Introdução
El análisis exploratorio de datos es una de las mejores prácticas que se utilizan en la ciencia de datos en la actualidad. Al comenzar una carrera en ciencia de datos, las personas generalmente no conocen la diferencia entre el análisis de datos y el análisis de datos exploratorio. No hay una gran diferencia entre los dos, pero ambos tienen propósitos diferentes.

Análise exploratória de dados (EDA): el análisis de datos exploratorios es un complemento Estatística inferencial, que tiende a ser bastante rígido con reglas y fórmulas. En un nivel avanzado, EDA implica mirar y describir el conjunto de datos desde diferentes ángulos y luego resumirlo.
Analise de dados: el análisis de datos es la estadística y la probabilidad de descubrir tendencias en el conjunto de datos. Se utiliza para mostrar datos históricos mediante el uso de algunas herramientas de análisis. Ayuda a desglosar la información para transformar métricas, hechos y cifras en iniciativas de mejora.
Análise exploratória de dados (EDA)
Exploraremos un conjunto de datos y realizaremos el análisis de datos exploratorio en Python. Puede consultar nuestro curso de python en línea para subir a bordo con Python.
Los principales temas que se cubrirán son los siguientes:
– Manejar valor faltante
– Remover duplicatas
– Tratamiento de valores atípicos
– NormalizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos.... y escalado (variables numéricas)
– Codificação de variáveis categóricas (variáveis falsas)
– Análise bivariada
# Importação de bibliotecas

# Carregando o conjunto de dados
Cargaremos el archivo de Excel de autos EDA usando pandas. Para isto, usaremos el archivo read_excel.
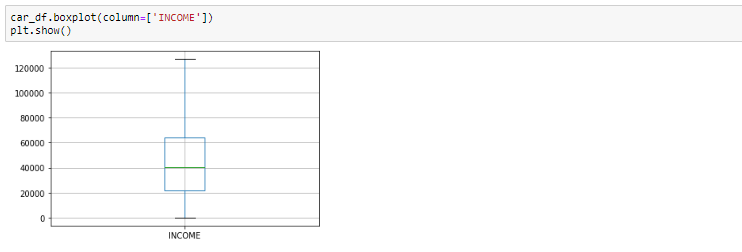
Diagrama de caja después de eliminar valores atípicos
# Exploración básica de datos
Nesta etapa, realizaremos las siguientes operaciones para verificar de qué se compone el conjunto de datos. Comprobaremos las siguientes cosas:
– jefe del conjunto de datos
– la forma del conjunto de datos
– informações do conjunto de dados
– retomar del conjunto de datos
- La función de cabeza le dirá los mejores registros en el conjunto de datos. Por padrão, Python le muestra solo los 5 registros principales.
-
El atributo de forma nos dice una serie de observaciones y variables que tenemos en el conjunto de datos. Se utiliza para verificar la dimensão"Dimensão" É um termo usado em várias disciplinas, como a física, Matemática e filosofia. Refere-se à extensão em que um objeto ou fenômeno pode ser analisado ou descrito. Em física, por exemplo, fala-se de dimensões espaciais e temporais, enquanto em matemática pode se referir ao número de coordenadas necessárias para representar um espaço. Compreendê-lo é fundamental para o estudo e... dos dados. El conjunto de datos de automóviles tiene 303 observações e 13 variables en el conjunto de datos.


-
informação () se utiliza para verificar la información sobre los datos y los tipos de datos de cada atributo respectivo.

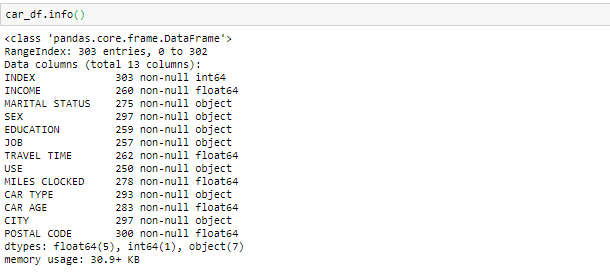
Al observar los datos en la función principal y en la información, sabemos que la variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... Ingresos y el tiempo de viaje son de tipo de datos flotantes en lugar del objeto. Entonces lo convertiremos en el flotador. O que mais, hay algunos valores no válidos como @@ y ‘*‘en los datos que trataremos como valores perdidos.

