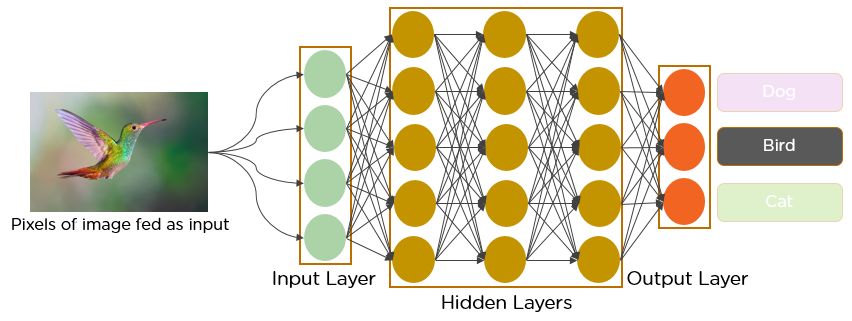
Introdução
Nas últimas décadas, O Deep Learning provou ser uma ferramenta muito poderosa devido à sua capacidade de lidar com grandes quantidades de dados. O interesse em usar camadas ocultas excedeu as técnicas tradicionais, especialmente no reconhecimento de padrões. Uma das redes neurais profundas mais populares são as redes neurais convolucionais.
Desde a década de 1950, os primeiros dias da IA, pesquisadores têm lutado para criar um sistema que possa entender dados visuais. Nos anos seguintes, este campo ficou conhecido como Visão Computacional. Sobre 2012, a visão computacional deu um salto quântico quando um grupo de pesquisadores da Universidade de Toronto desenvolveu um modelo de inteligência artificial que superou os melhores algoritmos de reconhecimento de imagem e que também por uma larga margem.
O sistema de inteligência artificial, que ficou conhecido como AlexNet (com o nome de seu principal criador, Alex Krizhevsky), venceu o concurso de visão computacional ImageNet de 2012 com surpreendente precisão de 85 por cento. O vice-campeão ganhou uma modesta 74 por cento no teste.
No coração do AlexNet estavam as redes neurais convolucionais, um tipo especial de rede neural que imita aproximadamente a visão humana. Ao passar dos anos, CNNs se tornaram uma parte muito importante de muitos aplicativos de visão computacional e, portanto, em uma parte de qualquer curso de visão computacional em linha. Então, vamos dar uma olhada em como funciona a CNN.
Histórico da CNN
As CNNs foram desenvolvidas e usadas pela primeira vez por volta da década de 1980. O máximo que uma CNN podia fazer na época era reconhecer dígitos manuscritos. Era usado principalmente nos setores postais para ler códigos postais, códigos pin, etc. O importante a lembrar sobre qualquer modelo de aprendizado profundo é que ele requer uma grande quantidade de dados para treinar e também requer uma grande quantidade de recursos de computação.. Este foi um grande inconveniente para a CNN naquele período e, portanto, As CNNs eram limitadas apenas aos setores postais e não podiam entrar no mundo do aprendizado de máquina.
Sobre 2012, Alex Krizhevsky percebeu que havia chegado a hora de recuperar o ramo do aprendizado profundo que usa redes neurais multicamadas. A disponibilidade de grandes conjuntos de dados, para serem conjuntos de dados ImageNet mais específicos com milhões de imagens marcadas e uma abundância de recursos de computação, permitiu que pesquisadores revivessem a CNN.
O que exatamente é uma CNN?
Sobre aprendizado profundo, uma convolucional neuronal vermelho (CNN / ConvNet) é um tipo de redes neurais profundas, mais comumente aplicado para analisar imagens visuais. Agora, quando pensamos em uma rede neural, nós pensamos em multiplicações de matrizes, mas esse não é o caso com ConvNet. Usa uma técnica especial chamada convolução. Agora em matemática convolução é uma operação matemática em duas funções que produz uma terceira função que expressa como a forma de uma é modificada pela outra.
