Introdução
o neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. es una máquina de procesamiento de información y puede considerarse análoga al sistema nervioso humano. Assim como o sistema nervoso humano, que é composto de neurônios interconectados, Uma rede neural é composta de unidades de processamento de informações interconectadas. As unidades de processamento de informação não funcionam de forma linear. De fato, A rede neural obtém sua força do processamento paralelo de informações, permitindo que você lide com a não-linearidade. A rede neural torna-se útil para inferir significados e detectar padrões de conjuntos de dados complexos.
La red neuronal está considerada como una de las técnicas más útiles en el mundo de la analíticaAnalytics refere-se ao processo de coleta, Meça e analise dados para obter insights valiosos que facilitam a tomada de decisões. Em vários campos, como negócio, Saúde e esporte, A análise pode identificar padrões e tendências, Otimize processos e melhore resultados. O uso de ferramentas avançadas e técnicas estatísticas é essencial para transformar dados em conhecimento aplicável e estratégico.... De dados. Porém, É complexo e muitas vezes considerado uma caixa preta, quer dizer, Os usuários veem a entrada e saída de uma rede neural, mas não têm ideia sobre o processo de geração de conhecimento. Esperamos que o artigo ajude os leitores a aprender sobre o mecanismo interno de uma rede neural e ganhar experiência prática para implementá-lo em R.
Tabela de conteúdo
- O básico da rede neural
- Ajustando a rede neural em R
- Validação cruzada de uma rede neural
O básico da rede neural
Una red neuronal es un modelo caracterizado por una função de despertarA função de ativação é um componente chave em redes neurais, uma vez que determina a saída de um neurônio com base em sua entrada. Seu principal objetivo é introduzir não linearidades no modelo, permitindo que você aprenda padrões complexos em dados. Existem várias funções de ativação, como o sigmóide, ReLU e tanh, cada um com características particulares que afetam o desempenho do modelo em diferentes aplicações...., que é usado por unidades de processamento de informações interconectadas para transformar a entrada em saída. Uma rede neural sempre foi comparada ao sistema nervoso humano. A informação passa por unidades interconectadas análogas à passagem de informações através de neurônios em humanos.. A primeira camada da rede neural recebe entrada bruta, processa-o e passa as informações processadas para as camadas ocultas. A camada oculta passa as informações para a última camada, que produz a saída. A vantagem da rede neural é que ela é de natureza adaptativa. Aprenda com as informações fornecidas, quer dizer, treina-se a partir de dados, que tenham um resultado conhecido e otimizem seus pesos para melhor predição em situações com desfecho desconhecido.
Um perceptron, a saber. Rede neural de camada única, É a forma mais básica de uma rede neural. Um perceptron recebe informações multidimensionais e as processa usando uma soma ponderada e uma função de ativação. Ele é treinado usando um algoritmo de aprendizado e dados rotulados que otimizam os pesos no processador de adição. Uma grande limitação do modelo perceptivo é a sua incapacidade de lidar com a não-linearidade.. Uma rede neural multicamada supera essa limitação e ajuda a resolver problemas não lineares. o camada de entradao "camada de entrada" refere-se ao nível inicial em um processo de análise de dados ou em arquiteturas de redes neurais. Sua principal função é receber e processar informações brutas antes de serem transformadas por camadas subsequentes. No contexto do aprendizado de máquina, A configuração adequada da camada de entrada é crucial para garantir a eficácia do modelo e otimizar seu desempenho em tarefas específicas.... se conecta con la capa oculta, que a su vez se conecta a la Camada de saídao "Camada de saída" é um conceito utilizado no campo da tecnologia da informação e design de sistemas. Refere-se à última camada de um modelo ou arquitetura de software que é responsável por apresentar os resultados ao usuário final. Essa camada é crucial para a experiência do usuário, uma vez que permite a interação direta com o sistema e a visualização dos dados processados..... As conexões são ponderadas e os pesos são otimizados usando uma regra de aprendizado.
Existem muitas regras de aprendizagem que são usadas com a rede neural:
uma) Mínimo quadrado médio;
b) descenso de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em...;
c) A regra de Newton;
d) Gradiente conjugado, etc.