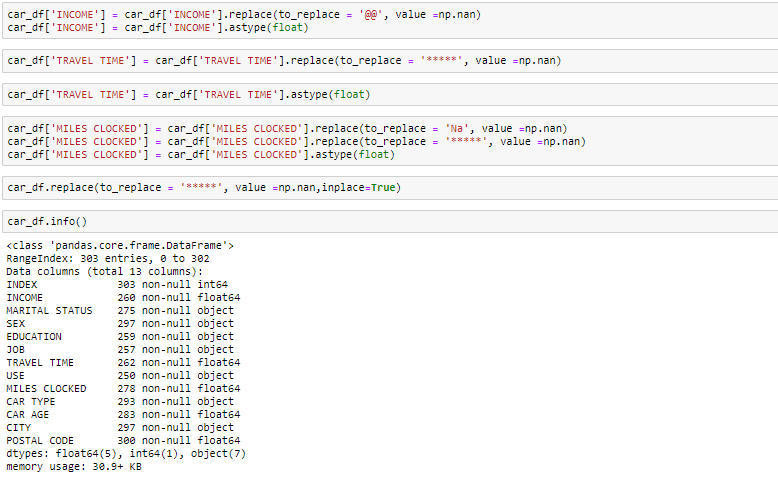
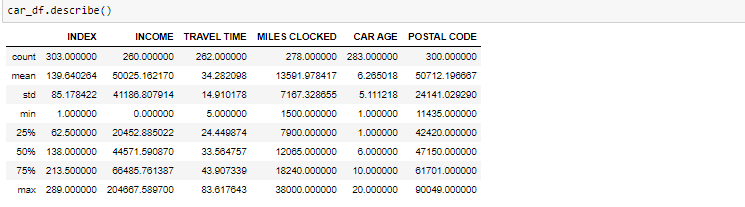
-
El método descrito ayudará a ver cómo se han distribuido los datos para valores numéricos. Podemos ver claramente el valor mínimo, valores medios, diferentes valores de percentiles y valores máximos.

Manejo del valor faltante
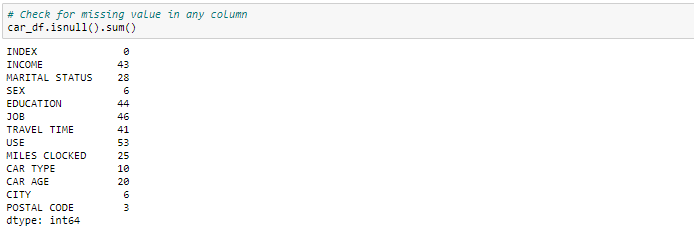
Podemos ver que tenemos varios valores perdidos en las respectivas columnas. Hay varias formas de tratar los valores perdidos en el conjunto de datos. Y qué técnica usar cuando realmente depende del tipo de datos con los que está tratando.
- Elimina los valores perdidos: neste caso, eliminamos los valores perdidos de esas variables. En caso de que falten muy pocos valores, puede eliminarlos.
- Imputar con valor medio: para la columna numérica, puede reemplazar los valores faltantes con valores medios. Antes de reemplazar con el valor medio, es recomendable verificar que la variable no debe tener valores extremos .ie valores atípicos.
- Imputar con valor mediano: para la columna numérica, también puede reemplazar los valores faltantes con valores medianos. En caso de que tenga valores extremos, como valores atípicos, es aconsejable utilizar el método de la medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos.....
- Imputar con valor de modo: para la columna categórica, puede reemplazar los valores faltantes con valores de modo, quer dizer, los frecuentes.
Neste exercício, reemplazaremos las columnas numéricas con valores medianos y, para las columnas categóricas, eliminaremos los valores faltantes.
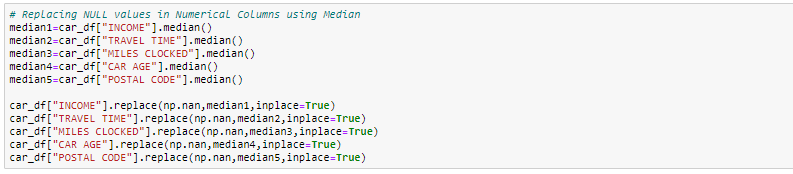
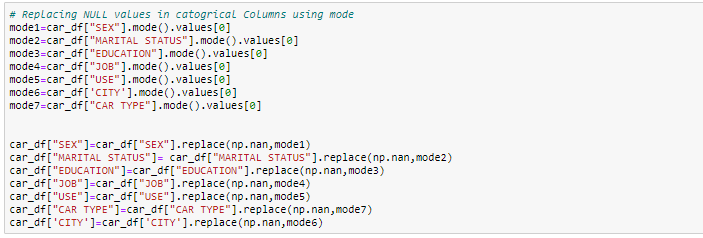