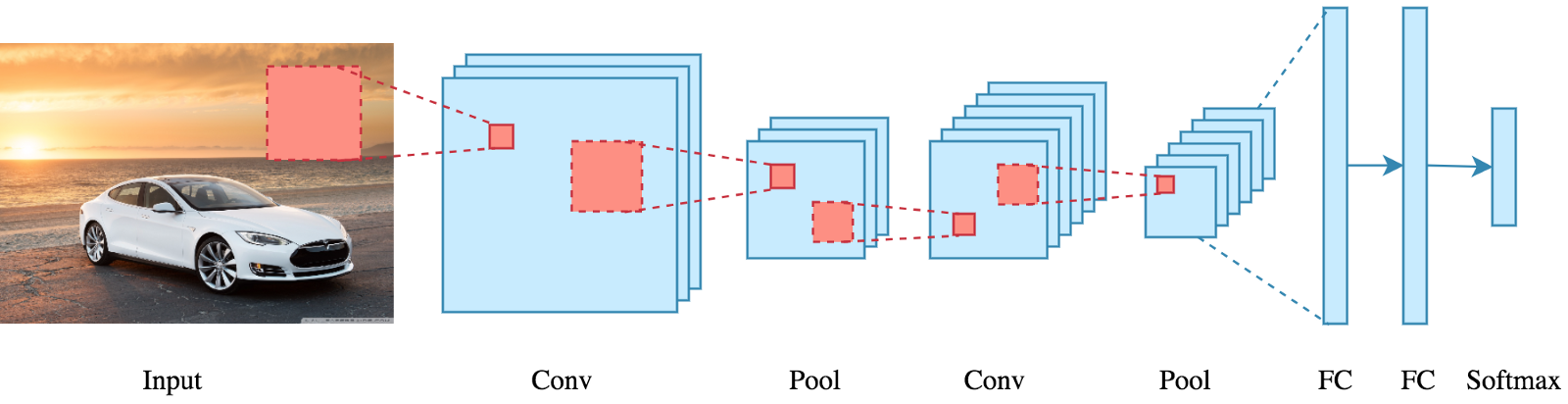
Mas realmente não precisamos ir além da parte matemática para entender o que é uma CNN ou como funciona..
O resultado final é que a função da ConvNet é reduza as imagens a uma forma que seja mais fácil de processar, sem perder características que são fundamentais para obter uma boa previsão.
Como funciona?
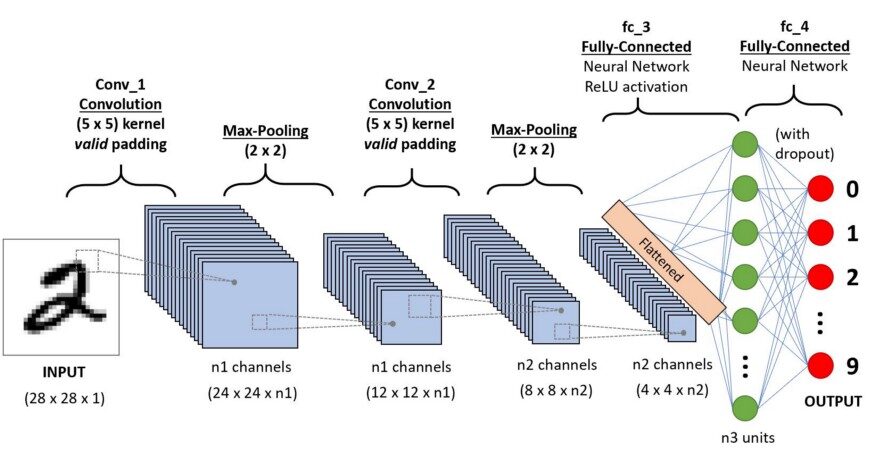
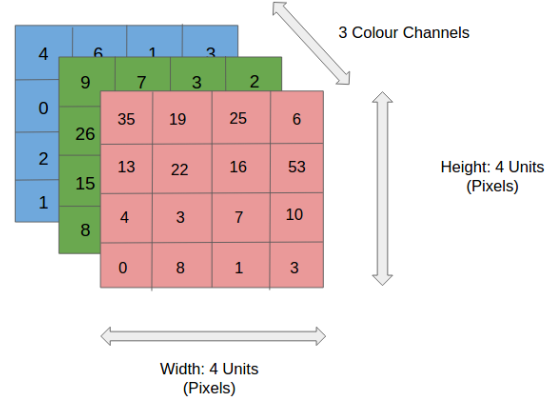
Antes de ir para a operação CNN, vamos cobrir o básico, como o que é uma imagem e como ela é representada. Uma imagem RGB nada mais é do que uma matriz de valores de pixel que possui três planos, enquanto uma imagem em tons de cinza é a mesma, mas tem apenas um plano. Dê uma olhada nesta imagem para entender mais.
