
Com o aumento do poder computacional, agora podemos selecionar algoritmos que realizam cálculos muito intensivos. Um desses algoritmos é o “Floresta aleatória”, que vamos falar neste post. Embora o algoritmo seja muito popular em várias competições (como um exemplo, aqueles que correm em Kaggle), o resultado final do modelo é como uma caixa preta e, por isso, deve ser usado sabiamente.
Antes de continuar, aqui está um exemplo sobre a relevância de selecionar o melhor algoritmo.
Relevância da seleção do algoritmo certo
Ontem eu vi um filme chamado ” A Era do Amanhã“. Eu amei o conceito e o procedimento de pensamento que estava por trás do enredo deste filme.. Deixe-me resumir o enredo (sem comentar sobre o clímax, Certo). Ao contrário de outros filmes de ficção científica, este filme gira em torno de um único poder que é concedido em ambos os lados. (herói e vilão). Energia é a capacidade de reiniciar o dia.
A raça humana está em guerra com uma espécie alienígena chamada “Imita”. A mímica é descrita como uma civilização muito mais evoluída do que uma espécie exótica.. Toda a civilização Mimímica é como um único organismo completo. Tem um cérebro central chamado “Ômega” que controla todos os outros organismos da civilização. Mantenha contato com todas as outras espécies de civilização a cada segundo. "Alfa" é a principal espécie guerreira (como o sistema nervoso) desta civilização e assume o comando de "Ômega". “Ômega” tem o poder de reiniciar o dia a qualquer momento.
Agora, vamos usar o chapéu de um analista preditivo para analisar este enredo. Se um sistema tem a capacidade de reiniciar o dia a qualquer momento, usará este poder sempre que qualquer uma de suas espécies guerreiras morre. E, por isso, não haverá uma única guerra, quando qualquer uma das espécies guerreiras (alfa) vai realmente morrer, e o cérebro “Ômega” teste repetidamente o melhor cenário para maximizar a morte da raça humana e limitar o número de mortes alfa (espécies guerreiras) a zero todos os dias. Você pode imaginar isso como “O MELHOR” algoritmo preditivo nunca criado. É literalmente impossível derrotar tal algoritmo.
Vamos voltar agora para “Florestas aleatórias” usando um estudo de caso.
Caso de estudo
Abaixo está uma distribuição da receita anual Gini Coeficientes em diferentes países:
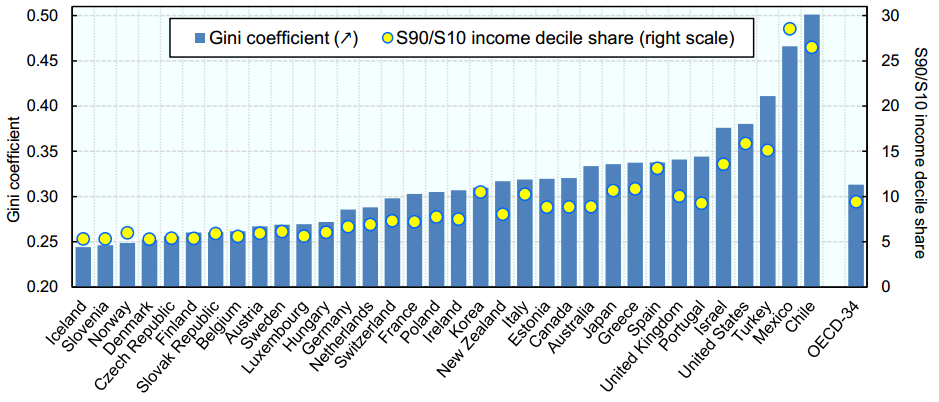
México tem o segundo maior coeficiente de Gini e, por isso, tem uma segregação muito alta na renda anual de ricos e pobres. Nossa tarefa é criar um algoritmo preditivo preciso para estimar o nível de renda anual de cada indivíduo no México.. As faixas de renda são as seguintes:
1. Menos do que $ 40,000
2. $ 40 000 – 150 000
3. Mais de $ 150 000
Abaixo estão as informações disponíveis para cada indivíduo:
1. Era, 2. Gênero, 3. Maior qualificação educacional, 4. Trabalhando na indústria, 5. Residência metroviária / Sem metrô
Precisamos criar um algoritmo para dar uma previsão precisa para um indivíduo que tem as seguintes características::
1. Era: 35 anos, 2, Gênero: Masculino, 3. Maior qualificação educacional: Graduado, 4. Indústria: Fábrica, 5. Residência: Metro
Só vamos falar sobre floresta aleatória para fazer esta previsão neste post.