As regras de aprendizagem podem ser usadas em conjunto com o método de erro de propagação reversa. A regra de aprendizagem é usada para calcular o erro na unidade de saída. Esse erro se propaga de trás para frente para todas as unidades, de modo que o erro em cada unidade seja proporcional à contribuição dessa unidade para o erro total na unidade de saída. Erros em cada unidade são usados para otimizar o peso em cada conexão. o Figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas.... 1 Demonstra a estrutura de um modelo de rede neural simples para uma melhor compreensão.
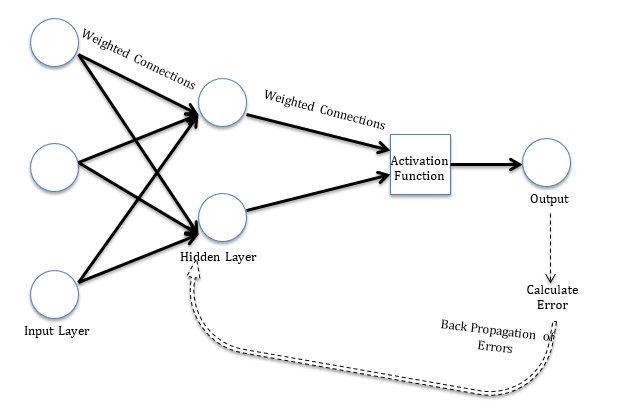
Figura 1 Um modelo de rede neural simples
Ajustando a rede neural em R
Agora vamos encaixar um modelo de rede neural em R. Neste artigo, usamos um subconjunto do conjunto de dados de cereais compartilhado pela Universidade Carnegie Mellon (CMU). Os detalhes do conjunto de dados podem ser encontrados no seguinte link: http://lib.stat.cmu.edu/DASL/Datafiles/Cereals.html. O objetivo é prever a classificação das variáveis cerealíferas como calorias., Proteínas, gordura, etc. O script R é fornecido lado a lado e comentado para melhor compreensão do usuário. . Os dados estão em formato .csv e podem ser baixados clicando em: cereal.
Defina o diretório de trabalho como R usando setwd () função e manter cereais.csv no diretório de trabalho. Usamos la calificación como variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... dependiente y las calorías, Proteínas, gordura, sódio e fibra como variáveis independentes. Dividimos los datos en TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... y conjunto de prueba. O conjunto de treinamento é usado para encontrar a relação entre variáveis dependentes e independentes, enquanto o conjunto de testes avalia o desempenho do modelo. Nós usamos o 60% do conjunto de dados como um conjunto de treinamento. A atribuição dos dados ao conjunto de treinamento e teste é feita por amostragem aleatória. Realizamos amostragem aleatória em R utilizando shows ( ) Função. Nós usamos set.seed () para gerar a mesma amostra aleatória a cada vez e Mantendo a consistência. Nós vamos usar o índiceo "Índice" É uma ferramenta fundamental em livros e documentos, que permite localizar rapidamente as informações desejadas. Geralmente, é apresentado no início de um trabalho e organiza os conteúdos de forma hierárquica, incluindo capítulos e seções. Sua correta preparação facilita a navegação e melhora a compreensão do material, tornando-se um recurso essencial para estudantes e profissionais de várias áreas.... variável ao ajustar a rede neural para criar conjuntos de dados de teste e treinamento. O script R é o seguinte:
## Criando variável de índice # Read the Data data = read.csv("cereais.csv", cabeçalho=T) # Random sampling samplesize = 0.60 * agora(dados) set.seed(80) índice = amostra( seq_len ( agora ( dados ) ), tamanho = tamanho da amostra ) # Create training and test set datatrain = data[ índice, ] datatest = dados[ -índice, ]
Agora encaixamos uma rede neural aos nossos dados. Nós usamos Neuralnet Biblioteca para análise. O primeiro passo é dimensionar o conjunto de dados de cereais. A escala dos dados é essencial porque, pelo contrário, Uma variável pode ter um grande impacto na variável de previsão apenas por causa de sua escala. O uso sem escala pode levar a resultados sem sentido. Técnicas comuns para dimensionamento de dados são: padronizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos.... mínima-máxima, Normalização do escore Z, medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos.... y MAD y estimadores de tan-h. A normalização mínimo-máximo transforma os dados em um intervalo comum, eliminando assim o efeito de escala de todas as variáveis. Ao contrário da normalização do escore Z e do método mediana e MAD, O método mínimo-máximo preserva a distribuição original das variáveis. Usamos a normalização mínimo-máxima para dimensionar dados. O script R para dimensionar os dados é o seguinte.
