Este artigo foi publicado como parte do Data Science Blogathon
Introdução
O objetivo final deste blog é prever o sentimento de um determinado texto usando python, onde usamos NLTK, também conhecido como Natural Language Processing Toolkit, um pacote Python especialmente criado para análise baseada em texto. Então, com algumas linhas de código, podemos facilmente prever se é uma frase ou uma crítica (usado no blog) é uma crítica positiva ou negativa.
Antes de passar diretamente para a implementação, deixe-me resumir as etapas envolvidas para ter uma ideia da abordagem analítica. Estes são nomeadamente:
1. Importação de módulos necessários
2. Importação de conjunto de dados
3. Pré-processamento e visualização de dados
4. Construção de maquete
5. Predição
Então, vamos nos concentrar em cada etapa em detalhes.
1. Importação de módulos necessários:
Então, como todos sabemos, é necessário importar todos os módulos que vamos usar inicialmente. Então vamos fazer isso como o primeiro passo da nossa prática..
import numpy as np #linear algebra import pandas as pd # processamento de dados, I/O do arquivo CSV (por exemplo. pd.read_csv) import matplotlib.pyplot as plt #For Visualisation %matplotlib inline import seaborn as sns #For better Visualisation from bs4 import BeautifulSoup #For Text Parsing
Aqui estamos importando todos os módulos básicos de importação necessários, a saber, entorpecido, pandas, matplotlib, seaborn e bela sopa, cada um com seu próprio caso de uso. Embora vamos usar alguns outros módulos, excluindo-os, vamos entendê-los ao usá-los.
2. Importação de conjunto de dados:
De fato, Eu tinha baixado o conjunto de dados do Kaggle há algum tempo, então eu não tenho o link para o conjunto de dados. Então, para obter o conjunto de dados e o código, Vou colocar o link do repositório Github para que todos tenham acesso a ele. Agora, para importar o conjunto de dados, temos que usar o método read_csv dos pandas’ seguido pelo caminho do arquivo.
data = pd.read_csv('Reviews.csv')
Se imprimirmos o conjunto de dados, pudemos ver que há ‘568454 linhas × 10 colunas ', que é bem grande.
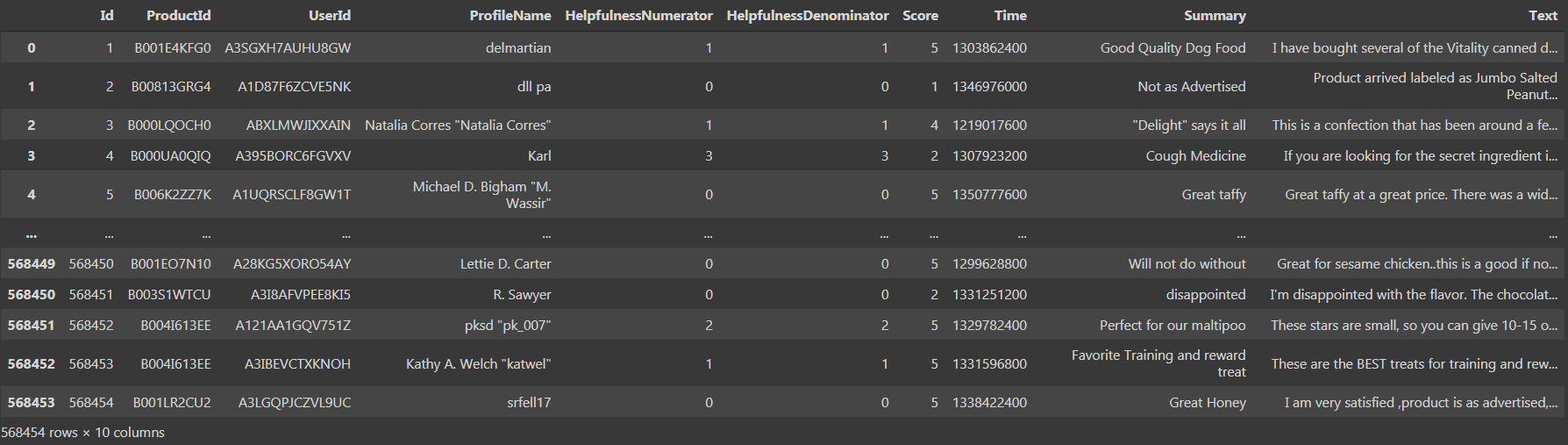
Nós vemos que há 10 colunas, a saber, 'Identificação', ‘Numerador utilitário’, ‘Denominador de utilidade’, 'Pontuação’ e tempo’ como tipo de dados int64 e 'ProductId', 'ID do usuário', 'Nome do perfil', 'Resumo', 'Texto’ como tipo de dados de objeto. Agora vamos para a terceira etapa, quer dizer, pré-processamento e visualização de dados.
