Introdução
Quando começa com ciência de dados, começa simples. Você passa por projetos simples como Problema de previsão de empréstimo o Previsão de vendas do Big Mart. Esses problemas têm dados estruturados organizados ordenadamente em um formato tabular. Em outras palavras, Você está alimentado com a parte mais difícil do pipeline de ciência de dados.

Conjuntos de dados na vida real são muito mais complexos.
Você deve entender primeiro, coletar de várias fontes e organizá-lo em um formato que está pronto para processamento. Isso é ainda mais difícil quando os dados estão em um formato não estruturado, como uma imagem ou um áudio. Isso ocorre porque teria que representar os dados da imagem / áudio de uma forma padrão para ser útil para análise.
A abundância de dados não estruturados
curiosamente, dados não estruturados representam uma grande oportunidade inexplorada. Está mais próximo de como nos comunicamos e interagimos como humanos. Ele também contém muitas informações úteis e poderosas. Por exemplo, se uma pessoa fala; você não entende apenas o que diz, mas também quais eram as emoções da pessoa pela voz.
O que mais, a linguagem corporal da pessoa pode mostrar muito mais características sobre uma pessoa, Porque as ações falam mais alto que palavras! Em resumo, dados não estruturados são complexos, mas processá-los pode render recompensas fáceis.
Neste artigo, Pretendo cobrir uma visão geral do processamento de áudio / voz com um estudo de caso para que você possa obter uma introdução prática à solução de problemas de processamento de áudio.
Vamos continuar!
Tabela de conteúdo
- O que você quer dizer com dados de áudio?
- Aplicativos de processamento de áudio
- Tratamento de dados no domínio de áudio
- Vamos resolver o desafio do UrbanSound!!
- Intermediário: nossa primeira apresentação
- Vamos resolver o desafio! Papel 2: Construindo melhores modelos
- Etapas futuras para explorar
O que você quer dizer com dados de áudio?
Diretamente ou indiretamente, você está sempre em contato com o áudio. Seu cérebro processa e entende continuamente os dados de áudio e fornece informações sobre o ambiente. Um exemplo simples pode ser suas conversas com pessoas que você faz diariamente.. Este discurso é discernido pela outra pessoa para continuar as discussões. Mesmo quando você pensa que está em um ambiente silencioso, tende a captar sons muito mais sutis, como o farfalhar das folhas ou o barulho da chuva. Esta é a extensão da sua conexão com o áudio.
Então, Você pode de alguma forma pegar este áudio flutuando ao seu redor para fazer algo construtivo? sim, claro! Existem dispositivos embutidos que ajudam a captar esses sons e representá-los em um formato legível por computador.. Exemplos desses formatos são
- formato wav (arquivo de áudio de forma de onda)
- formato mp3 (Camada de áudio MPEG-1 3)
- Formato WMA (Áudio do Windows Media)
Se você pensar sobre a aparência de um áudio, não é nada mais do que um formato de dados de forma de onda, onde a amplitude do áudio muda em relação ao tempo. Isso pode ser representado pictoricamente da seguinte forma.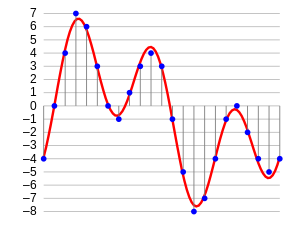
Aplicativos de processamento de áudio
Embora comentemos que os dados de áudio podem ser úteis para a análise. Mas, Quais são as possíveis aplicações do processamento de áudio? Aqui eu listaria alguns deles.
- Indexação de coleções de música com base em suas características de áudio.
- Recomendar música para estações de rádio
- Encontrando semelhanças para arquivos de áudio (também conhecido como Shazam)
- Processamento e síntese de voz: geração de voz artificial para agentes conversacionais
Aqui está um exercício; Você consegue pensar em um aplicativo de processamento de áudio que pode potencialmente ajudar milhares de vidas?
Tratamento de dados no domínio de áudio
Tal como acontece com todos os formatos de dados não estruturados, dados de áudio têm algumas etapas de pré-processamento que devem ser seguidas antes de serem apresentados para análise. Abordaremos isso em detalhes em um artigo posterior., aqui teremos uma visão de por que isso é feito.