## Dimensionar dados para redes neurais max = aplicar(dados , 2 , max) min = aplicar(dados, 2 , min) dimensionado = as.data.frame(escala(dados, centro = min, escala = max - min))
Dados dimensionados são usados para se adaptar à rede neural. Visualizamos a rede neural com pesos para cada uma das variáveis. O script R é o seguinte.
## Ajustar rede neural # install library install.packages("Neuralnet ") # load library library(Neuralnet) # creating training and test set trainNN = scaled[índice , ] testNN = dimensionado[-índice , ] # fit neural network set.seed(2) NN = neuralnet(Classificação ~ calorias + proteína + GORDURA + sódio + fibra, TrainNN, oculto = 3 , linear.output = T ) # plot neural network plot(NN)
A Figura 3 Visualize a rede neural calculada. Nosso modelo tem 3 neurônios em sua camada oculta. Linhas pretas mostram conexões com pesos. Os pesos são calculados usando o algoritmo de retropropagação explicado acima. Linha azul mostra termo de viés.
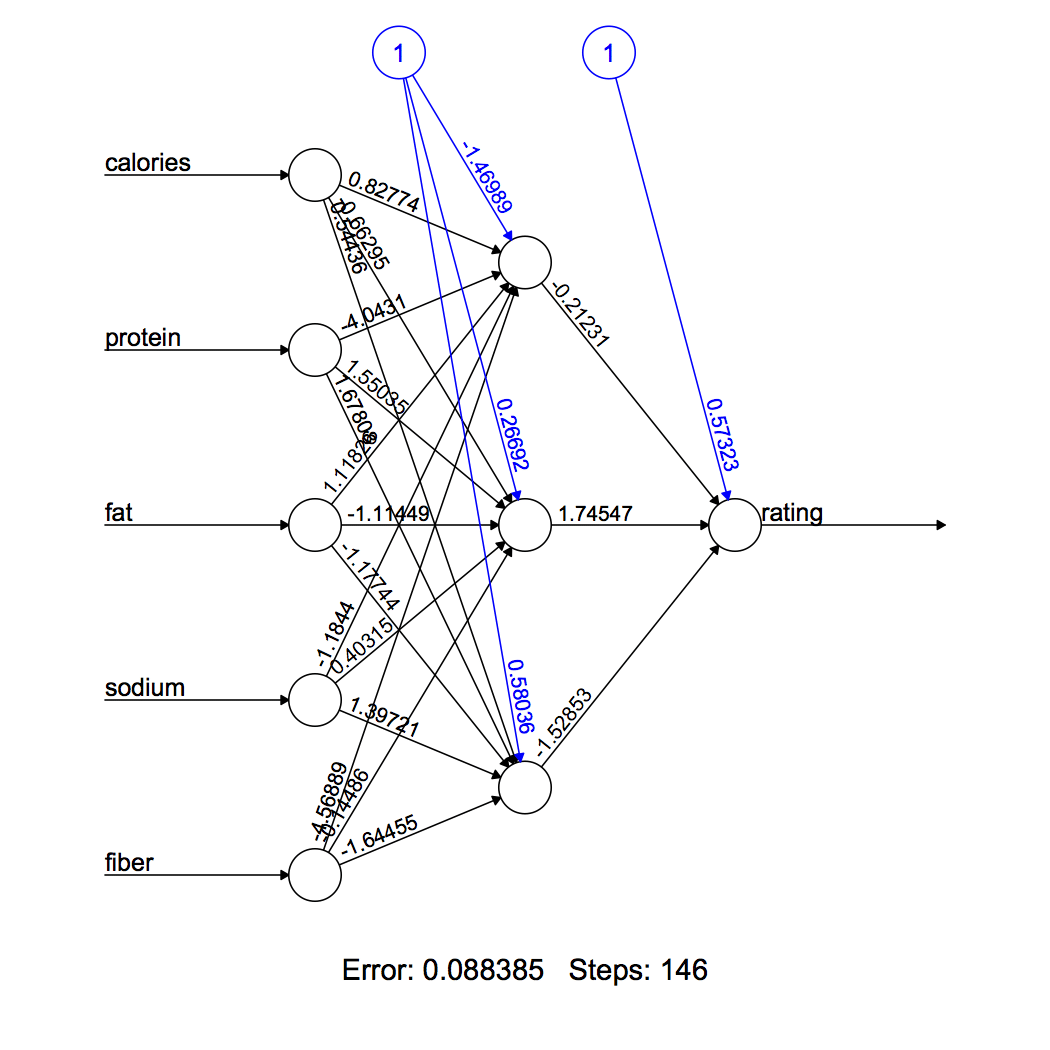
Figura 2 Neuronal vermelho
Prevemos a classificação usando o modelo de rede neural. O leitor deve lembrar que a classificação prevista será dimensionada e deve transformá-la para fazer uma comparação com a classificação real.. Também comparamos a classificação prevista