Considere o seguinte fato:
O Facebook atualmente tem mais de um bilhão de usuários ativos todos os meses
Vamos pensar por alguns segundos sobre quais informações o Facebook geralmente armazena sobre seus usuários. Parte disso é:
- Dados demográficos básicos (como um exemplo, data de nascimento, sexo, Localização atual, localização anterior, Universidade)
- Atividade do usuário e contrato de atualização (suas fotos, comentários, eu gosto, aplicativos que você usou, jogos que você jogou, Postagens, chats, etc.)
- Sua rede social (seus amigos, seus círculos, Como vocês são relacionados, etc.)
- Interesses do usuário (Leia livros, filmes vistos, locais, etc.)

Usando esta e muitas outras informações (como um exemplo, o que um usuário clicou, o que você leu e quanto tempo você gastou nisso), O Facebook faz o seguinte em tempo real:
- Recomende pessoas que você conhece e conexões mútuas com elas.
- Use suas atividades atuais e passadas para entender o que lhe interessa
- Entre em contato com você com atualizações, atividades e anúncios que podem lhe interessar mais.
Ao mesmo tempo desses, há atividades de fechamento (atualizado em lotes e não em tempo real) como o número de pessoas que falam sobre uma página, pessoas alcançadas em uma semana.
Agora, imagine o tipo de infraestrutura de dados necessária para executar o Facebook, o tamanho do seu data center, o poder de processamento necessário para atender aos requisitos do usuário. A magnitude pode ser emocionante ou assustadora, dependendo de como você olha para isso.
O próximo infográfico da IBM destaca a magnitude dos requisitos / processamento de dados para algumas instituições semelhantes:

Esse tipo de porte e escala não era ouvido por nenhum analista até alguns anos atrás e a infraestrutura de dados em que algumas dessas instituições haviam investido não estava preparada para lidar com essa escala.. Isso geralmente é chamado de problema de Big Data..
Então, O que é big data?
Big data são dados muito grandes, complexo e dinâmico para qualquer ferramenta de dados convencional para capturar, armazenar, gerenciar e analisar. Ferramentas tradicionais foram projetadas com escala em mente. Como um exemplo, quando uma organização gostaria de investir em uma solução de Business Intelligence, parceiro de implementação viria, estudar os requisitos de negócios e, em seguida, criar uma solução para atender a esses requisitos.
Se o requisito para esta organização aumentar com o tempo ou se você quiser executar uma análise mais granular, teve que reinvestir em infraestrutura de dados. O custo dos recursos envolvidos na ampliação dos recursos que são usados regularmente para aumentar exponencialmente. Ao mesmo tempo, haveria uma limitação no tamanho para o qual ele poderia escalar (como um exemplo, tamanho da máquina, CPU, RAM, etc.). Esses sistemas tradicionais não podiam suportar a escala exigida por algumas das empresas de Internet..
Como o big data é diferente dos dados tradicionais?
Felizmente ou infelizmente, não há limite de tamanho / paramétrico para escolher se os dados são “big data” ou não. Big data é normalmente caracterizado com base no que é popularmente conhecido como 3 Vs:
- Volume – Na atualidade, existem instituições que produzem terabytes de dados em um dia. Com dados crescentes, você precisará deixar alguns dados não analisados, se você quiser usar ferramentas tradicionais. UMA mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que el tamaño de los datos aumente aún más, vai deixar mais e mais dados não analisados. Isso significa deixar valor na mesa. Ele contém todas as informações sobre o que o cliente está fazendo e dizendo, Mas não consigo entender! – um sinal claro de que você está lidando com dados maiores do que o seu sistema suporta.
- Variedade – Embora o volume seja apenas o começo, variedade é o que torna as ferramentas tradicionais muito difíceis. As ferramentas tradicionais funcionam melhor com dados estruturados. Exigir que os dados tenham uma estrutura e formato específicos para fazer sentido. Apesar disto, a enxurrada de dados de e-mails, feedback do cliente, fóruns de mídia social, a jornada do cliente no portal da web e call centers não são estruturados por natureza ou, no melhor dos casos, eles são semi-estruturados.
- Velocidade – A taxa na qual os dados são gerados é tão crítica quanto os outros dois fatores. A velocidade com que uma empresa pode analisar os dados acabaria por se tornar uma vantagem competitiva para ela.. É sua velocidade de análise que permite ao Google prever a localização de pacientes com gripe quase em tempo real. Por isso, se você não pode analisar dados em uma velocidade mais rápida do que seu fluxo de entrada, você pode precisar de uma solução de Big Data.
Individualmente, cada um desses Vs ainda pode ser corrigido com a ajuda de soluções tradicionais. Como um exemplo, se a maioria de seus dados for estruturada, você ainda pode obter de 80% al 90% de valor comercial por meio de ferramentas tradicionais. Apesar disto, se você enfrentar um desafio com os três Vs, você saberá que é sobre “big data”.

