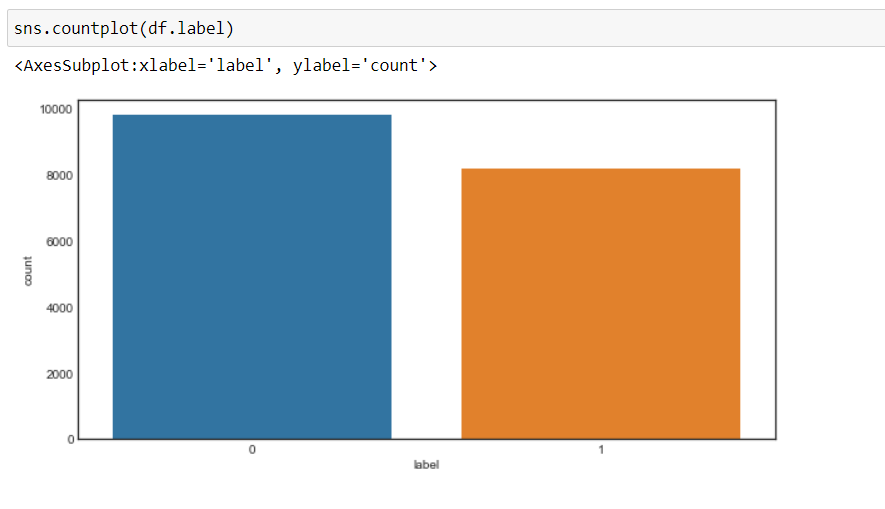
Agora, podemos ver que nosso objetivo mudou para 0 e 1, quer dizer, 0 para negativo e 1 para positivo, e os dados são mais ou menos em um estado equilibrado.
Pré-processamento de dados
Agora, pré-processaremos os dados antes de convertê-lo em vetores e passá-lo para o modelo de aprendizado de máquina.
Criaremos uma função para pré-processamento de dados.
1. Primeiro, vamos iterar através de cada registro e usar um expressão regular, vamos remover quaisquer caracteres além dos alfabetos.
2. Mais tarde, vamos converter a sequência para minúscula O que, palavra “Nós vamos” é diferente da palavra “Boa”.
Porque, não convertido para minúscula, causará um problema quando criarmos vetores dessas palavras, uma vez que dois vetores diferentes serão criados para a mesma palavra que não queremos.
3. Mais tarde, vamos procurar por palavras vazias nos dados e excluí-los. Por palavras são comumente usadas palavras em uma frase como “a”, “uma”, “uma”, etc. que não agregam muito valor.
4. Mais tarde, vamos realizar lematización em cada palavra, quer dizer, alterar as diferentes formas de uma palavra em um único elemento chamado um lema.
UMA lema é uma forma básica de uma palavra. Por exemplo, “corre”, “para correr” e “corre” são todas as formas do mesmo léxico, Onde “corre” é o lema. Portanto, estamos convertendo todas as aparições do mesmo léxico para seu respectivo lema.
5. E, em seguida, retornar um corpus de dados processados.
Mas primeiro criaremos um objeto WordNetLemmatizer e, em seguida, executaremos a transformação.