com a classificação real usando a visualização. O RMSE para o modelo de rede neural é 6.05. O leitor pode aprender mais sobre o RMSE em outro artigo, que pode ser acessado clicando em aqui. O script R é o seguinte:
## Previsão usando rede neural predict_testNN = computação(NN, testNN[,c(1:5)]) predict_testNN = (predict_testNN$net.result * (max(data$rating) - min(data$rating))) + min(data$rating) enredo(datatest$rating, predict_testNN, col ="azul", pch=16, ylab = "classificação NN prevista", xlab = "Classificação Real") abline(0,1) # Calcular erro quadrático médio da raiz (RMSE) RMSE.NN = (soma((datatest$rating - predict_testNN)^algarismo) / agora(Teste de dados)) ^ 0.5
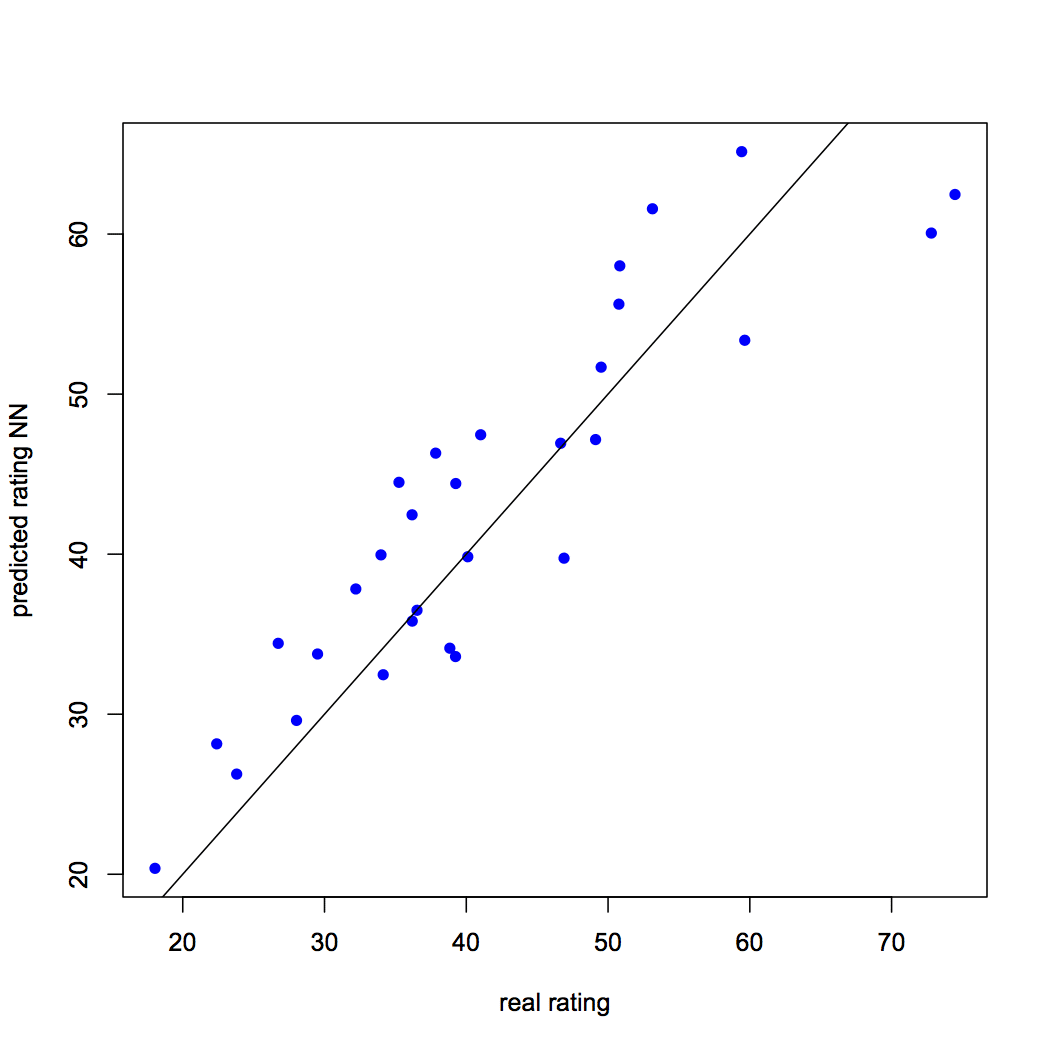
Figura 3: Classificação prevista versus classificação real usando uma rede neural
Validação cruzada de uma rede neural
Avaliamos nosso método de rede neural usando RMSE, que é um método residual de avaliação. O principal problema com os métodos de avaliação residual é que eles não nos informam sobre o comportamento do nosso modelo quando novos dados são inseridos.. Tentamos resolver o problema de “Novos dados” Dividindo nossos dados em treinamento e conjunto de testes, construindo o modelo no conjunto de treinamento e avaliando o modelo calculando o RMSE para o conjunto de testes. A divisão do teste de treinamento nada mais era do que a forma mais simples de método de validação cruzada conhecida como Método de retenção. Uma limitação do Método de retenção é a variância da métrica de avaliação de desempenho, no nosso caso RMSE, pode ser alto com base nos itens atribuídos ao conjunto de treinamento e teste.
A segunda técnica de validação cruzada é comumente Validação cruzada K-fold. Este método pode ser visto como recorrente Método de retenção. Os dados completos são divididos em k subconjuntos iguais e cada vez que um subconjunto é atribuído como um conjunto de teste, Outros são usados para treinar o modelo. Cada ponto de dados tem a oportunidade de estar no conjunto de testes e no conjunto de treinamento, Portanto, esse método reduz a dependência do desempenho na divisão de treinamento de teste e reduz a variância das métricas de desempenho.. O caso extremo de Validação cruzada K-fold ocorrerá quando k for igual ao número de pontos de dados. Isso significaria que o modelo preditivo é treinado em todos os pontos de dados, exceto em um ponto de dados., que assume o papel de um conjunto de testes. Este método de deixar um ponto de dados como um conjunto de testes é conhecido como Deixar uma validação cruzada.
