Observação: esta postagem foi publicada originalmente em 13 setembro 2015 e atualizou o 11 setembro 2017
Visão geral
- Entenda um dos algoritmos de classificação de aprendizado de máquina mais populares e simples, o algoritmo Naive Bayes
- É baseado no teorema de Bayes para calcular probabilidades e probabilidades condicionais.
- Aprenda como implementar o classificador Naive Bayes em R e Python
Introdução
Aqui está uma situação em que você se meteu Ciência de dados esboço, projeto:
Você está trabalhando em um obstáculo de classificação e gerou seu conjunto de hipóteses, criou características e discutiu a relevância das variáveis. Em uma hora, as partes interessadas querem ver o primeiro corte do modelo.
O que vai fazer? Você tem centenas de centenas de pontos de dados e algumas variáveis em seu conjunto de dados TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina..... Em tal situação, se eu estivesse em seu lugar, teria usado ‘Bayes ingenuo‘, o que pode ser extremamente rápido em se relacionar com outras pessoas algoritmos de classificação. Trabalha com o teorema da probabilidade de Bayes para prever a classe de conjuntos de dados desconhecidos.
Neste post, Vou explicar o básico deste algoritmo, então, da próxima vez que você encontrar grandes conjuntos de dados, pode colocar este algoritmo em ação. Ao mesmo tempo, se você é um novato em Python o R, você não deve ficar confuso com a presença de códigos disponíveis nesta postagem.
Se você preferir aprender o teorema Naive Bayes desde o básico até a implementação de uma forma estruturada, você pode se inscrever neste curso gratuitamente:
Você é um iniciante em aprendizado de máquina?? Você pretende dominar algoritmos de aprendizado de máquina como Naive Bayes? Aqui está um curso abrangente que abrange algoritmos de aprendizado de máquina e aprendizado de máquina. aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde... em detalhe:
Projeto para aplicação de Naive BayesExposição do problemaA análise de RH está revolucionando a forma como os departamentos de RH operam, levando a maior eficiência e melhores resultados gerais. Os recursos humanos têm vindo a utilizar a analíticaAnalytics refere-se ao processo de coleta, Meça e analise dados para obter insights valiosos que facilitam a tomada de decisões. Em vários campos, como negócio, Saúde e esporte, A análise pode identificar padrões e tendências, Otimize processos e melhore resultados. O uso de ferramentas avançadas e técnicas estatísticas é essencial para transformar dados em conhecimento aplicável e estratégico.... durante anos. Apesar disto, a compilação, processamento e análise de dados tem sido amplamente mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... manual e, Dada a natureza da dinâmica de recursos humanos e KPIsKPIs, o Indicadores-chave de desempenho, Essas são métricas usadas pelas organizações para avaliar seu sucesso em atingir metas específicas. Esses indicadores permitem monitorar o progresso e tomar decisões informadas. Existem diferentes tipos de KPIs, que podem variar dependendo do setor e dos objetivos estratégicos da empresa. Sua correta implementação é essencial para melhorar a eficiência e eficácia das operações.... Recursos humanos, o foco tem se restringido aos recursos humanos. Por isso, é surpreendente que seus departamentos tenham percebido a utilidade do aprendizado de máquina tão tarde no jogo. Esta é uma possibilidade de testar análises preditivas para identificar os trabalhadores com maior probabilidade de serem promovidos. |
Tabela de conteúdo
- O que é o algoritmo Naive Bayes?
- Como funcionam os algoritmos Naive Bayes?
- Quais são os prós e contras de usar Naive Bayes?
- 4 Aplicativos de algoritmo Naive Bayes
- Etapas para construir um modelo básico Naive Bayes em Python
- Dicas para aumentar o poder do modelo Naive Bayes
O que é o algoritmo Naive Bayes?
É um técnica de classificação com base no teorema de Bayes com uma suposição de independência entre preditores. Em termos simples, um classificador Naive Bayes assume que a presença de um determinado recurso em uma classe não está relacionada à presença de qualquer outro recurso.
Como um exemplo, uma fruta pode ser considerada uma maçã se for vermelha, redondo e tem aproximadamente 3 polegadas de diâmetro. Mesmo que essas características dependam umas das outras ou da existência de outras características, Todas essas propriedades contribuem de forma independente para a probabilidade de que esta fruta seja uma maçã e é por isso que é conhecida como ‘Ingênua’.
O modelo Naive Bayes é fácil de construir e particularmente útil para conjuntos de dados muito grandes.. Junto com a simplicidade, Naive Bayes são conhecidos por superar até métodos de classificação altamente sofisticados.
O teorema de Bayes fornece uma maneira de calcular a probabilidade posterior P (c | x) a partir de P (c), P (x) y P (x | c). Olhe para a próxima equação:
 Acima de,
Acima de,
- PAG(c | x) é a probabilidade posterior de classe (C, objetivo) dados preditor (X, atributos).