A primeira etapa é carregar os dados em um formato compreensível por máquina. Para isto, nós apenas pegamos valores após cada intervalo de tempo específico. Por exemplo; em um arquivo de áudio de 2 segundos, extraímos valores em meio segundo. Se chama amostragem de dados de áudio, e a taxa em que é amostrada é chamada taxa de amostragem.
Outra forma de representar dados de áudio é convertê-los em um domínio de representação de dados diferente, quer dizer, o domínio da frequência. Quando testamos dados de áudio, precisamos de muito mais pontos de dados para representar todos os dados e, O que mais, a frequência de amostragem deve ser a mais alta possível.
Por outro lado, se representarmos dados de áudio em domínio de frequência, muito menos espaço computacional é necessário. Para ter uma intuição, dê uma olhada na foto abaixo.
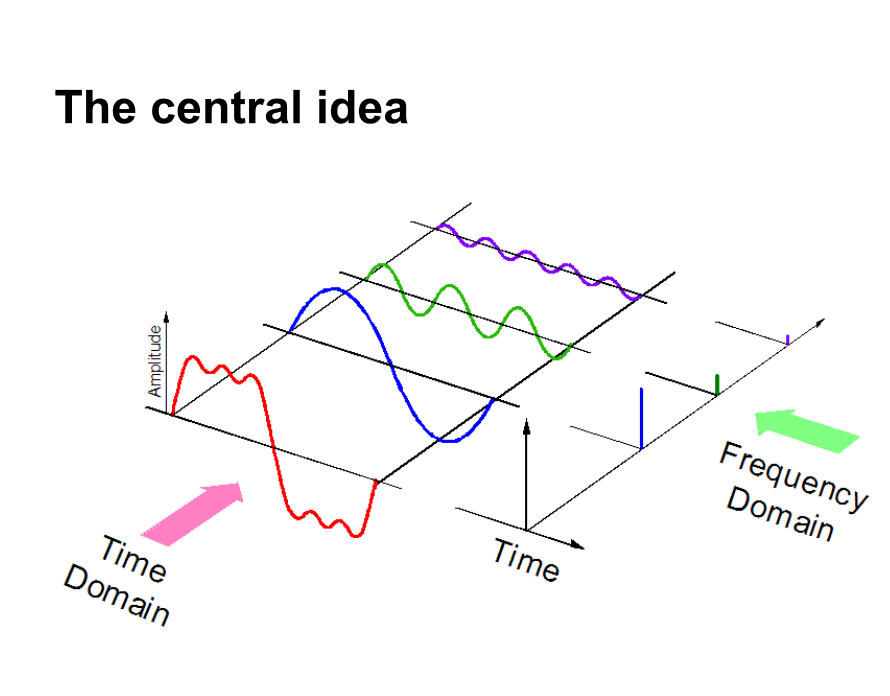
Aqui, separamos um sinal de áudio em 3 diferentes sinais puros, que agora pode ser representado como três valores únicos no domínio da frequência.
Existem mais algumas maneiras de os dados de áudio serem representados, por exemplo. usando MFC (cepstros de freqüência de mel. PD: Abordaremos isso no artigo posterior.). Estas são apenas formas diferentes de representar os dados.
Agora, a próxima etapa é extrair recursos dessas representações de áudio, para que nosso algoritmo possa trabalhar com essas características e realizar a tarefa para a qual foi projetado. A seguir, uma representação visual das categorias de funções de áudio que podem ser extraídas é mostrada.