Agora vamos realizar Validação cruzada K-fold No modelo de rede neural que construímos na seção anterior. O número de itens no conjunto de treinamento, j, variam de 10 uma 65 e para cada j, Eles são extraídos 100 Exemplos de conjunto de dados. O restante dos itens em cada caso é atribuído ao conjunto de testes. O modelo é treinado em cada um dos 5600 Conjuntos de dados de treinamento e, em seguida, testados nos conjuntos de teste correspondentes. Calculamos o RMSE de cada um dos conjuntos de testes. Os valores RMSE para cada um dos conjuntos são armazenados em uma matriz.[100 X 56]. Este método garante que os nossos resultados estão livres de qualquer viés de amostra e verifica a robustez do nosso modelo.. Usamos loop para aninhado. O script R é o seguinte:
## Validação cruzada do modelo de rede neural # install relevant libraries install.packages("Bota") install.packages("plyr |") # Load libraries library(Bota) biblioteca(plyr |) # Initialize variables set.seed(50) k = 100 RMSE.NN = NULL List = list( ) # Fit neural network model within nested for loop for(j em 10:65){ para (eu em 1:k) { índice = amostra(1:agora(dados),j ) trainNN = dimensionado[índice,] testNN = dimensionado[-índice,] datatest = dados[-índice,] NN = neuralnet(Classificação ~ calorias + proteína + GORDURA + sódio + fibra, TrainNN, oculto = 3, linear.output= T) predict_testNN = computação(NN,testNN[,c(1:5)]) predict_testNN = (predict_testNN$net.result*(max(data$rating)-min(data$rating)))+min(data$rating) RMSE.NN [eu]<- (soma((datatest$rating - predict_testNN)^algarismo)/agora(Teste de dados))↑0,5 } Lista[[j]] = RMSE.NN } Matrix.RMSE = do.call(cbind, Lista)
Os valores RMSE podem ser acessados usando a variável Matrix.RMSE. O tamanho do array é grande; portanto, Tentaremos entender os dados por meio de visualizações. Primeiro, prepararemos um diagrama de caixa para uma das colunas