- PAG(C) é a probabilidade anterior de classe.
- PAG(x | c) é a probabilidade que é a probabilidade de preditor dados classe.
- PAG(X) é a probabilidade anterior de preditor.
Como funciona o algoritmo Naive Bayes?
Vamos entender com um exemplo. Abaixo, tenho um conjunto de dados de treinamento do clima e do variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... respectivo objetivo 'Brincar’ (sugerindo possibilidades de jogo). Agora, devemos categorizar se os jogadores vão jogar ou não de acordo com as condições meteorológicas. Vamos seguir os passos abaixo para fazer isso.
Paso 1: converter o conjunto de dados em uma tabela de frequência
Paso 2: Crie uma tabela de probabilidade encontrando as probabilidades como a probabilidade de Nublado = 0.29 e a probabilidade de jogar é 0.64.
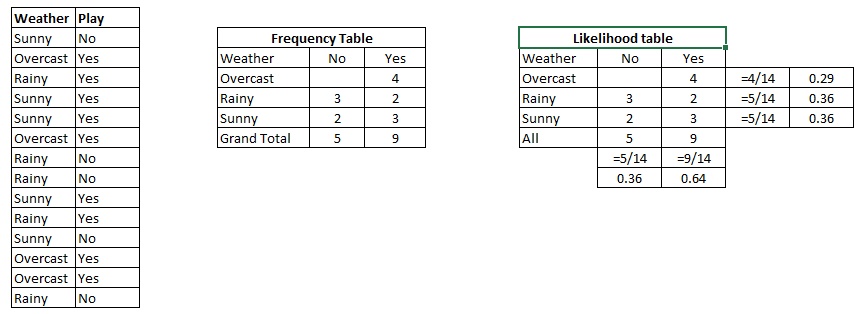
Paso 3: agora, usa Ingenuo Bayesiano equação para calcular a probabilidade posterior para cada classe. A classe com a maior probabilidade posterior é o resultado do prognóstico.
Problema: Os jogadores vão jogar se o tempo estiver ensolarado. Esta afirmação está correta??
Podemos resolvê-lo usando o método de probabilidade posterior discutido anteriormente.
P (sim | Ensolarado) = P (Ensolarado | sim) * P (sim) / P (Ensolarado)
Aqui temos P (Ensolarado | sim) = 3/9 = 0.33, P (Ensolarado) = 5/14 = 0.36, P (sim) = 9/14 = 0.64
Agora, P (sim | Ensolarado) = 0.33 * 0.64 / 0.36 = 0.60, o que é mais provável.
Naive Bayes usa um método equivalente para prever a probabilidade de diferentes classes com base em vários atributos. Este algoritmo é usado principalmente na classificação de textos e com problemas que possuem várias classes.
Quais são os prós e contras do Naive Bayes?
Prós:
- É fácil e rápido prever o tipo de conjunto de dados de teste. Também funciona bem em previsões multiclasse.
- Quando o pressuposto de independência é cumprido, um classificador Naive Bayes tem um desempenho melhor em comparação com outros modelos, como regressão logística e requer menos dados de treinamento.
- Funciona bem para variáveis de entrada categóricas em comparação com variáveis numéricas. Para a variável numérica, uma distribuição normal é assumida (curva de sino, que é uma suposição sólida).
Contras:
- Se a variável categórica tem uma categoria (no conjunto de dados de teste), que não foi observado no conjunto de dados de treinamento, então o modelo irá atribuir uma probabilidade 0 (zero) e não será capaz de fazer uma previsão. Isso é frequentemente referido como “Freqüência zero”. Para consertar isso, podemos usar a técnica de suavização. Uma das técnicas de suavização mais simples é chamada de estimativa de Laplace.
- Por outro lado, Naïve Bayes também é conhecido como um mal Estimadoro "Estimador" é uma ferramenta estatística usada para inferir características de uma população a partir de uma amostra. Ele se baseia em métodos matemáticos para fornecer estimativas precisas e confiáveis. Existem diferentes tipos de estimadores, como o imparcial e o consistente, escolhidos de acordo com o contexto e objetivo do estudo. Seu uso correto é essencial na pesquisa científica, levantamentos e análise de dados...., então, as saídas de probabilidade de Predict_test não deve ser levado muito a sério.
- Outra limitação de Bayes ingenuo é a suposição de preditores independentes. Na vida real, é quase impossível para nós obter um conjunto de preditores totalmente independentes.
4 Aplicações de algoritmos ingênuos de Bayes
- Previsão em tempo real: Naive Bayes é um classificador de aprendizagem ávido e seguro que é rápido. Por tanto, pode ser usado para fazer previsões em tempo real.
- Predição de múltiplas classes: Este algoritmo também é conhecido por sua função de previsão de múltiplas classes.. Aqui podemos prever a probabilidade de várias classes de variável de destino.