Quando você precisa de uma solução de Big Data?
Apesar de 3 V dirá se você está lidando com "big data" ou não, se você precisa ou não de uma solução de Big Data, dependendo de suas necessidades. Abaixo estão os cenários em que as soluções de big data são inerentemente mais adequadas:
- Quando se trata de big data semiestruturados ou não estruturados de várias fontes
- Você precisa analisar todos os seus dados e não pode trabalhar com amostragem deles.
- O procedimento é iterativo por natureza (como um exemplo, pesquisas no mecanismo de pesquisa do Google, pesquisar gráficos no Facebook)
Como funciona a resposta de Big Data?
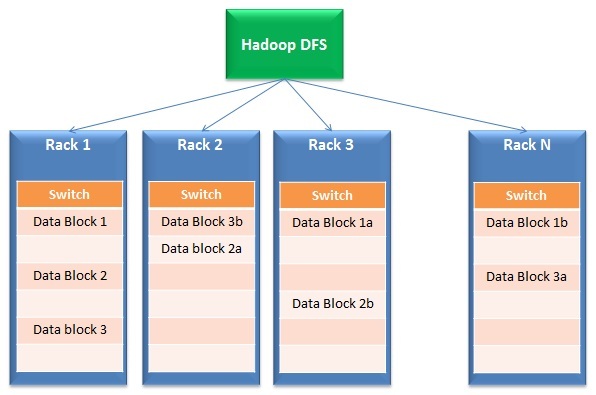
Embora as limitações das soluções tradicionais sejam claras, Como as soluções de big data os resolvem? As soluções de Big Data operam em uma arquitetura fundamentalmente diferente que se baseia nas seguintes características (ilustrativo abaixo):
- Distribuição de dados e processamento paralelo: As soluções de big data funcionam em armazenamento distribuído e processamento paralelo. Resumidamente, os arquivos são divididos em vários pequenos blocos e armazenados em unidades diferentes (chamadas bastidores). Depois de, o processamento ocorre em paralelo nestes blocos e os resultados são mesclados novamente. A primeira parte da operação é normalmente chamada Sistema de arquivos distribuídoUm sistema de arquivos distribuído (DFS) Permite armazenamento e acesso a dados em vários servidores, facilitando o gerenciamento de grandes volumes de informações. Esse tipo de sistema melhora a disponibilidade e a redundância, à medida que os arquivos são replicados para locais diferentes, Reduzindo o risco de perda de dados. O que mais, Permite que os usuários acessem arquivos de diferentes plataformas e dispositivos, promovendo colaboração e... (DFS) enquanto a segunda parte é chamada Mapa pequeno.
- Tolerância ao fracasso: Pela natureza de seu design, resposta de big data tem redundância embutida. Como um exemplo, Hadoop cria 3 cópias de cada bloco de dados em pelo menos 2 prateleiras. Por isso, mesmo se um rack completo falhar ou não estiver habilitado, a resposta ainda funciona. Por que é incorporado? Esse recurso permite que as soluções de big data sejam dimensionadas até mesmo para hardware básico de baixo custo, em vez de dispendiosos discos SAN..
- Escalabilidade e flexibilidade: Esta é a gênese do paradigma completo das soluções de big data. Puede agregar o quitar racks fácilmente del cachoUm cluster é um conjunto de empresas e organizações interconectadas que operam no mesmo setor ou área geográfica, e que colaboram para melhorar sua competitividade. Esses agrupamentos permitem o compartilhamento de recursos, Conhecimentos e tecnologias, Promover a inovação e o crescimento económico. Os clusters podem abranger uma variedade de setores, Da tecnologia à agricultura, e são fundamentais para o desenvolvimento regional e a criação de empregos.... sin preocuparse por el tamaño para el que se diseñó esta solución.
- Eficácia de custos: Devido ao uso de hardware básico, o custo de criação desta infraestrutura é muito menor do que comprar servidores caros com discos resistentes a falhas (como um exemplo, SAN)
Em resumo, E se tudo isso estivesse na nuvem?
Embora o desenvolvimento de uma arquitetura de big data seja lucrativo, encontrar os recursos certos é difícil, o que aumenta o custo de implementação.
Imagine uma situação em que um provedor de serviços em nuvem também cuida de todas as suas questões de TI / a infraestrutura. Você se concentra em conduzir análises e entregar resultados para a empresa, em vez de organizar os racks e se preocupar com o escopo de seu uso.
Tudo que você precisa fazer é pagar de acordo com o seu uso. Na atualidade, soluções ponta a ponta estão disponíveis no mercado, onde você não pode apenas armazenar seus dados na nuvem, mas também consultá-los e analisá-los na nuvem. Você pode consultar terabytes de dados em segundos e deixar todas as preocupações sobre essa infraestrutura para outra pessoa!!
Embora eu tenha fornecido uma visão geral das soluções de Big Data, isso de forma alguma cobre todo o espectro. O objetivo é iniciar a jornada e se preparar para a revolução que está ocorrendo..





