calculando a probabilidade dividida por 8 é o total de linhas presentes em F2.
Do mesmo modo, se realizarmos Entropia para F3, obteremos 1 bit que é o caso de um atributo, uma vez que nele há 50%, sim e 50% não.
Esta divisão continuará a menos e até que obtenhamos um subconjunto puro.
O que é um Puresubset?
O subconjunto puro é uma situação em que obteremos todos sim ou todos não, neste caso.
Fizemos isso com relação a um nó, E se depois de dividir F2 pudéssemos também exigir algum outro atributo para chegar ao nó folha e também tivéssemos que pegar a entropia desses valores e adicioná-los para enviar todos os valores de entropia para aquele? temos o conceito de ganho de informação.
Ganho de informação: O ganho de informação é usado para decidir em qual função dividir em cada etapa da construção da árvore. Simplicidade é o melhor, é por isso que queremos que nossa árvore seja pequena. Para faze-lo, em cada etapa, devemos escolher a divisão que resulta nos nós filhos mais puros. Uma medida de pureza comumente usada é chamada de informação.
Para cada nó na árvore, valor da informação mede quanta informação uma característica nos dá sobre a classe. A divisão com o maior ganho de informação será considerada como a primeira divisão e o processo continuará até que todos os nós secundários sejam puros ou até que o ganho de informação seja 0.
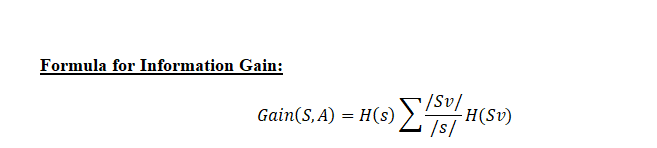
O algoritmo calcula o ganho de informação para cada divisão e a divisão que dá o maior valor de ganho de informação é selecionada.
Podemos dizer que em Ganho de Informação vamos calcular a média de toda entropia em função da divisão específica.
Sv = Amostra total após a divisão como em F2 há 6 sim
S = Amostra total como em F1 = 9 + 5 = 14
Agora calculando o ganho de informação:
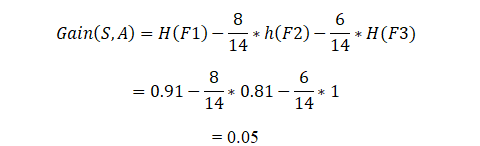
Desta maneira, o algoritmo fará isso por n número de divisões, e o ganho de informação para a divisão que for maior vai demorar para construir a árvore de decisão.
Quanto maior o valor do ganho de informação da divisão, quanto maior a probabilidade de que seja selecionado para a divisão particular.
Impureza de Gini:
A impureza de Gini é uma medida usada para construir árvores de decisão para determinar como as características de um conjunto de dados devem dividir os nós para formar a árvore. Mais precisamente, a impureza Gini de um conjunto de dados é um número entre 0-0,5, indicando a probabilidade de que dados novos e aleatórios sejam classificados incorretamente se eles forem atribuídos a um rótulo de classe aleatório de acordo com a distribuição de classes no conjunto de dados.
Entropia vs. Impureza Gini
O valor máximo de entropia é 1, enquanto o valor máximo de impureza Gini é 0,5.
Como o Gini Impurit
Neste artigo, cobrimos muitos detalhes sobre a árvore de decisão, como funciona e a matemática por trás disso, medidas de seleção de atributos, como Entropia, Ganho de informação, Impureza de Gini com suas fórmulas e como o algoritmo de aprendizado de máquina a resolve.
A estas alturas, Espero que você tenha uma ideia sobre a árvore de decisão, um dos melhores algoritmos de aprendizado de máquina para resolver um problema de classificação.
Como novo, Aconselho você a aprender essas técnicas e entender sua implementação e, em seguida, implementá-las em seus modelos.
para melhor compreensão, consulte https://scikit-learn.org/stable/modules/tree.html
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.