3. Pré-processamento e visualização de dados:
Agora temos acesso aos dados e depois os limpamos. Usando o método 'isnull (). Soma ()’ poderíamos encontrar facilmente o número total de valores ausentes no conjunto de dados.
data.isnull().soma()
Se executarmos o código acima como uma célula, descobrimos que existe 16 e 27 valores nulos nas colunas ‘ProfileName’ y ‘Resumo’ respectivamente. Agora, temos que substituir os valores nulos pela tendência central ou remover as respectivas linhas contendo os valores nulos. Com um número tão grande de linhas, removendo solo 43 linhas contendo os valores nulos não afetariam a precisão geral do modelo. Portanto, é aconselhável eliminar 43 linhas usando o método 'dropna'.
data = data.dropna()
Agora, he actualizado el marco de datos antiguo en lugar de crear una nueva variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... y almacenar el nuevo marco de datos con los valores limpios. Agora, de novo, quando verificamos o quadro de dados, descobrimos que existe 568411 linhas e o mesmo 10 colunas, o que significa que 43 linhas que tinham os valores nulos foram removidas e agora nosso conjunto de dados está limpo. Continuando, temos que pré-processar os dados de tal forma que o modelo possa usá-los diretamente.
Para pré-processador, usamos a coluna ‘Pontuação’ no quadro de dados para ter pontuações variando de '1’ um ‘5’, onde '1’ significa uma crítica negativa e '5’ significa uma crítica positiva. Mas é melhor ter a pontuação inicialmente em uma faixa de ‘0’ um ‘2’ Onde ‘0’ significa uma crítica negativa, ‘1’ significa uma revisão neutra e '2’ significa uma crítica positiva. É semelhante à codificação em Python, mas aqui não usamos nenhuma função integrada, pero ejecutamos explícitamente un bucle for onde"ONDE" é um termo em inglês que se traduz como "Onde" em espanhol. Usado para fazer perguntas sobre a localização das pessoas, Objetos ou eventos. Em contextos gramaticais, Pode funcionar como advérbio de lugar e é fundamental na formação de perguntas. Sua correta aplicação é essencial na comunicação cotidiana e no ensino de idiomas, facilitando a compreensão e troca de informações sobre posições e direções.... y creamos una nueva lista y agregamos los valores a la lista.
a =[]
para mim nos dados['Pontuação']:
se eu <3:
a.append(0)
se eu == 3:
a.append(1)
se eu>3:
a.append(2)
Supondo que o 'Score’ está na faixa de ‘0’ um ‘2’, Nós os consideramos comentários negativos e os adicionamos à lista com uma pontuação de ‘0’, o que significa crítica negativa. Agora, se representarmos graficamente os valores das pontuações presentes na lista 'a’ como a nomenclatura usada acima, descobrimos que existe 82007 críticas negativas, 42638 críticas neutras e 443766 críticas positivas. Podemos descobrir claramente que aproximadamente o 85% das revisões no conjunto de dados têm críticas positivas e as restantes são críticas negativas ou neutras. Isso poderia ser mais claramente visualizado e compreendido com a ajuda de um gráfico de contagem na biblioteca marítima.