#object of WordNetLemmatizer
lm = WordNetLemmatizer()
def text_transformation(df_col):
corpus = []
para item em df_col:
new_item = re.sub('[^ a-zA-Z]',' ',str(item))
new_item = new_item.inferior()
new_item = new_item.split()
new_item = [lm.lemmatize(palavra) por palavra em new_item se a palavra não no conjunto(stopwords.words('inglês'))]
corpus.append(' '.join(str(x) para x em new_item))
corpo de retorno
corpus = text_transformation(df['text'])
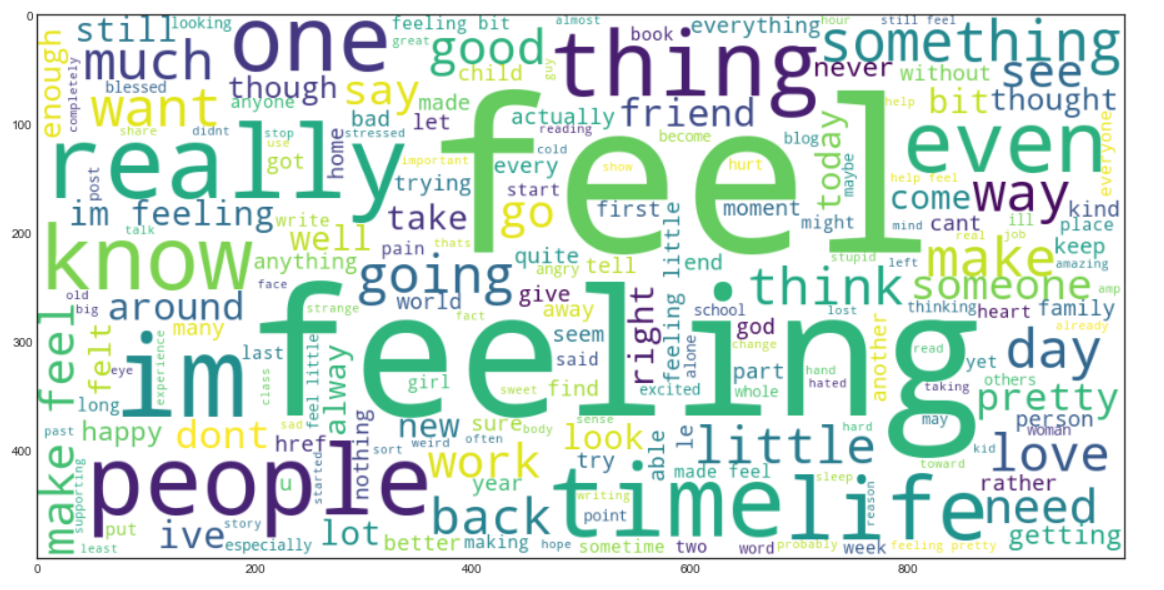
Agora vamos criar um Palavra nuvem. É uma técnica de visualização de dados que é usada para representar o texto de tal forma que as palavras mais frequentes aparecem ampliadas em comparação com as palavras menos frequentes.. Isso nos dá uma pequena visão de como os dados se parecem depois de serem processados em todas as etapas até agora..
rcParams['figure.figsize'] = 20,8
word_cloud = ""
para linha em corpus:
para palavra na linha:
word_cloud+=" ".Junte(palavra)
wordcloud = WordCloud(largura = 1000, altura = 500.background_color="Branco",min_font_size = 10).gerar(palavra nuvem)
plt.imshow(palavra nuvem)
Produção:
Saco de palavras
Agora, vamos usar o Modelo word bag (ARCO), que é usado para representar o texto na forma de um saco de palavras, quer dizer, gramática e ordem de palavra em uma frase não são dadas nenhuma importância, em vez de, multiplicidade , quer dizer (o número de vezes que uma palavra aparece em um documento) é a principal causa de preocupação.
Basicamente, descreve a ocorrência total de palavras dentro de um documento.
Scikit-Learn fornece uma maneira ordenada de executar a técnica do saco de palavras usando CondeVectorizador.
Agora, vamos converter os dados de texto em vetores, ajustando e transformando o corpus que criamos.
cv = CondeVectorizer(ngram_range=(1,2))
dados de trem = cv.fit_transform(corpus)
X = traindata
y = df.label
Nós vamos levá-lo ngram_range O que (1,2) o que significa um bigrama.
Ngram é uma sequência de 'n’ palavras em uma linha ou frase. ngram_range’ é um parâmetro, que usamos para dar importância à combinação de palavras, O que “mídias sociais” tem um significado diferente do que “social” e “meios de comunicação” separadamente.
Podemos experimentar com o valor do ngram_range parâmetro e selecione a opção que dá melhores resultados.
Agora vem a parte de criar o modelo de aprendizado de máquina e neste projeto, Vou vestir Classificador florestal aleatório, e vamos ajustar os hiperparmetros usando GridSearchCV.