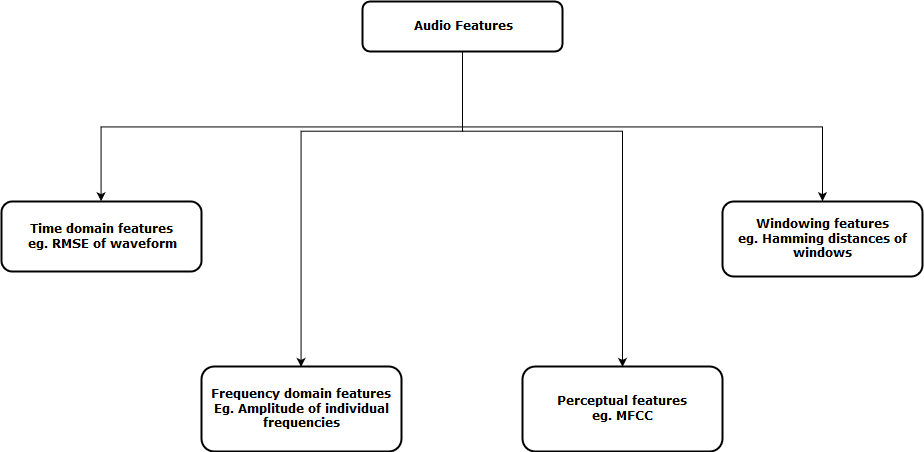
Depois de extrair esses recursos, enviado para o modelo de aprendizado de máquina para análise posterior.
Vamos resolver o desafio do UrbanSound!!
Vamos obter uma visão geral prática melhor de um projeto da vida real, a Desafio de som urbano. Este problema prático destina-se a apresentá-lo ao processamento de áudio no cenário de classificação típico.
O conjunto de dados contém 8732 trechos de som (<= 4 s) de sons urbanos de 10 aulas, a saber:
- ar-condicionado,
- chifre,
- crianças brincando,
- cachorro latindo,
- perfuração,
- Motor ocioso,
- tiro de arma
- martelo pneumatico,
- sereia e
- Street Music
Aqui está um trecho de som do conjunto de dados. Você consegue adivinhar a que classe ela pertence?
Para reproduzir isso no caderno de jupyter, você pode apenas seguir o código.
import IPython.display as ipd
ipd.Audio('../data/Train/2022.wav')
Agora vamos carregar este áudio em nosso laptop como uma grande matriz. Para isso vamos usar livros biblioteca python. Para instalar livros, apenas digite isso na linha de comando
pip install librosaAgora podemos executar o seguinte código para carregar os dados.
dados, sampling_rate = librosa.load('../data/Train/2022.wav')
Quando você carrega os dados, te dá dois objetos; uma grande variedade de um arquivo de áudio e a taxa de amostragem correspondente pela qual foi extraído. Agora, para representar isso como uma forma de onda (que é originalmente), use o seguinte código
% pylab inline importar os importar pandas como pd importar librosa import glob plt.figure(figsize =(12, 4)) librosa.display.waveplot(dados, sr = sampling_rate)
A saída é a seguinte
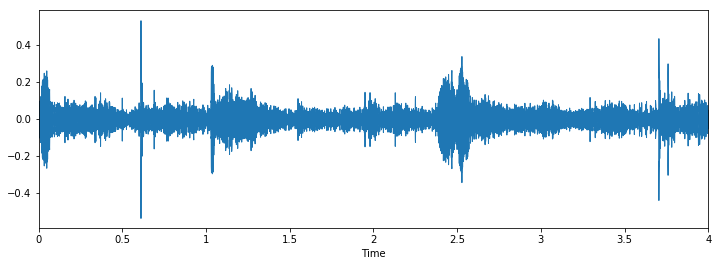
Agora vamos inspecionar visualmente nossos dados e ver se podemos encontrar padrões nos dados..