sns.countplot(uma)
plt.xlabel('Avaliações', color ="vermelho")
plt.ylabel('Contar', color ="vermelho")
plt.xticks([0,1,2],['Negativo','Neutro','Positivo'])
plt.title('COUNT PLOT', color ="r")
plt.show()
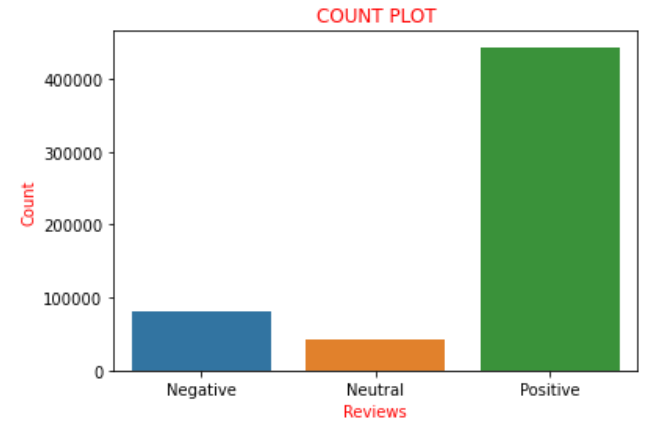
Portanto, o enredo acima retrata claramente todas as frases descritas acima de forma pictórica. Agora eu converto a lista 'para’ que havíamos codificado anteriormente em uma nova coluna chamada 'sentimento’ para o quadro de dados, quer dizer, 'dados'. Agora vem uma reviravolta em que criamos uma nova variável, digamos ‘final_dataset’ onde considero apenas a coluna ‘Sentindo’ e ‘texto’ do quadro de dados, que é a nova estrutura de dados que vamos trabalhar para a próxima parte. A razão por trás disso é que todas as colunas remanescentes são consideradas aquelas que não contribuem para a análise do sentimento., portanto, sem descartá-los, consideramos que o quadro de dados exclui essas colunas. Portanto, essa é a razão para escolher apenas as colunas 'Texto'’ e 'Sentimento'. Nós codificamos o mesmo que abaixo:
dados['Sentimento']=a
final_dataset = data[['Texto','Sentimento']]
final_dataset
Agora, se imprimirmos o 'final_dataset’ e encontramos o caminho, começamos a saber o que há 568411 linhas e apenas 2 colunas. Do final_dataset, se descobrirmos que o número de comentários positivos é 443766 entradas e o número de comentários negativos é 82007. Portanto, há uma grande diferença entre comentários positivos e negativos. Portanto, há mais chance de que os dados se ajustem muito se tentarmos construir o modelo diretamente. Portanto, temos que escolher apenas algumas entradas do final_datset para evitar overfitting. Então, de vários testes, Eu descobri que o valor ideal para o número de revisões a considerar é 5000. Portanto, Eu crio dois novos dados de variáveis’ e 'data’ e armazenar aleatoriamente 5000 críticas positivas e negativas nas variáveis, respectivamente. O código que implementa o mesmo está abaixo:
datap = data_p.iloc[np.random.randint(1,443766,5000), :] datan = data_n.iloc[np.random.randint(1, 82007,5000), :] len(dados), len(datap)
Agora eu crio uma nova variável chamada dados e concateno os valores em 'datap’ e 'data'.
