Digitarcção
MongoDB é um banco de dados de documentos gratuito, de código aberto e sem SQL. É amplamente utilizado no desenvolvimento de aplicações web e também na implementação de soluções de Big Data.. De acordo com o relatório Database Engines, classificação alta em comparação com outros bancos de dados de documentos, como CouchDB, Reino, etc. É um banco de dados sem esquemas e permite documentos embutidos que representam relacionamentos complexos em um único registro. uma declaração do problema conforme mostrado abaixo
“Tenho muitos dados hierárquicos que desejo adicionar”.
O MongoDB fornece uma estrutura de agregação que pode ser usada para agregar uma grande quantidade de dados hierárquicos. Suporta muitas funções integradas e também diferentes tipos de indexação que melhoram o desempenho da consulta. Neste tutorial, você aprenderá como realizar um pipeline de agregação no MongoDB. Um pipeline de agregação é uma das estruturas básicas de agregação fornecidas pelo MongoDB. O pipeline de agregação processa documentos de entrada em vários estágios em ordem serial. Cada saída produzida em um estágio é movida para a próxima etapa, onde o processamento adicional pode ser feito neste subconjunto de documentos para atingir a saída agregada final.. Todas as amostras são implementadas usando a versão MongoDB 4.4.5.
Vamos mergulhar.
Pré-requisitos
Para fazer este tutorial, MongoDB deve ser instalado no sistema.
Configure a conexão
Primeiro, precisamos abrir uma conexão com o banco de dados usando o comando ‘MongoQuando eu vejo '>’ no indicador, você estará pronto para executar comandos relacionados às operações de banco de dados usadas nesta postagem.
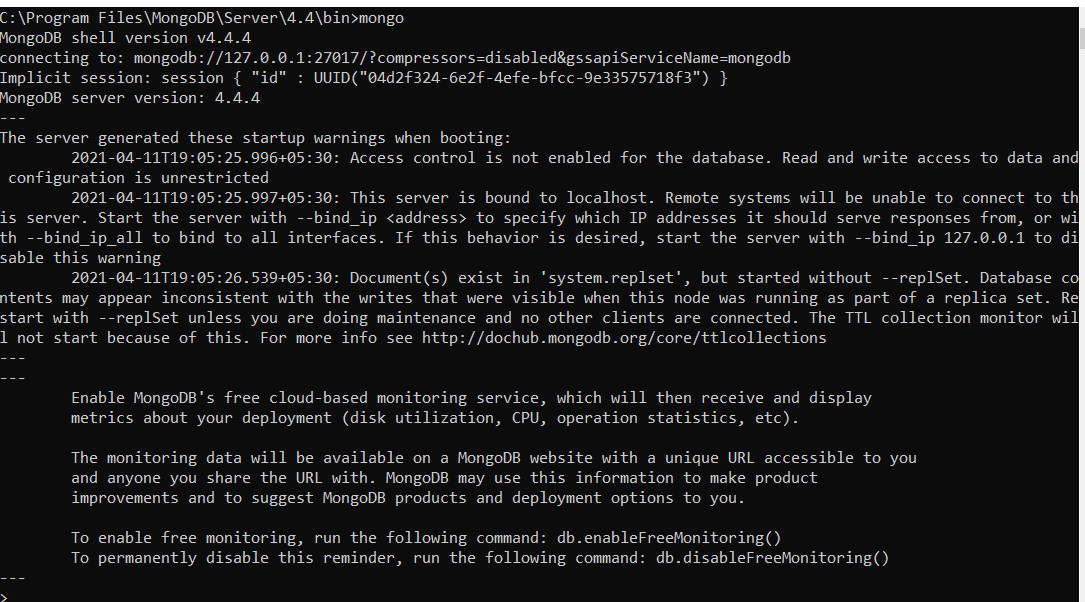
Criando banco de dados
Vamos criar um 'banco de dados testdb’ primeiro usando o “usar” comando.
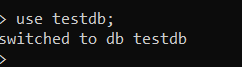
Como você pode ver acima, se o banco de dados existe, o comando acima irá usar esse banco de dados; pelo contrário, irá criar um novo banco de dados.