Classe: britadeiraClasse: perfuração
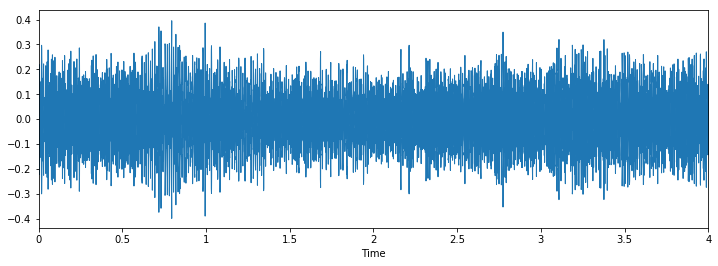 Classe: perfuração
Classe: perfuração
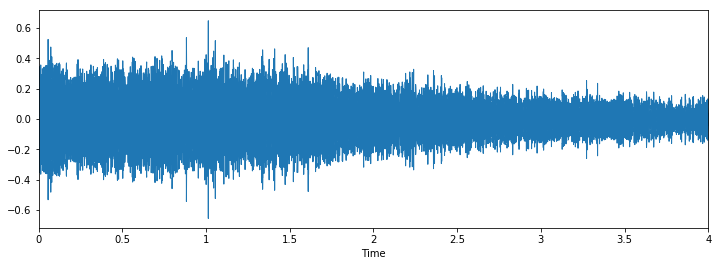 Classe: latido de cachorro
Classe: latido de cachorro
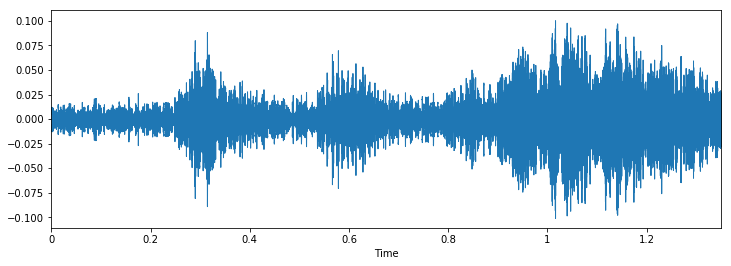
Podemos ver que pode ser difícil diferenciar entre martelo pneumático e perfuração, mas ainda é fácil distinguir entre latido de cachorro e piercing. Para ver mais exemplos deste tipo, você pode usar este código
i = random.choice(train.index)
audio_name = train.ID[eu]
path = os.path.join(data_dir, 'Trem', str(audio_name) + '.wav')
imprimir('Classe: ', treinar.Classe[eu])
x, sr = librosa.load('../data/Train/' + str(train.ID[eu]) + '.wav')
plt.figure(figsize =(12, 4))
librosa.display.waveplot(x, sr = sr)
Intermediário: nossa primeira apresentação
Faremos uma abordagem semelhante à que fizemos para o problema de detecção de idade, para ver as distribuições de classe e apenas prever a ocorrência máxima de todos os casos de teste como essa classe.
Vejamos as distribuições para este problema.
train.Class.value_counts()
Fora[10]: britadeira 0.122907 motor_idling 0.114811 sereia 0.111684 latido de cachorro 0.110396 ar condicionado 0.110396 crianças brincando 0.110396 street_music 0.110396 perfuração 0.110396 car_horn 0.056302 tiro 0.042318
Vemos que a classe do martelo pneumático tem mais valores do que qualquer outra classe. Então, vamos criar nossa primeira apresentação com esta ideia.
test = pd.read_csv('../data/test.csv')
teste['Classe'] = 'britadeira'
test.to_csv(‘Sub01.csv’, index = False)
Parece uma boa ideia como referência para qualquer desafio, mas para este problema, parece um pouco injusto. Isso ocorre porque o conjunto de dados não é muito desequilibrado.
Vamos resolver o desafio! Papel 2: Construindo melhores modelos
Agora vamos ver como podemos tirar proveito dos conceitos que aprendemos antes para resolver o problema.. Seguiremos estas etapas para corrigir o problema.