data = pd.concat([datap,dados]) len(dados)
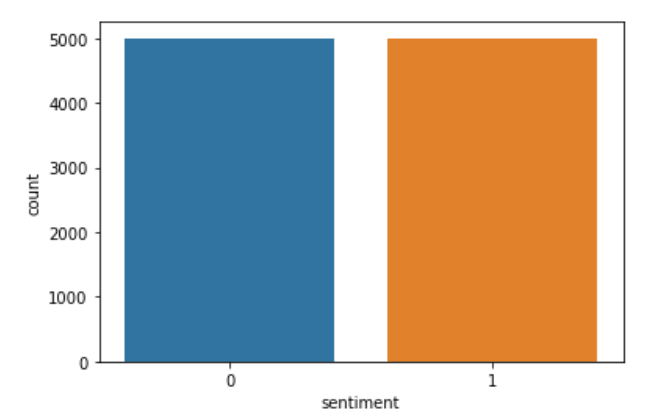
Agora eu crio uma nova lista chamada 'c’ e o que eu faço é semelhante à codificação, mas explicitamente. Eu salvo críticas negativas “0” O que “0” e avaliações positivas “2” antes como “1” sobre “c”. Mais tarde, novamente substituiu os valores de sentimento armazenados em 'c’ nos dados da coluna. Mais tarde, para ver se o código foi executado com sucesso, Eu traço a coluna 'sentimento'. Código que implementa a mesma coisa é:
c =[]
para mim nos dados['Sentimento']:
se i==0:
c.append(0)
se i==2:
c.append(1)
dados['Sentimento']=c
sns.countplot(dados['Sentimento'])
plt.show()
Se vermos os dados, podemos descobrir que existem algumas tags HTML, como os dados foram originalmente obtidos de sites reais de comércio eletrônico. Portanto, podemos descobrir que há tags presentes que precisam ser removidas, como eles não são necessários para a análise do sentimento. Portanto, usamos a função BeautifulSoup que usa o 'html.parser’ e podemos facilmente remover tags indesejadas de comentários. Para realizar a tarefa, Eu crio uma nova coluna chamada 'revisão’ que armazena o texto analisado e elimina a coluna chamada 'sentimento’ para evitar redundância. Eu fiz a tarefa acima usando uma função chamada 'strip_html'. O código para fazer o mesmo é o seguinte:
def strip_html(texto):
sopa = BeautifulSoup(texto, "html.parser")
return soup.get_text()
dados['Reveja'] = dados['Texto'].Aplique(strip_html)
data = data.drop('Texto',eixo = 1)
data.head()
Agora chegamos ao fim de um processo tedioso de pré-processamento e visualização de dados. Portanto, agora podemos continuar para a próxima etapa, quer dizer, construção de modelo.
4. Modelo de construção:
Antes de pularmos diretamente para construir o modelo, precisamos, fazer um pouco de lição de casa. Sabemos que para os humanos classificarem o sentimento, precisamos de artigos, determinantes, conjunções, sinais de pontuação, etc, como podemos entender claramente e, em seguida, avaliar a avaliação. Mas este não é o caso das máquinas, então eles realmente não precisam deles para classificar o sentimento, mas eles ficam literalmente confusos se estiverem presentes. Então, para realizar esta tarefa como qualquer outra análise de sentimento, precisamos usar a biblioteca 'nltk'. NLTK filho las siglas de ‘Natural Language Processing Toolkit’. Esta é uma das melhores bibliotecas para fazer análise de sentimento ou qualquer projeto de aprendizado de máquina baseado em texto. Então, com a ajuda desta biblioteca, primeiro vou remover marcas de pontuação e, em seguida, remover palavras que não adicionam um sentimento ao texto. Primeiro uso uma função chamada "punc_clean’ que remove marcas de pontuação de cada revisão. O código para implementar o mesmo é o seguinte:
import nltk def punc_clean(texto): import string as st a=[w para w em texto se w não em pontuação st.] retorno ''.junte-se(uma) dados['Reveja'] = dados['Reveja'].Aplique(punc_clean) data.head(2)
Portanto, o código acima remove marcas de pontuação. Agora, a seguir, temos que remover palavras que não adicionam um sentimento à frase. Estas palavras são chamadas “palavras vazias”. A lista de quase todas as palavras vazias poderia ser encontrada aqui. A seguir, se verificarmos a lista de palavras vazias, podemos descobrir que ele também contém a palavra “não”. Portanto, é necessário que não remova o “não” a partir de “revisão”, pois adiciona algum valor ao sentimento porque contribui para o sentimento negativo. Portanto, temos que escrever o código de forma a remover outras palavras, exceto o “não”. O código para implementar o mesmo é:
def remove_stopword(texto):
stopword = nltk.corpus.stopwords.words('inglês')
stopword.remove('não')
a =[w para w em nltk.word_tokenize(texto) se não estivermos em palavras irrelevantes]
return '' .join(uma)
dados['Reveja'] = dados['Reveja'].Aplique(remove_stopword)
Portanto, agora temos apenas uma etapa atrás da construção do modelo. O próximo motivo é atribuir a cada palavra em cada revisão uma pontuação de sentimento. Então, para implementá-lo, precisamos usar outra biblioteca do módulo 'sklearn’ o que é o 'TfidVectorizer’ que está presente em ‘feature_extraction.text’. É altamente recomendável acessar o 'TfidVectorizer’ docs para obter uma compreensão clara da biblioteca. Tiene muchos parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... como entrada, codificação, min_df, max_df, ngram_range, binário, tipo d, use_idf e muito mais parâmetros, cada um com seu próprio caso de uso. Portanto, é recomendado passar por isso Blog para obter uma compreensão clara de como o 'TfidVectorizer' funciona. O código que o implementa é:
from sklearn.feature_extraction.text import TfidfVectorizer
vectr = TfidfVectorizer(ngram_range=(1,2),min_df=1)
vectr.fit(dados['Reveja'])
vect_X = vectr.transform(dados['Reveja'])
Agora é hora de construir o modelo. Uma vez que é uma análise de sentimento de classificação de classe binária, quer dizer, ‘1’ refere-se a uma revisão positiva e ‘0’ refere-se a uma revisão negativa. Então, é claro que precisamos usar qualquer um dos algoritmos de classificação. O usado aqui é a regressão logística. Portanto, precisamos importar 'LogisticRegression’ para usá-lo como nosso modelo. Mais tarde, devemos ajustar todos os dados como tal, porque eu senti que é bom testar os dados a partir de dados completamente novos em vez do conjunto de dados disponível. Então eu ajustei todo o conjunto de dados. Então eu uso a função '.score' ()’ para prever a pontuação do modelo. o código que implementa as tarefas mencionadas acima é o seguinte:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
clf=modelo.fit(vect_X,dados['Sentimento'])
clf.score(vect_X,dados['Sentimento'])*100
Se executarmos o trecho de código acima e verificarmos a pontuação do modelo, ficamos entre 96 e 97%, desde que o conjunto de dados muda cada vez que executamos o código, uma vez que consideramos os dados aleatoriamente. Portanto, construímos com sucesso nosso modelo, que também com uma boa pontuação. Então, Por que esperar para testar como nosso modelo funciona no cenário do mundo real? Então, agora vamos para a última e última etapa da 'Predição’ para testar o desempenho do nosso modelo.
5. Predição:
Então, para esclarecer o desempenho do modelo, Usei duas frases simples "Eu amo sorvete" e "Odeio sorvete" que claramente se referem a sentimentos positivos e negativos.. O resultado é o seguinte:

Aqui o '1’ e ele ‘0’ referem-se ao sentimento positivo e negativo, respectivamente. Por que algumas análises do mundo real não são testadas?? Eu peço a vocês, leitores, que verifiquem e provem o mesmo. Na maioria das vezes você obteria a saída desejada, mas se isso não funcionar, Peço que você tente alterar os parâmetros do 'TfidVectorizer’ e definir o modelo para 'LogisticRegression’ para obter a saída necessária. Então, para o qual anexei o link para o código e o conjunto de dados aqui.
Você se conecta comigo através LinkedIn. Espero que este blog seja útil para entender como a análise de sentimento é feita praticamente com a ajuda de códigos Python. Obrigado por ver o blog.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