- Classificação de texto / filtragem de spam / análise de sentimentos: Classificadores Naive Bayes usados principalmente na classificação de texto (devido a um melhor resultado em problemas de múltiplas classes e a regra de independência) têm uma maior taxa de sucesso em comparação com outros algoritmos. Como consequência, amplamente utilizado na filtragem de spam (identificar e-mail de spam) e análise de sentimento (em análise de mídia social, para identificar os sentimentos positivos e negativos dos clientes).
- Sistema de recomendação: Classificador Naive Bayes e Filtragem colaborativa Juntos, eles constroem um sistema de recomendação que usa técnicas de aprendizado de máquina e mineração de dados para filtrar informações invisíveis e prever se um usuário deseja um determinado recurso ou não
Como construir um modelo básico usando Naive Bayes em Python e R?
Novamente, scikit aprender (Biblioteca Python) ajudará aqui a construir um modelo Naive Bayes em Python. Existem três tipos de modelo Naive Bayes na biblioteca scikit-learn:
-
Gaussiano: É usado na classificação e assume que as características seguem uma distribuição normal.
-
Multinomial: Usado para contagens discretas. Como um exemplo, digamos que temos um obstáculo de classificação de texto. Aqui podemos considerar os ensaios de Bernoulli, que é um passo adiante e em vez de “palavra que aparece no documento”, tenho “contar com que frequência a palavra aparece no documento”, você pode pensar nisso como “número de vezes que o resultado é observado número x_i durante os testes n ".
-
Bernoulli: O modelo binômio é útil se seus vetores de características forem binários (Em outras palavras, zeros e uns). Uma aplicação seria a classificação de texto com o modelo 'word bag'’ onde o 1 e 0 filho “a palavra aparece no documento” e “a palavra não aparece no documento”, respectivamente.
Código Python:
Experimente o seguinte código na janela de codificação e verifique seus resultados na hora!
Código R:
Requer(e1071) #Holds the Naive Bayes Classifier Train <- read.csv(arquivo.escolha()) Teste <- read.csv(arquivo.escolha()) #Make sure the target variable is of a two-class classification problem only levels(Trem $Item_Fat_Content) modelo <- IngenuosBayes(Item_Fat_Content ~., data = Train) classe(modelo) pred <- prever(modelo,Teste) tabela(pred)
Anteriormente, analisamos o modelo básico Naive Bayes, Você pode melhorar o poder deste modelo básico ajustando o parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... e lidar com suposições com sabedoria. Vamos ver os métodos para impulsionar o desempenho do modelo Naive Bayes. Eu sugiro que você vá até este documento para obter mais detalhes sobre a classificação de texto usando Naive Bayes.
Dicas para aumentar o poder do modelo Naive Bayes
A seguir, Aqui estão algumas dicas para aumentar a potência de Bayes ingenuo Modelo:
- Se as entidades contínuas não tiverem distribuição normal, devemos usar transformação ou métodos diferentes para convertê-los para distribuição normal.
- Se o conjunto de dados de teste tiver um obstáculo de frequência zero, aplicar técnicas de suavização de "correção de Laplace" para prever a classe do conjunto de dados de teste.
- Remover recursos correlacionados, uma vez que características altamente correlacionadas são votadas duas vezes no modelo e podem levar a relevância exagerada.
- Os classificadores Naive Bayes têm opções limitadas para definir parâmetros como alfa = 1 para suavizar, fit_prior =[Verdade|Falso] para aprender as probabilidades anteriores da classe ou não e algumas outras opções (Veja detalhes aqui). Eu recomendaria focar no pré-processamento de dados e seleção de recursos.
- Você poderia pensar em aplicar algum técnica de combinação de classificador como definir, ensacamento e reforço, mas esses métodos não ajudariam. Na realidade, “Junte, impulsionar, embolsar” não vai ajudar, já que seu objetivo é reduzir a variação. Naive Bayes não tem variação para minimizar.
Notas finais
Neste post, analisamos um dos algoritmos de aprendizado de máquina supervisionado”Baías ingénuas” que é usado principalmente para classificar. Parabéns, se você entendeu esta postagem corretamente, você já deu o primeiro passo para dominar este algoritmo. A partir daqui, tudo que você precisa é prática.
Ao mesmo tempo, Eu sugiro que você se concentre mais no pré-processamento de dados e na seleção de recursos antes de aplicar o algoritmo Naive Bayes.0 Em uma postagem futura, Vou falar sobre como classificar textos e documentos usando bayes ingênuos com mais detalhes.
Esta postagem foi útil para você?? Compartilhe suas opiniões / pensamentos na seção de comentários abaixo.
Você pode usar o seguinte recurso sem nenhum custo para aprender- Baías ingénuas-