Manejo de registros duplicados
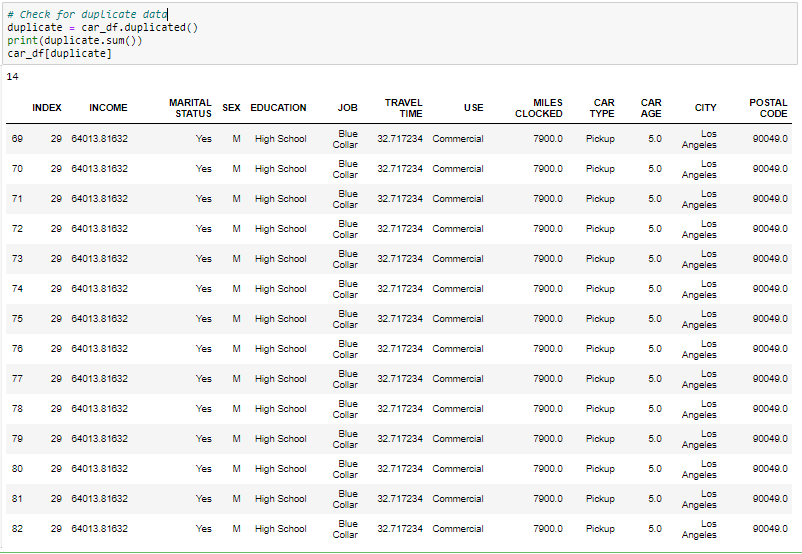
Dado que tenemos 14 registros duplicados en los datos, lo eliminaremos del conjunto de datos para obtener solo registros distintos. Después de eliminar el duplicado, comprobaremos si los duplicados se han eliminado del conjunto de datos o no.
![]()
![]()