Para simplificar, vamos prosseguir com as imagens em tons de cinza enquanto tentamos entender como funciona a CNN.
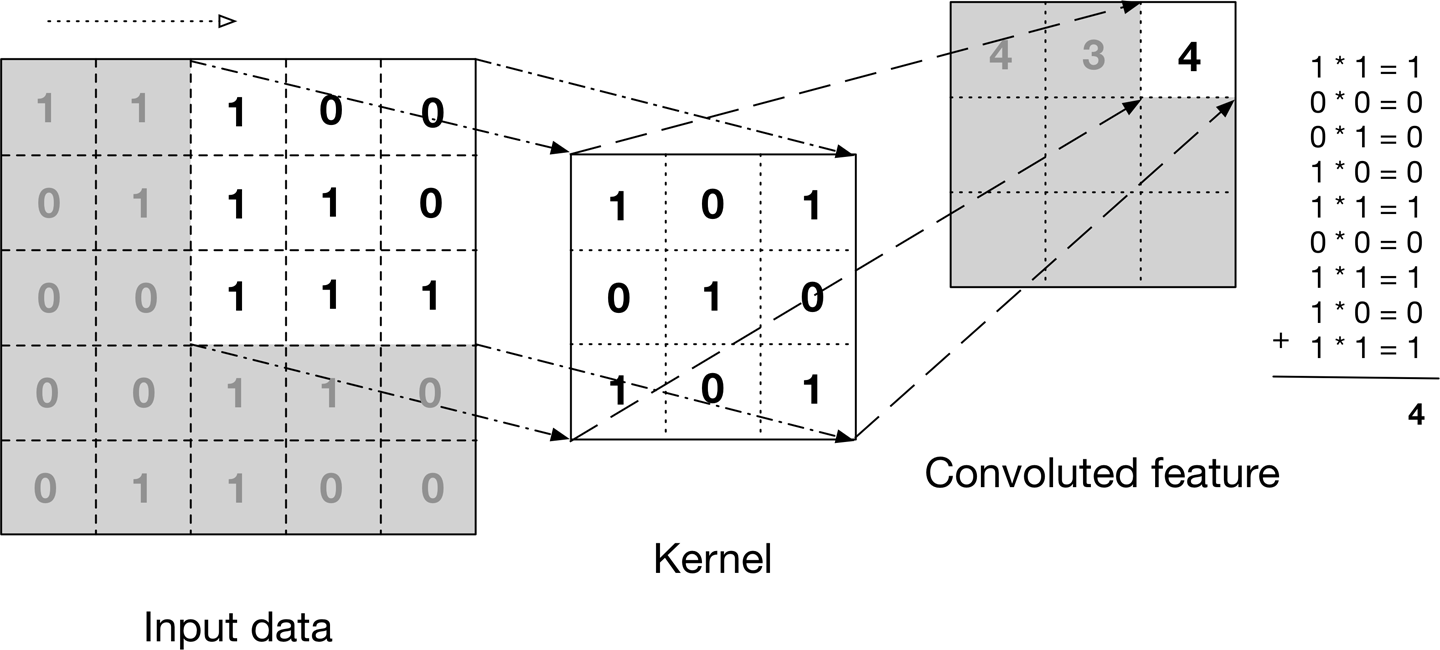
A imagem acima mostra o que é uma convolução. Nós pegamos um filtro / núcleo (matriz de 3 × 3) e o aplicamos à imagem de entrada para obter a função convolvida. Este recurso convolvido é passado para a próxima camada.
