Este artigo foi publicado como parte do Data Science Blogathon
Introdução
O Aprendizado de Máquina é um campo da tecnologia que se desenvolve com imensas habilidades e aplicações na automação de tarefas, onde nenhuma intervenção humana ou programação explícita é necessária.
O poder do aprendizado de máquina é tão grande que podemos ver que seus aplicativos estão em alta em quase todos os lugares de nossas vidas diárias.. O ML resolveu muitos problemas que existiam antes e fez com que as empresas no mundo progredissem muito.
Hoje, vamos analisar um desses problemas práticos e criar uma solução (modelo) por conta própria usando ML.
O que há de tão empolgante nisso?
Nós vamos, vamos implementar nosso modelo construído usando aplicativos Flask e Heroku. E ao final, teremos aplicativos da web totalmente funcionais em nossas mãos.
Por que é importante implementar seu modelo?
Os modelos de aprendizado de máquina geralmente visam ser uma solução para um problema ou problemas existentes. E em algum momento da sua vida, você deve ter pensado em como seu modelo seria uma solução e como as pessoas usariam isso? De fato, as pessoas não podem usar seus notebooks e códigos diretamente, e é aí que você precisa implementar seu modelo.
Você pode implementar seu modelo, como uma API ou serviço da web. Aqui, estamos usando a microestrutura Flask. O Flask define um conjunto de restrições para o aplicativo da web enviar e receber dados.
Atenção sistema de previsão de preços
Estamos prestes a implementar um modelo de ML para a previsão e análise de preços de venda de automóveis. Este tipo de sistema é útil para muitas pessoas.
Imagine uma situação em que você tem um carro velho e deseja vendê-lo. Claro, você pode abordar um agente para isso e encontrar o preço de mercado, mas mais tarde você terá que pagar do seu bolso pelo serviço deles ao vender seu carro. Mas, E se você pudesse saber o preço de venda do seu carro sem a intervenção de um agente? Ou se você é um agente, isso definitivamente tornará seu trabalho mais fácil. sim, este sistema já aprendeu sobre os preços de venda anteriores por anos de vários carros.
Então, para ser claros, Esta aplicação web implementada irá fornecer-lhe o preço de venda aproximado do seu carro de acordo com o tipo de combustível, Anos de serviço, o preço do showroom, o número de proprietários anteriores, os quilômetros percorridos, se você é um distribuidor / individual e, finalmente, se o tipo de transmissão é manual / automático. E isso é um brownie point.
Qualquer tipo de modificação também pode ser incorporado posteriormente neste aplicativo. Só é possível depois fazer uma facilidade para atender compradores. Esta é uma boa ideia para um grande projeto que você pode experimentar. Você pode implementar isso como um aplicativo como OLA ou qualquer aplicativo de comércio eletrônico. Os aplicativos de aprendizado de máquina não terminam aqui. Do mesmo modo, existem infinitas possibilidades que você pode explorar. Mas por enquanto, deixe-me ajudá-lo a criar o modelo para previsão do preço do carro e seu processo de implementação.
Importar conjunto de dados
O conjunto de dados está anexado à pasta GitHub. Verifique aqui
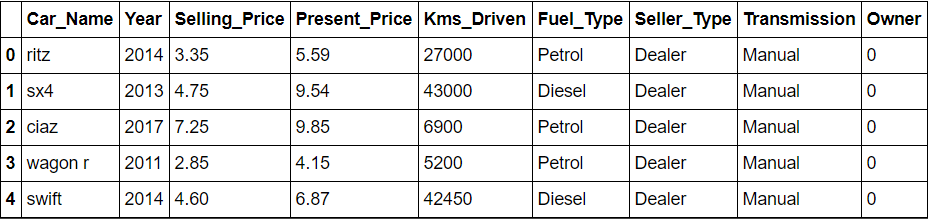
Os dados consistem em 300 linhas e 9 colunas. Já que nosso objetivo é encontrar o preço de venda, o atributo de destino e também o preço de venda, as características restantes são tomadas para análise e previsões.