Paso 1: fazer upload de arquivos de áudio
Paso 2: extrair funções de áudio
Paso 3: converter dados para passar para nosso modelo de aprendizado profundo
Paso 4: Execute um modelo de aprendizado profundo e obtenha resultados
Abaixo está um código de como implementei essas etapas
Paso 1 e 2 combinado: carregar arquivos de áudio e extrair funções
analisador de def(fileira): # function to load files and extract features file_name = os.path.join(os.path.abspath(data_dir), 'Trem', str(row.ID) + '.wav') # handle exception to check if there isn't a file which is corrupted try: # here kaiser_fast is a technique used for faster extraction X, sample_rate = librosa.load(nome do arquivo, res_type ="kaiser_fast") # we extract mfcc feature from data mfccs = np.mean(librosa.feature.mfcc(y = X, sr = sample_rate, n_mfcc = 40).T,eixo = 0) exceto exceção como e: imprimir("Erro encontrado ao analisar o arquivo: ", Arquivo) retorno Nenhum, None feature = mfccs label = row.Class return [recurso, rótulo] temp = train.apply(analisador, eixo = 1) temp.columns = ['recurso', 'rótulo']
Paso 3: converter dados para passar para nosso modelo de aprendizado profundo
de sklearn.preprocessing import LabelEncoder X = np.array(temp.feature.tolist()) y = np.array(temp.label.tolist()) lb = LabelEncoder() y = np_utils.to_categorical(lb.fit_transform(e))
Paso 4: Execute um modelo de aprendizado profundo e obtenha resultados
importar numpy como np
de keras.models import Sequential
de keras.layers import Dense, Cair fora, Ativação, Achatar
de keras.layers import Convolution2D, MaxPooling2D
de keras.optimizers import Adam
de keras.utils import np_utils
de métricas de importação sklearn
num_labels = y.shape[1]
filter_size = 2
# construir modelo
modelo = Sequencial()
model.add(Denso(256, input_shape =(40,)))
model.add(Ativação('relu'))
model.add(Cair fora(0.5))
model.add(Denso(256))
model.add(Ativação('relu'))
model.add(Cair fora(0.5))
model.add(Denso(num_labels))
model.add(Ativação('softmax'))
model.compile(perda ="categorical_crossentropy", metrics =['precisão'], otimizador ="Adão")
Agora vamos treinar nosso modelo
model.fit(X, e, batch_size = 32, épocas = 5, validação_data =(val_x, val_y))
Este é o resultado que obtive de treinamento durante 5 épocas
Treine em 5435 amostras, validar em 1359 amostras Época 1/10 5435/5435 [================================] - 2s - perda: 12.0145 - acc: 0.1799 - val_loss: 8.3553 - val_acc: 0.2958 Época 2/10 5435/5435 [================================] - 0s - perda: 7.6847 - acc: 0.2925 - val_loss: 2.1265 - val_acc: 0.5026 Época 3/10 5435/5435 [================================] - 0s - perda: 2.5338 - acc: 0.3553 - val_loss: 1.7296 - val_acc: 0.5033 Época 4/10 5435/5435 [================================] - 0s - perda: 1.8101 - acc: 0.4039 - val_loss: 1.4127 - val_acc: 0.6144 Época 5/10 5435/5435 [================================] - 0s - perda: 1.5522 - acc: 0.4822 - val_loss: 1.2489 - val_acc: 0.6637
Parece estar bem, mas obviamente você pode aumentar a pontuação. (PD: poderia obter precisão de 80% no meu conjunto de dados de validação). Agora é a sua vez, Você pode aumentar essa pontuação? Sim é assim, Deixe-me saber nos comentários abaixo!!
Etapas futuras para explorar
Agora que vimos aplicativos simples, podemos sugerir mais alguns métodos que podem nos ajudar a melhorar nossa pontuação.
- Aplicamos um modelo de rede neural simples ao problema. Nosso próximo passo imediato deve ser entender onde o modelo falha e por que. Com isto, queremos conceituar nossa compreensão das falhas de algoritmo para que da próxima vez que construirmos um modelo, não cometa os mesmos erros.
- Nós podemos construir modelos mais eficientes que nosso “melhores modelos”, como redes neurais convolucionais ou redes neurais recorrentes. Esses modelos têm mostrado resolver esses tipos de problemas mais facilmente.
- Tocamos no conceito de aumento de dados, mas não os aplicamos aqui. Você pode tentar para ver se funciona para o problema.
Notas finais
Neste artigo, Eu forneci uma breve visão geral do processamento de áudio com um estudo de caso sobre o desafio UrbanSound. Também mostrei as etapas que você executa ao lidar com dados de áudio em python com os livros do pacote. Com este “shastra” na sua mão, espero que você possa testar seus próprios algoritmos no desafio Urban Sound, ou tente resolver seus próprios problemas de áudio na vida diária. Se você tem alguma sugestão / ideia, Deixe-me saber nos comentários abaixo.
Aprender, envolver , Picar e ser contratado!

Podcast: Jogue em uma nova janela | Descargar