em Matrix.RMSE, quando o conjunto de treinamento tem um comprimento igual a 65. Se pueden preparar estos plotagens de caixaDiagramas de caixa, Também conhecido como diagramas de caixa e bigode, são ferramentas estatísticas que representam a distribuição de um conjunto de dados. Esses diagramas mostram a mediana, Quartis e outliers, permitindo que a variabilidade e a simetria dos dados sejam visualizadas. Eles são úteis na comparação entre diferentes grupos e na análise exploratória, facilitando a identificação de tendências e padrões nos dados.... para cada una de las longitudes del conjunto de entrenamiento (10 uma 65). O script R é o seguinte.
## Preparar boxplot boxplot(Matriz.RMSE[,56], ylab = "RMSE", main = "RMSE BoxPlot (comprimento do conjunto de traning = 65)")
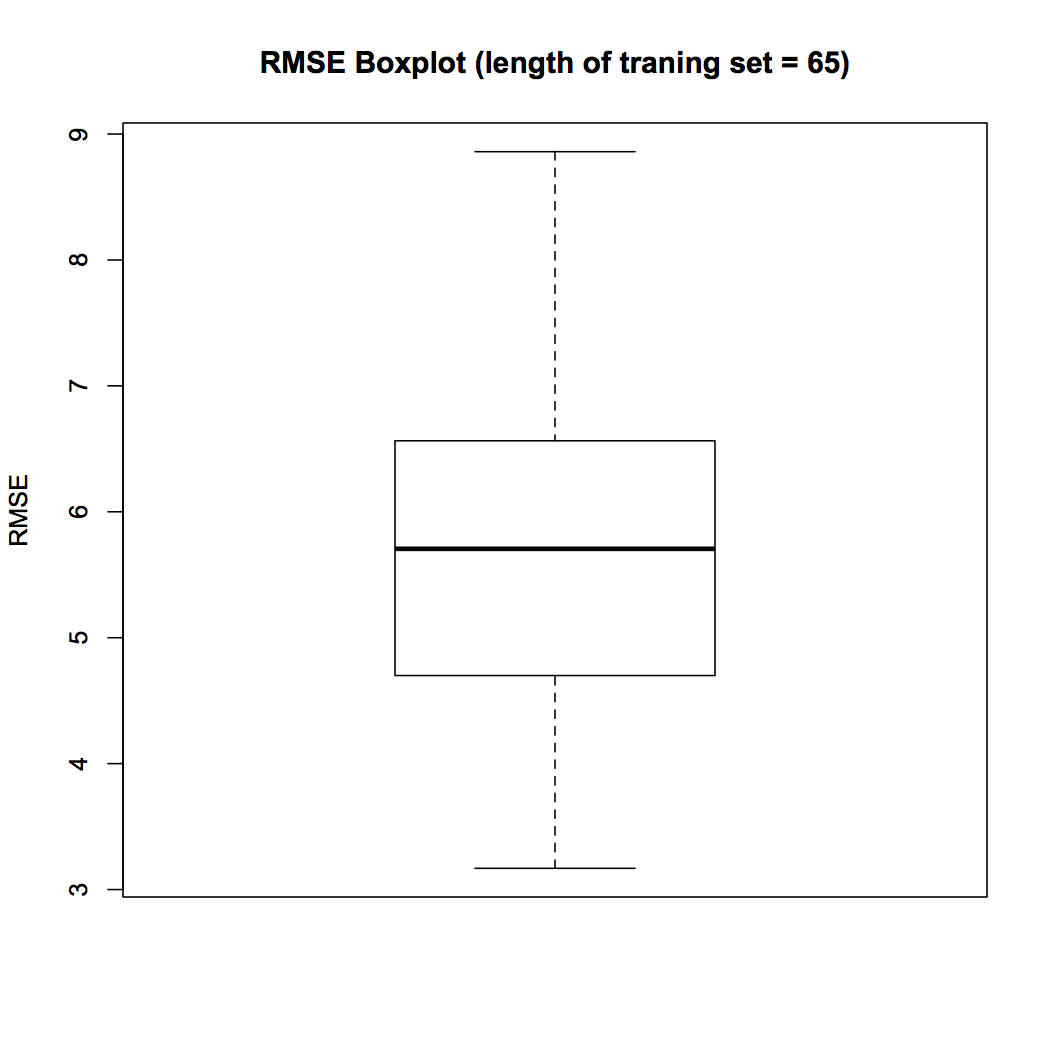
Figura 4 Box plot
O diagrama de caixa da Fig.. 4 mostra que a mediana do RMSE em 100 amostras quando a duração do conjunto de treinamento é definida como 65 isto é 5.70. Na visualização a seguir, estudamos a variação do RMSE com a duração do conjunto de treinamento. Calculamos a mediana do RMSE para cada um dos comprimentos do conjunto de treinamento e os plotamos usando o seguinte script R.
## Variação da mediana do RMSE
install.packages("matrixStats")
biblioteca(matrixStats)
med = colMedians(Matriz.RMSE)
X = seq(10,65)
enredo (med~X, tipo = "eu", xlab = "duração do conjunto de treinamento", ylab = "mediate o RMSE", main = "Variação do RMSE com a duração do conjunto de treinamento")
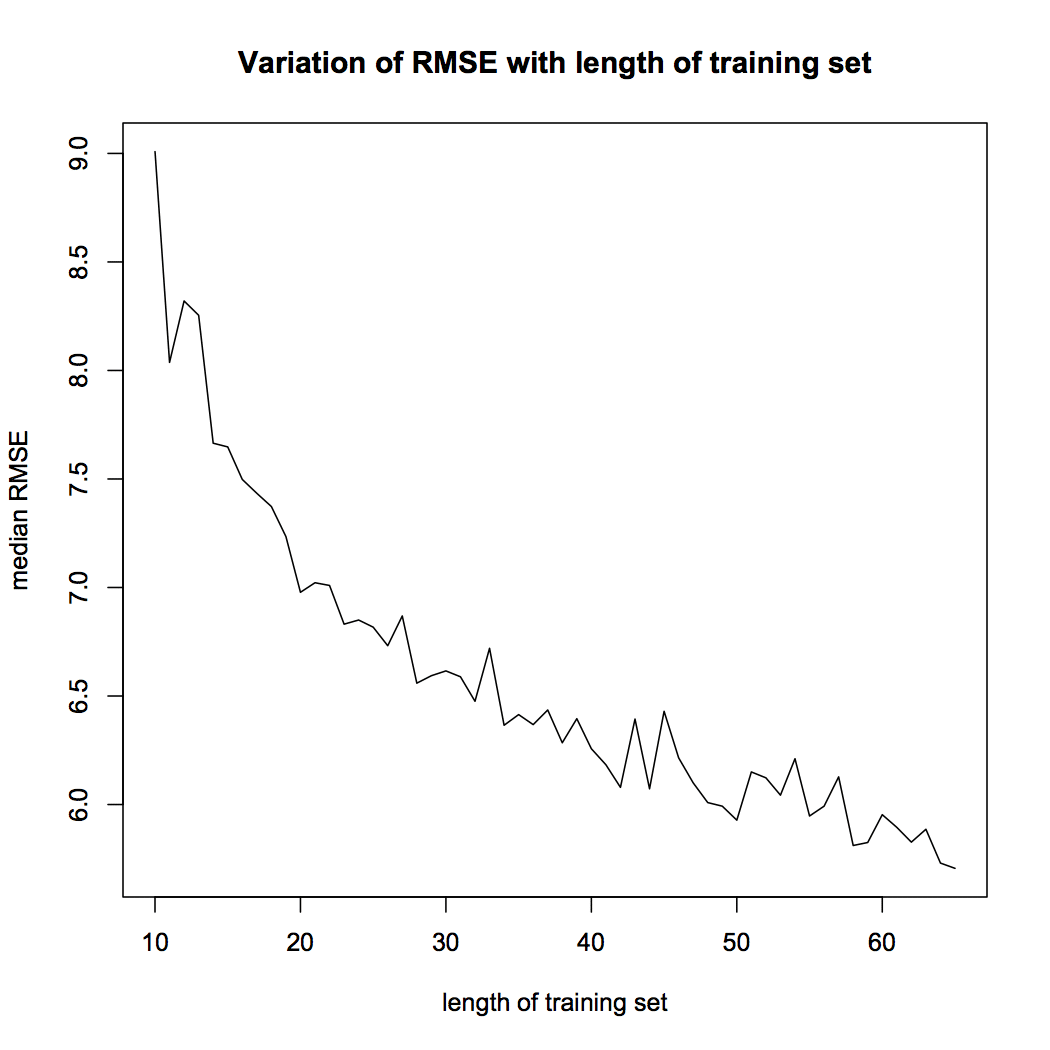
Figura 5 Variação RMSE
A Figura 5 muestra que la mediana de RMSE de nuestro modelo disminuye a mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que la duración del entrenamiento de la serie. Este é um resultado importante. O leitor deve lembrar que a precisão do modelo depende da duração do conjunto de treinamento. O desempenho do modelo de rede neural é sensível à divisão de teste de treinamento.