importar numpy como np importar pandas como pd data = pd.read_csv(r'C:UsersSURABHIOneDriveDocumentsprojectsdatasetscar.csv ') data.head()
Engenharia de funções
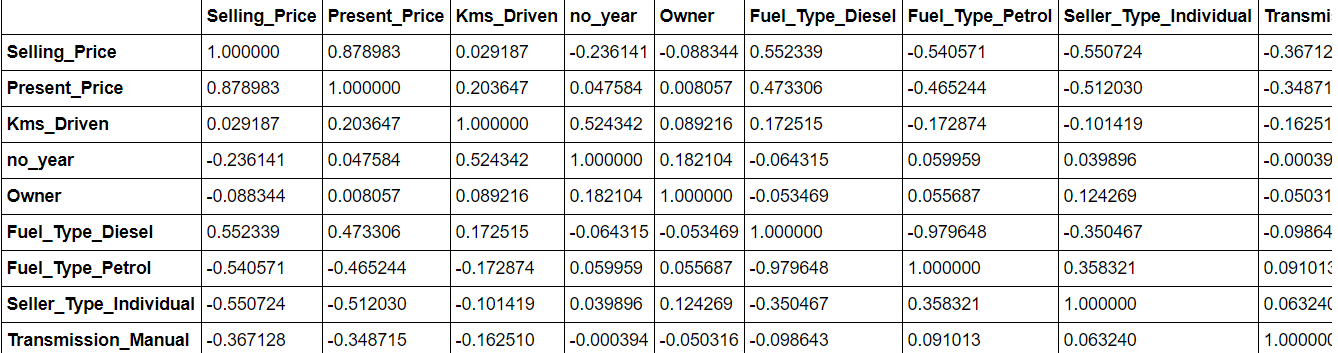
Os dados. corr () vai lhe dar uma ideia da correlação entre todos os atributos no conjunto de dados. Mais recursos correlacionados podem ser removidos, pois podem causar um ajuste excessivo do modelo.
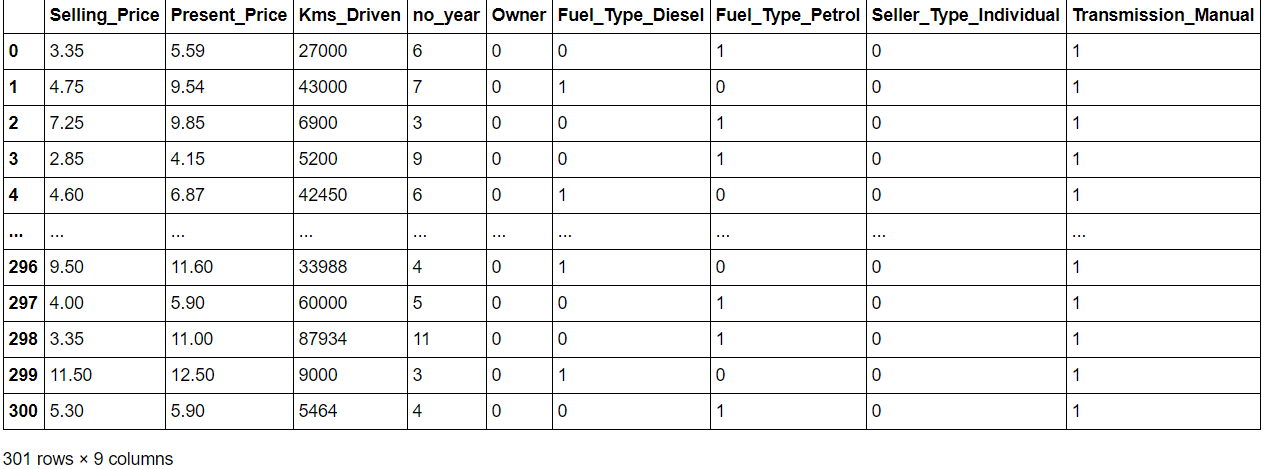
data = data.drop(['Car_Name'], eixo = 1) dados['ano atual'] = 2020 dados['no_year'] = dados['ano atual'] - dados['Ano'] data = data.drop(['Ano','ano atual'],eixo = 1) data = pd.get_dummies(dados,drop_first = True) dados = dados[['Preço de venda','Present_Price','Kms_Driven','no_year','Proprietário','Fuel_Type_Diesel','Fuel_Type_Petrol', 'Seller_Type_Individual','Transmission_Manual']] dados
data.corr()
A seguir, dividimos os dados em conjuntos de treinamento e teste.
x = data.iloc[:,1:] y = data.iloc[:,0]
Descubra a importância das funções para eliminar funções indesejadas
A biblioteca extratressregressor permite que você veja a importância dos recursos e, portanto, remover as características menos importantes dos dados. É sempre recomendado remover as funções desnecessárias porque elas podem definitivamente produzir melhores pontuações de precisão.
from sklearn.ensemble import ExtreesRegressor model = ExtraTreesRegressor() model.fit(x,e)

model.feature_importances_
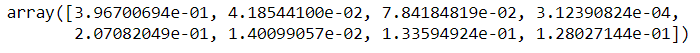
Otimização de hiperparâmetros
Isso é feito para obter os valores ideais para uso em nosso modelo, isso também pode, até certo ponto,
ajuda a obter bons resultados na previsão
n_estimators = [int(x) para x em np.linspace(start = 100, parar = 1200, num = 12)] max_features = ['auto','sqrt'] max_depth = [int(x) para x em np.linspace(5,30,num = 6)] min_samples_split = [2,5,10,15,100] min_samples_leaf = [1,2,5,10]
grade = {'n_estimators': n_estimators,
'max_features': max_features,
'profundidade máxima': profundidade máxima,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
imprimir(rede)
# Produção
{'n_estimators': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200],
'max_features': ['auto', 'sqrt'],
'profundidade máxima': [5, 10, 15, 20, 25, 30],
'min_samples_split': [2, 5, 10, 15, 100],
'min_samples_leaf': [1, 2, 5, 10]}
Teste de trem dividido
from sklearn.model_selection import train_test_split #importing train test split module x_train, x_test,y_train,y_test = train_test_split(x,e,random_state = 0, test_size = 0.2)
Treinando o modelo
Usamos o regressor de floresta aleatório para prever os preços de venda, pois este é um problema de regressão e essa floresta aleatória usa várias árvores de decisão e mostrou bons resultados para meu modelo.