Tratamento de outliers
Los valores atípicos, al ser las observaciones más extremas, pueden incluir el máximo o mínimo de la muestra, o ambos, dependiendo de si son extremadamente altos o bajos. Porém, el máximo y el mínimo de la muestra no siempre son valores atípicos porque pueden no estar inusualmente lejos de otras observaciones.
Generalmente identificamos valores atípicos con la ayuda del diagrama de caja, por lo que aquí el diagrama de caja muestra algunos de los puntos de datos fuera del rango de los datos.
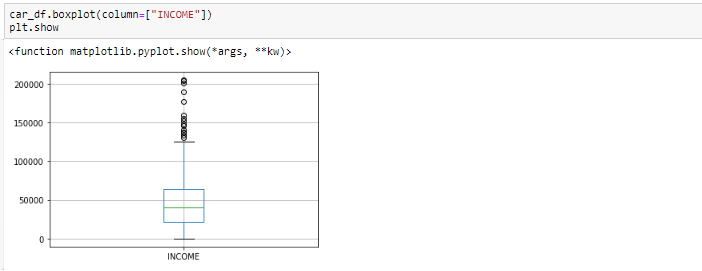
Diagrama de caja antes de eliminar valores atípicos
Mirando el diagrama de caja, parece que las variables INGRESO, tienen valores atípicos presentes en las variables. Estos valores atípicos deben tenerse en cuenta y hay varias formas de tratarlos:
- Elimina el valor atípico
- Reemplazar el valor atípico usando el IQR
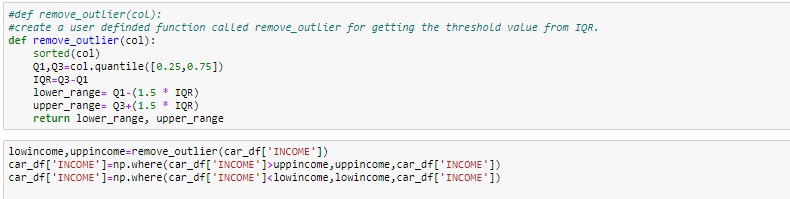
#Boxplot Después de eliminar el valor atípico
Análise bivariada
Cuando hablamos de análisis bivariado, significa analizar 2 variáveis. Como sabemos que hay variables numéricas y categóricas, hay una forma de analizar estas variables como se muestra a continuación:
-
Numérico vs numérico
1. Diagrama de dispersãoO gráfico de dispersão é uma ferramenta gráfica usada em estatística para visualizar a relação entre duas variáveis. Consiste em um conjunto de pontos em um plano cartesiano, onde cada ponto representa um par de valores correspondentes às variáveis analisadas. Este tipo de gráfico permite identificar padrões, Tendências e possíveis correlações, facilitando a interpretação dos dados e a tomada de decisão com base nas informações visuais apresentadas....
2. Gráfico de linhaO gráfico de linhas é uma ferramenta visual usada para representar dados ao longo do tempo. Consiste em uma série de pontos conectados por linhas, que permite observar tendências, Flutuações e padrões nos dados. Esse tipo de gráfico é especialmente útil em áreas como economia, Meteorologia e pesquisa científica, facilitando a comparação de diferentes conjuntos de dados e a identificação de comportamentos em geral..
3. Mapa de caloruma "mapa de calor" é uma representação gráfica que usa cores para mostrar a densidade de dados em uma área específica. Comumente usado em análise de dados, Estudos de marketing e comportamentais, Esse tipo de visualização permite identificar padrões e tendências rapidamente. Através de variações cromáticas, Os mapas de calor facilitam a interpretação de grandes volumes de informações, ajudando a tomar decisões informadas.... para la correlación
4. Parcela conjunta -
Categórico vs Numérico