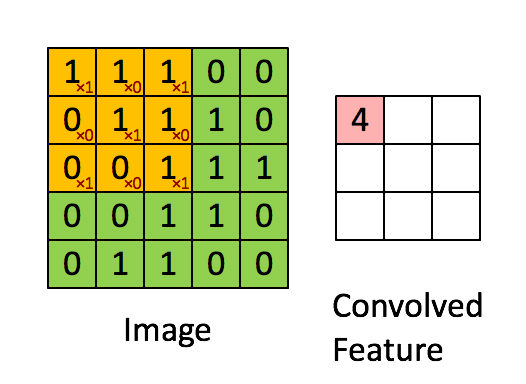
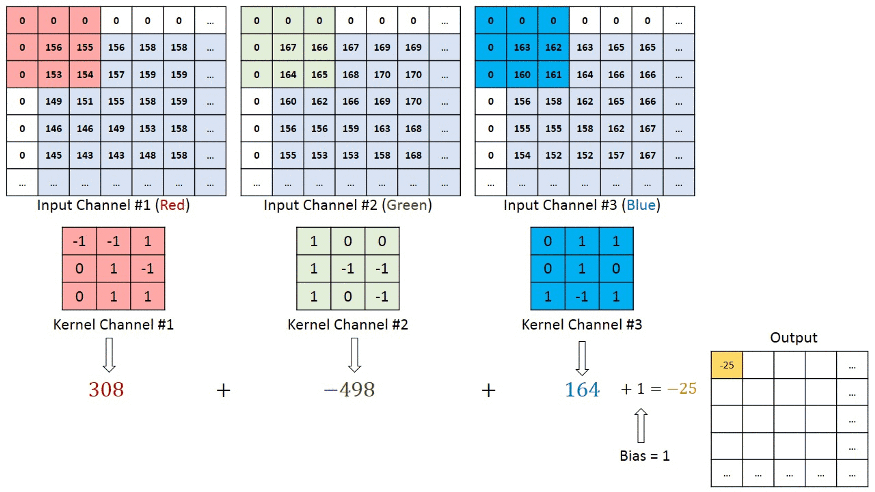
No caso da cor RGB, o canal dê uma olhada nesta animação para entender como funciona.
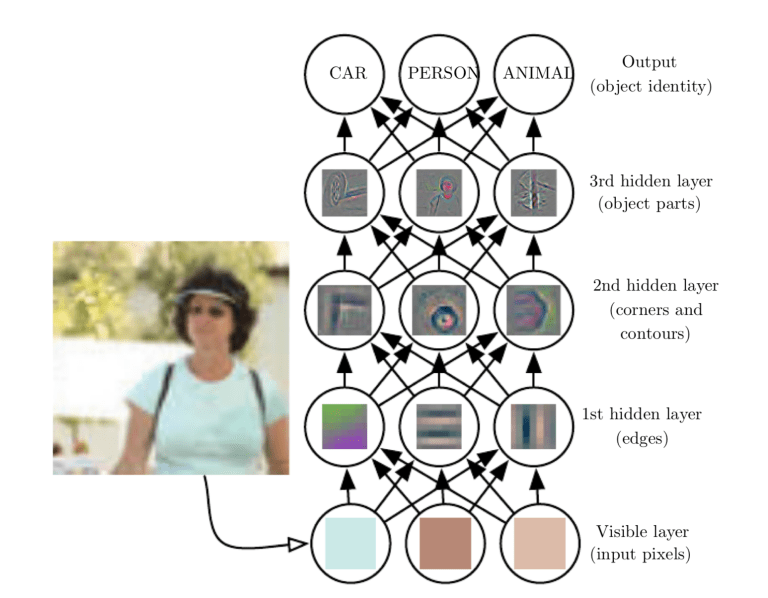
As redes neurais convolucionais são compostas por várias camadas de neurônios artificiais. Neurônios artificiais, uma imitação aproximada de suas contrapartes biológicas, são funções matemáticas que calculam a soma ponderada de várias entradas e saídas de um valor de disparo. Quando você insere uma imagem em um ConvNet, cada camada gera várias funções de ativação que são passadas para a próxima camada.
A primeira camada geralmente extrai recursos básicos como bordas horizontais ou diagonais. Esta saída é passada para a próxima camada, que detecta recursos mais complexos, como cantos ou arestas combinatórias. Conforme entramos na web, podemos identificar recursos ainda mais complexos, como objetos, rostos, etc.

De acordo com o mapa de ativação da camada de convolução final, a camada de classificação gera um conjunto de pontuações de confiança (valores entre 0 e 1) que especificam a probabilidade de a imagem pertencer a um “classe”. Por exemplo, se você tiver um ConvNet que detecta gatos, cachorros e cavalos, a saída da camada final é a possibilidade de que a imagem de entrada contenha um desses animais.