Notas finais
O artigo discute os aspectos teóricos de uma rede neural, a sua aplicação em R e avaliação pós-formação. A rede neural é inspirada no sistema nervoso biológico. Semelhante ao sistema nervoso, As informações passam por camadas de processadores. A importância das variáveis é representada pelos pesos de cada conexão. O artigo fornece uma compreensão básica do algoritmo de retropropagação, que é usado para atribuir esses pesos. Neste artigo também implementamos uma rede neural em R. Usamos um conjunto de dados publicamente disponível compartilhado pela CMU. O objetivo é prever a classificação de cereais usando informações como calorias., gordura, Proteínas, etc. Depois de construir a rede neural, Avaliamos a precisão e robustez do modelo. Calculamos o RMSE e realizamos análises de validação cruzada. Na validação cruzada, Verificamos a variação na precisão do modelo à medida que a duração do conjunto de treinamento muda. Consideramos conjuntos de treinamento com uma duração de 10 uma 65. Para cada comprimento, são selecionados aleatoriamente 100 amostras e mediana RMSE é calculada. Mostramos que a precisão do modelo aumenta quando o conjunto de treinamento é grande. Antes de usar o modelo para previsão, É importante verificar a robustez do desempenho através da validação cruzada.
O artigo fornece uma revisão rápida da rede neural e é uma referência útil para entusiastas de dados. Fornecemos um código R comentado ao longo do artigo para ajudar os leitores com experiência prática no uso de redes neurais..
Bio: Chaitanya Sagar é o fundador e CEO da análise perceptiva. A Perceptive Analytics é uma das principais empresas de análise da Índia. Trabalhe em Marketing Analytics para empresas de comércio eletrônico, Varejistas e produtos farmacêuticos.