1. Gráfico de barrasO gráfico de barras é uma representação visual de dados que usa barras retangulares para mostrar comparações entre diferentes categorias. Cada barra representa um valor e seu comprimento é proporcional a ele. Esse tipo de gráfico é útil para visualizar e analisar tendências, facilitar a interpretação de informações quantitativas. É amplamente utilizado em várias disciplinas, como estatísticas, Marketing e pesquisa, devido à sua simplicidade e eficácia....
2. Moldura de violino
3. Diagrama de caja categórico
4.parcela tibia -
Dos variables categóricas
1. Gráfico de barras
2. Gráfico de barras agrupado
3. Gráfico de puntos
Si necesitamos encontrar la correlación-
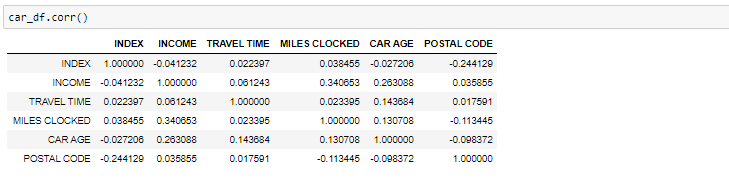
Correlación entre todas las variables
Normalizar y escalar
Frequentemente, las variables del conjunto de datos son de diferentes escalas, quer dizer, una variable está en millones y otras en solo 100. Por exemplo, em nosso conjunto de dados, la renta tiene valores en miles y la edad en solo dos dígitos. Dado que los datos de estas variables son de diferentes escalas, es difícil comparar estas variables.
La escala de características (también conocida como normalización de datos) es el método utilizado para estandarizar el rango de características de los datos. Dado que el rango de valores de los datos puede variar ampliamente, se convierte en un paso necesario en el preprocesamiento de datos mientras se utilizan algoritmos de aprendizaje automático.
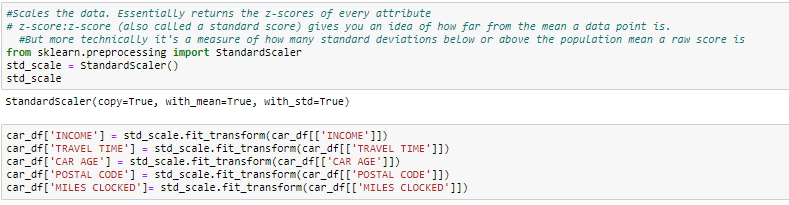
Neste método, convertimos variables con diferentes escalas de medidas en una sola escala. StandardScaler normaliza los datos utilizando la fórmula (x-mean) / Desvio padrão. Haremos esto solo para las variables numéricas.
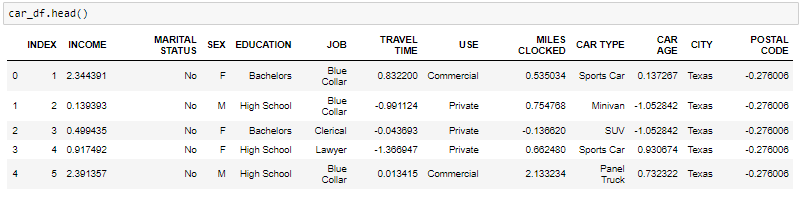
CODIFICACIÓN
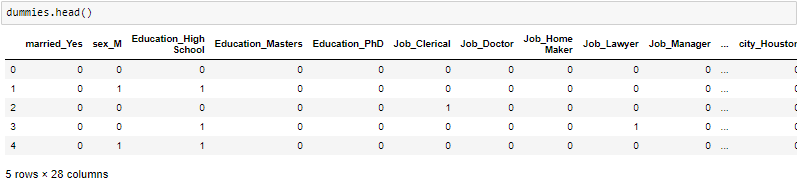
One-Hot-Encoding se usa para crear variables ficticias para reemplazar las categorías en una variable categórica en características de cada categoría y representarla usando 1 o 0 según la presencia o ausencia del valor categórico en el registro.
Esto es necesario, ya que los algoritmos de aprendizaje automático solo funcionan con datos numéricos. Por eso es necesario convertir la columna categórica en numérica.
get_dummies es el método que crea una variable ficticia para cada variable categórica.

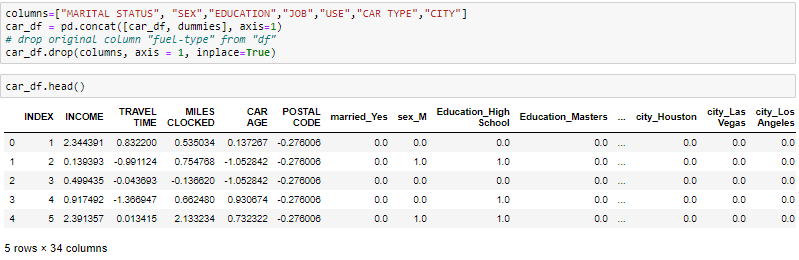
Sobre o autor

Ritika Singh – Científica de datos
Soy un científico de datos de profesión y un blogger por pasión. He trabajado en proyectos de aprendizaje automático durante más de 2 anos. Aquí encontrará artículos sobre “Machine Learning, Estatisticas, Aprendizado Profundo, PNL e Inteligencia Artificial”.