GridSearchCV() tomará los siguientes parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto....,
1. Estimadoro "Estimador" é uma ferramenta estatística usada para inferir características de uma população a partir de uma amostra. Ele se baseia em métodos matemáticos para fornecer estimativas precisas e confiáveis. Existem diferentes tipos de estimadores, como o imparcial e o consistente, escolhidos de acordo com o contexto e objetivo do estudo. Seu uso correto é essencial na pesquisa científica, levantamentos e análise de dados.... o modelo – RandomForestClassifier em nosso caso
2. parametros: dicionário de nomes hiperparâmetros e seus valores
3. cv: significa dobras de validação cruzada
4. return_train_score: devuelve las puntuaciones de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... de los distintos modelos
5. n_jobs – não. de empregos para executar em paralelo (“-1” significa que todos os núcleos de cpu serão usados, o que reduz drasticamente o tempo de treinamento)
Primeiro, vamos criar um dicionário, “parametros” que conterá os valores de diferentes hiperparmetros.
Passaremos isso como um parâmetro para gridSearchCV para treinar nosso modelo de classificador florestal aleatório usando todas as combinações possíveis desses parâmetros para encontrar o melhor modelo.
parâmetros = {'max_features': ('auto','sqrt'),
'n_estimators': [500, 1000, 1500],
'max_depth': [5, 10, Nenhum],
'min_samples_split': [5, 10, 15],
'min_samples_leaf': [1, 2, 5, 10],
'bootstrap': [Verdade, Falso]}
Agora, vamos ajustar os dados na pesquisa de grade e ver o melhor parâmetro usando o atributo “best_params_” da GridSearchCV.
grid_search = GridSearchCV(RandomForestClassifier(),parametros,cv=5.return_train_score=True,n_jobs = -1) grid_search.fit(X,e) grid_search.best_params_
Produção:

E logo, podemos ver todos os modelos e seus respectivos parâmetros, a pontuação média do teste e a classificação, desde gridSearchCV armazena todos os resultados no cv_results_ atributo.
para eu no alcance(432):
imprimir('Parameters: ',grid_search.cv_results_['params'][eu])
imprimir('Mean Test Score: ',grid_search.cv_results_['mean_test_score'][eu])
imprimir('Rank: ',grid_search.cv_results_['rank_test_score'][eu])
Partida: (uma amostra da saída)

Agora, escolheremos os melhores parâmetros obtidos da GridSearchCV e criaremos um modelo final de classificador florestal aleatório e, em seguida, treinaremos nosso novo modelo.
rfc = RandomForestClassifier(max_features=grid_search.best_params_['max_features'], max_depth=grid_search.best_params_['max_depth'], n_estimators=grid_search.best_params_['n_estimators'], min_samples_split=grid_search.best_params_['min_samples_split'], min_samples_leaf=grid_search.best_params_['min_samples_leaf'], bootstrap=grid_search.best_params_['bootstrap']) rfc.fit(X,e)
Transformação de dados de teste
Agora, vamos ler os dados do teste e realizar as mesmas transformações que fizemos nos dados de treinamento e finalmente avaliar o modelo em suas previsões.
test_df = pd.read_csv('test.txt',delimitador=";",nomes =['text','label'])
X_test,y_test = test_df.text,test_df.label #encode the labels into two classes , 0 e 1 test_df = custom_encoder(y_test) #pre-processing of text test_corpus = text_transformation(X_test) #convert text data into vectors testdata = cv.transform(test_corpus) #predict the target predictions = rfc.predict(dados de teste)
Avaliação de modelo
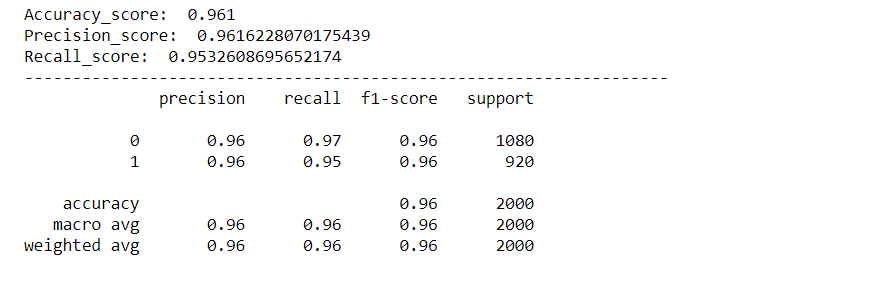
Evaluaremos nuestro modelo usando varias métricas como Accuracy Score, Pontuação de precisão, Pontuação de recall, Confusão Matriz y crearemos una curva roc para visualizar cómo se desempeñó nuestro modelo.