Agora vamos criar uma coleção chamada 'produtos’ dentro deste banco de dados usando o comando ‘Criar coleção’

Agora insira documentos de teste dentro da coleção com a ajuda do comando ‘Inserir muitos‘
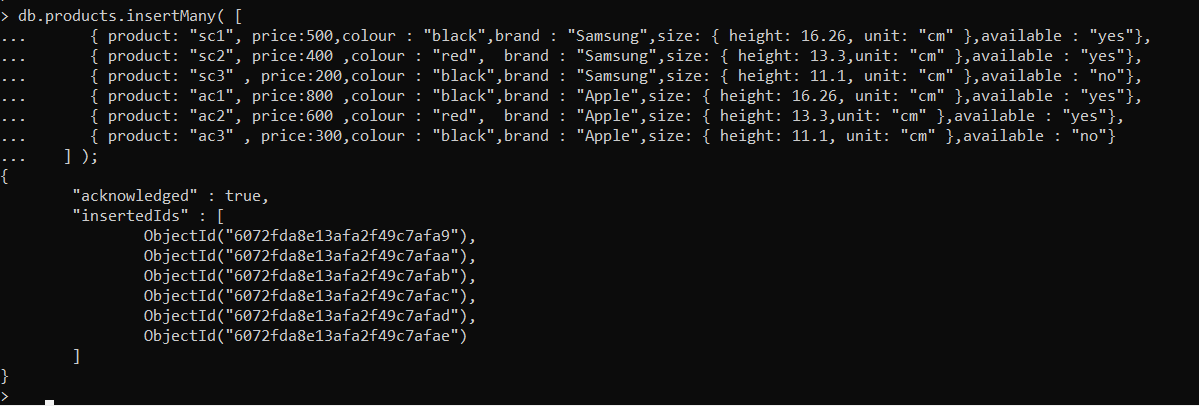
Os documentos foram inseridos corretamente. Você também pode verificar os documentos na coleção com o comando “achar”.

Criação de pipeline de agregação
Na coleção anterior, digamos que precisamos descobrir a quantidade total de vendas que ocorreram para cada uma das marcas.
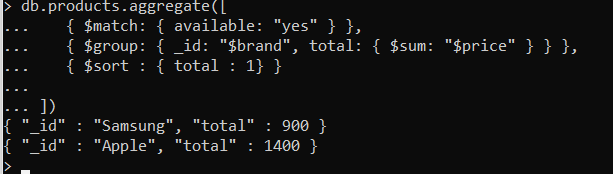
Apple e Samsung para telefone disponíveis. Então, primeiro temos que filtrar os documentos com base no valor disponível = “Verdade”. Isso é feito usando o comando “Corresponder” e também a primeira fase do Pipeline de agregação. Mais tarde, devemos encontrar a soma de “preço”, qual é o segundo estágio, como é mostrado a seguir.. Na segunda fase, o agrupamento é feito com base na marca e então a soma total do preço é calculada usando o comando “Grupo”
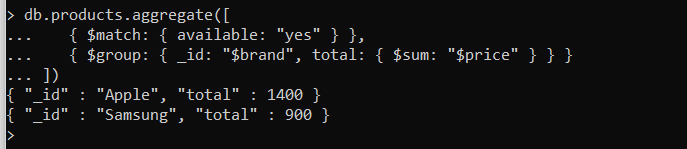
Vamos adicionar mais um estágio a esta saída chamada classificação para mostrar a soma com base em um preço mais alto a um preço mais baixo, conforme mostrado abaixo. O comando que usamos aqui é “Separar”.Aqui no pedido, 1 significa ordem ascendente e -1 significa ordem decrescente.
conclusão
Neste artigo, vimos como construir um pipeline de agregação usando MongoDB. Espero que isso seja útil e se você tiver algum comentário, sinta-se à vontade para comentar na próxima seção.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.
Sobre o autor
Eu sou Deepti Jakka, Eu gosto de fazer um blog sobre tópicos técnicos. Me encontre em https://learnfundas.com/sobre/