O algoritmo da Floresta Aleatória
A floresta aleatória é como um algoritmo de bota com o modelo de árvore de decisão (CARRINHO). Digamos que temos 1000 observações em toda a população com 10 variáveis. Floresta aleatória tenta construir vários modelos cart com diferentes amostras e diferentes variáveis iniciais. Como um exemplo, uma amostra aleatória de 100 observações e 5 Variáveis iniciais escolhidas aleatoriamente para construir um modelo CART. Repita o procedimento (Digamos) 10 vezes e, posteriormente, fazer uma previsão final em cada observação. A previsão final é uma função de cada previsão. Esta previsão final pode ser simplesmente a média de cada previsão..
De volta ao estudo de caso
Isenção de responsabilidade: os números neste post são ilustrativos
México tem uma população de 118 MILÍMETROS. Digamos que o algoritmo da Floresta Aleatória coleta 10k de observações com apenas uma variável (para simplificar) para construir cada modelo CART. No total, estamos olhando para o modelo de 5 CART que está sendo construído com diferentes variáveis. Em um obstáculo da vida real, terá mais amostras populacionais e diferentes combinações de variáveis de entrada.
Faixas salariais:
Banda 1: Menos do que $ 40,000
Banda 2: $ 40 000 – 150 000
Banda 3: mais de $ 150,000
Abaixo estão os resultados do 5 diferentes modelos CART.
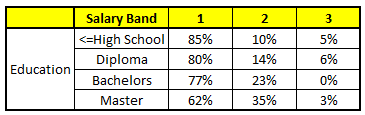
CARRINHO DE COMPRAS 1: Idade variável
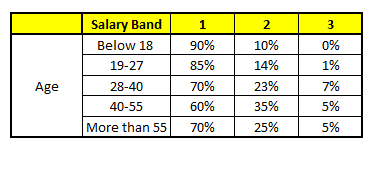
CARRINHO DE COMPRAS 2: Gênero variável
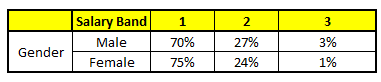
CARRINHO DE COMPRAS 3: Educação variável
CARRINHO DE COMPRAS 4: Residência variável

CARRINHO DE COMPRAS 5: Indústria variável
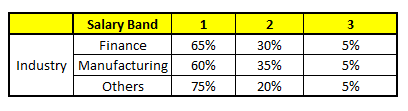
Usando estes 5 Modelos CART, precisamos chegar a um único conjunto de probabilidade de pertencer a cada uma das classes salariais. Para simplificar, vamos tomar apenas uma média de probabilidades neste estudo de caso. Além da média simples, também consideramos o método de votação para alcançar a previsão final. Para alcançar a previsão final, vamos colocar o seguinte perfil em cada modelo CART:
1. Era: 35 anos, 2, Gênero: Masculino, 3. Maior qualificação educacional: Graduado, 4. Indústria: Fábrica, 5. Residência: Metro
Para cada um desses modelos CART, abaixo está a distribuição entre as faixas salariais:
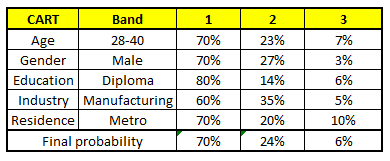
A probabilidade final é simplesmente a média da probabilidade nas mesmas faixas salariais em diferentes modelos CART.. Como você pode ver a partir desta análise, há um 70% de chances deste indivíduo cair na classe 1 (Menos de $ 40,000) e em torno do 24% de chances do indivíduo cair na classe 2.
Notas finais
Floresta aleatória fornece previsões muito mais precisas em comparação com modelos cart simples / CHAID ou regressão em muitos cenários. Esses casos geralmente têm um grande número de variáveis preditivas e um enorme tamanho amostral.. Isso porque captura a variância de várias variáveis de entrada ao mesmo tempo e permite que um grande número de observações participe da previsão.. Em alguns dos próximos posts, vamos falar mais sobre o algoritmo em mais detalhes e falar sobre como construir uma simples floresta aleatória em R.