rcParams['figure.figsize'] = 10,5 plot_confusion_matrix(y_test,previsões) acc_score = accuracy_score(y_test,previsões) pre_score = precision_score(y_test,previsões) rec_score = recall_score(y_test,previsões) imprimir('Accuracy_score: ',acc_score) imprimir('Precision_score: ',pre_score) imprimir('Recall_score: ',rec_score) imprimir("-"*50) cr = classification_report(y_test,previsões) imprimir(Cr)
Produção:
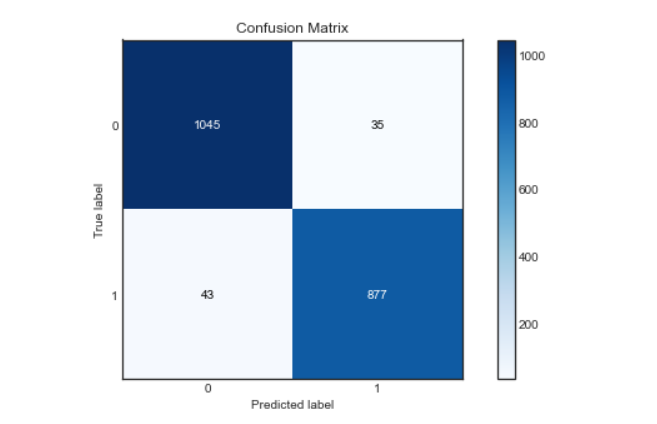
Matriz de confusão:
Curva de Roc:
Encontraremos la probabilidad de la clase usando el método predict_proba () de Random Forest Classifier y luego trazaremos la curva roc.
predictions_probability = rfc.predict_proba(dados de teste)
fpr,Tpr,limiares = roc_curve(y_test,predictions_probability[:,1])
plt.plot(fpr,Tpr)
plt.plot([0,1])
plt.title('ROC Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Como podemos ver, nosso modelo funcionou muito bem na classificação de sentimentos, com uma pontuação de precisão, precisão e recuperação de aproximadamente. 96%. E a curva roc e a matriz de confusão também são excelentes., o que significa que nosso modelo pode classificar rótulos com precisão, com menos chance de erro.
Agora, também verificaremos a entrada personalizada e deixaremos que nosso modelo identifique o sentimento da declaração de entrada.
Prever para entrada personalizada:
def expression_check(prediction_input):
se prediction_input == 0:
imprimir("A declaração de entrada tem sentimento negativo.")
elif prediction_input == 1:
imprimir("A declaração de entrada tem sentimento positivo.")
outro:
imprimir("Declaração inválida.")
# function to take the input statement and perform the same transformations we did earlier
def sentiment_predictor(entrada):
insumo = text_transformation(entrada)
transformed_input = cv.transform(entrada)
previsão = rfc.predict(transformed_input)
expression_check(predição)
insumo1 = ["Às vezes só quero dar um soco na cara de alguém."]
insumo2 = ["I bought a new phone and it's so good."]
sentiment_predictor(entrada1) sentiment_predictor(entrada2)
Produção:
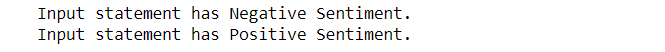
Viva, como podemos ver que nosso modelo classificou com precisão os sentimentos por trás das duas frases.
se você gosta deste item, siga-me em LinkedIn.
E você pode obter o código completo e saída de aqui.
Imagens de saída são mantidas aqui para referência.
Fim?
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.