O que é uma camada de agrupamento?
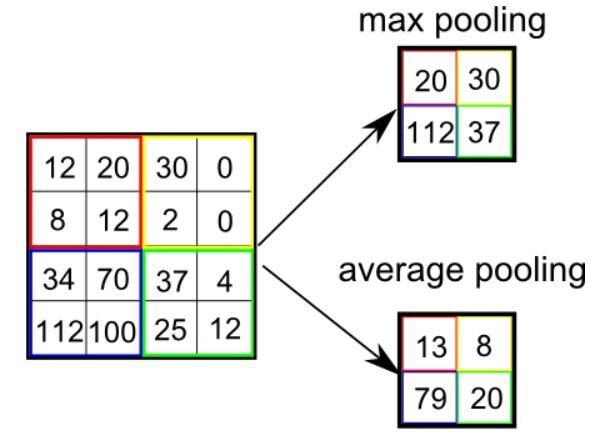
Semelhante à camada convolucional, a camada de agrupamento é responsável por reduzir o tamanho espacial da entidade convolvida. Isto é para Diminua a potência computacional necessária para processar dados. redução de dimensões. Existem dois tipos de agrupamento, agrupamento médio e agrupamento máximo. Eu só tive experiência com o Max Pooling até agora e não enfrentei nenhuma dificuldade.
Então, o que fazemos no Max Pooling é encontrar o valor máximo de um pixel de uma parte da imagem coberta pelo kernel. Max Pooling também funciona como Supressor de ruído. Ele elimina totalmente os gatilhos ruidosos e também realiza a remoção de ruído junto com a redução de dimensionalidade.
Por outro lado, Agrupamento médio devolver o média de todos os valores da parte da imagem coberta pelo kernel. O agrupamento médio simplesmente executa a redução da dimensionalidade como um mecanismo de supressão de ruído. Por tanto, Nós podemos dizer que A piscina máxima funciona muito melhor do que a piscina média.
Limitações
Apesar do poder e da complexidade dos recursos da CNN, fornecer resultados detalhados. Na raiz de tudo, é simplesmente uma questão de reconhecer padrões e detalhes que são tão pequenos e imperceptíveis que passam despercebidos ao olho humano. Mas quando se trata de entendimento o conteúdo da imagem falha.
Vamos dar uma olhada neste exemplo. Quando passamos a imagem abaixo para uma CNN, detecta uma pessoa por perto 30 anos e uma criança provavelmente por aí 10 anos. Mas quando olhamos para a mesma imagem, começamos a pensar em vários cenários diferentes. Talvez seja um dia de pai e filho, um piquenique ou talvez eles estejam acampando. Talvez seja um campo de escola e o menino marcou um gol e seu pai está feliz então ele pega.

Essas limitações são mais do que evidentes quando se trata de aplicações práticas. Por exemplo, As CNNs foram amplamente utilizadas para moderar o conteúdo nas redes sociais. Mas, apesar dos vastos recursos de imagem e vídeo em que foram treinados, você ainda não pode bloquear e remover completamente o conteúdo impróprio. Acontece que você marcou uma estátua de 30.000 anos com nudez no Facebook.
Vários estudos mostraram que CNNs treinados em ImageNet e outros conjuntos de dados populares não detectam objetos quando vistos sob diferentes condições de iluminação e de novos ângulos..
Isso significa que a CNN é inútil? Porém, apesar dos limites das redes neurais convolucionais, não há como negar que eles causaram uma revolução na inteligência artificial. Hoje em dia, CNNs são usados em muitos aplicações de visão de máquina como reconhecimento facial, pesquisar e editar imagens, realidade aumentada e mais. Como os avanços nas redes neurais convolucionais mostram, nossas conquistas são notáveis e úteis, mas ainda estamos muito longe de replicar componentes-chave da inteligência humana.

Obrigado pela leitura! Se você gostou de ler este artigo, por favor compartilhe para ajudar os outros a encontrá-lo! Sinta-se à vontade para deixar um comentário 💬 abaixo. Você pode se conectar comigo em GitHub, LinkedIn
Você tem comentários? Vamos ser amigos em Twitter.
Tudo de bom e feliz codificação! 😀
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do autor.