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor()
hyp = RandomizedSearchCV(estimador = modelo,
param_distributions = grid,
n_iter = 10,
pontuação = 'neg_mean_squared_error'
cv = 5, detalhado = 2,
random_state = 42, n_jobs = 1)
hip.fit(x_train,y_train)
hyp é um modelo criado usando os hiperparâmetros ideais obtidos por meio de validação cruzada de pesquisa aleatória
Produção
Agora finalmente usamos o modelo para prever o conjunto de dados de teste.
y_pred = hyp.predict(x_test) y_pred

Para usar a estrutura Flask para implantação, é necessário empacotar todo este modelo e importá-lo para o arquivo Python para criar aplicações web. Portanto, despejamos nosso modelo no arquivo pickle usando o código fornecido.
importar picles
arquivo = aberto("arquivo.pkl", "wb") # abrindo um novo arquivo no modo de escrita
pickle.dump(hip, Arquivo) # despejar o modelo criado em um arquivo de pickle
Código completo
https://github.com/SurabhiSuresh22/Car-Price-Prediction/blob/master/car_project.ipynb
Moldura de frasco
O que precisamos é de um aplicativo da web que contenha um formulário para receber a entrada do usuário e retornar as previsões do modelo. Então, iremos desenvolver uma aplicação web simples para este. A interface é feita usando HTML e CSS simples. Aconselho você a revisar os conceitos básicos de desenvolvimento da web para entender o significado do código escrito para a interface. Também seria ótimo se eu soubesse a moldura do frasco. Cruzar é vídeo se você é novo no FLASK.
Deixa eu te explicar, brevemente, o que codifiquei usando FLASK.
Então, vamos começar o código importando todas as bibliotecas necessárias usadas aqui.
from flask importar Flask, render_template, solicitar importar picles pedidos de importação importar numpy como np
Como você sabe, temos que importar o modelo salvo aqui para fazer previsões a partir dos dados fornecidos pelo usuário. Então, estamos importando o modelo salvo
model = pickle.load(abrir("model.pkl", "rb"))
Agora vamos para o código para criar o aplicativo real do frasco.
app = Flask(_nome_)
@ app.route("/") # isso nos direcionará para a página inicial quando clicarmos no link do nosso aplicativo da web
def casa():
return render_template("home.html") # pagina inicial
@ app.route("/prever", métodos = ["PUBLICAR"]) # isso funciona quando o usuário clica no botão de previsão
def prever():
ano = int(request.form["ano"]) # pegando dados de ano do usuário
tot_year = 2020 - ano
present_price = float(request.form["present_price"]) #levando o prêmio presente
fuel_type = request.form["tipo de combustível"] # tipo de combustível do carro
# loop if para atribuição de valores numéricos
if fuel_type == "Gasolina":
combustível_P = 1
fuel_D = 0
outro:
combustível_P = 0
fuel_D = 1
kms_driven = int(request.form["kms_driven"]) # total de quilômetros rodados do carro
transmissão = solicitação.form["transmissão"] # tipo de transmissão
# atribuindo valores numéricos
if transmisson == "Manuel":
transmissão_manual = 1
outro:
transmissão_manual = 0
seller_type = request.form["vendedor_tipo"] # tipo de vendedor
if seller_type == "Individual":
vendedor_individual = 1
outro:
vendedor_individual = 0
owner = int(request.form["proprietário"]) # número de proprietários
valores = [[
present_price,
kms_driven,
proprietário,
tot_year,
fuel_D,
combustível_P,
vendedor_individual,
transmissão_manual
]]
# criou uma lista de todos os valores inseridos pelo usuário, em seguida, usá-lo para a previsão
prediction = model.predict(valores)
previsão = rodada(predição[0],2)
# retornando o valor predito em ordem para exibir no aplicativo da web de front end
return render_template("home.html", pred = "O preço do carro é {} Lakh".formato(flutuador(predição)))
if _name_ == "_a Principal_":
app.run(debug = True)
Implementação com Heroku
Tudo que você precisa fazer é conectar seu repositório GitHub contendo todos os arquivos necessários para o projeto com o Heroku. Para todos aqueles que não sabem o que é Heroku, Heroku é uma plataforma que permite aos desenvolvedores criar, executar e operar aplicativos em nuvem.
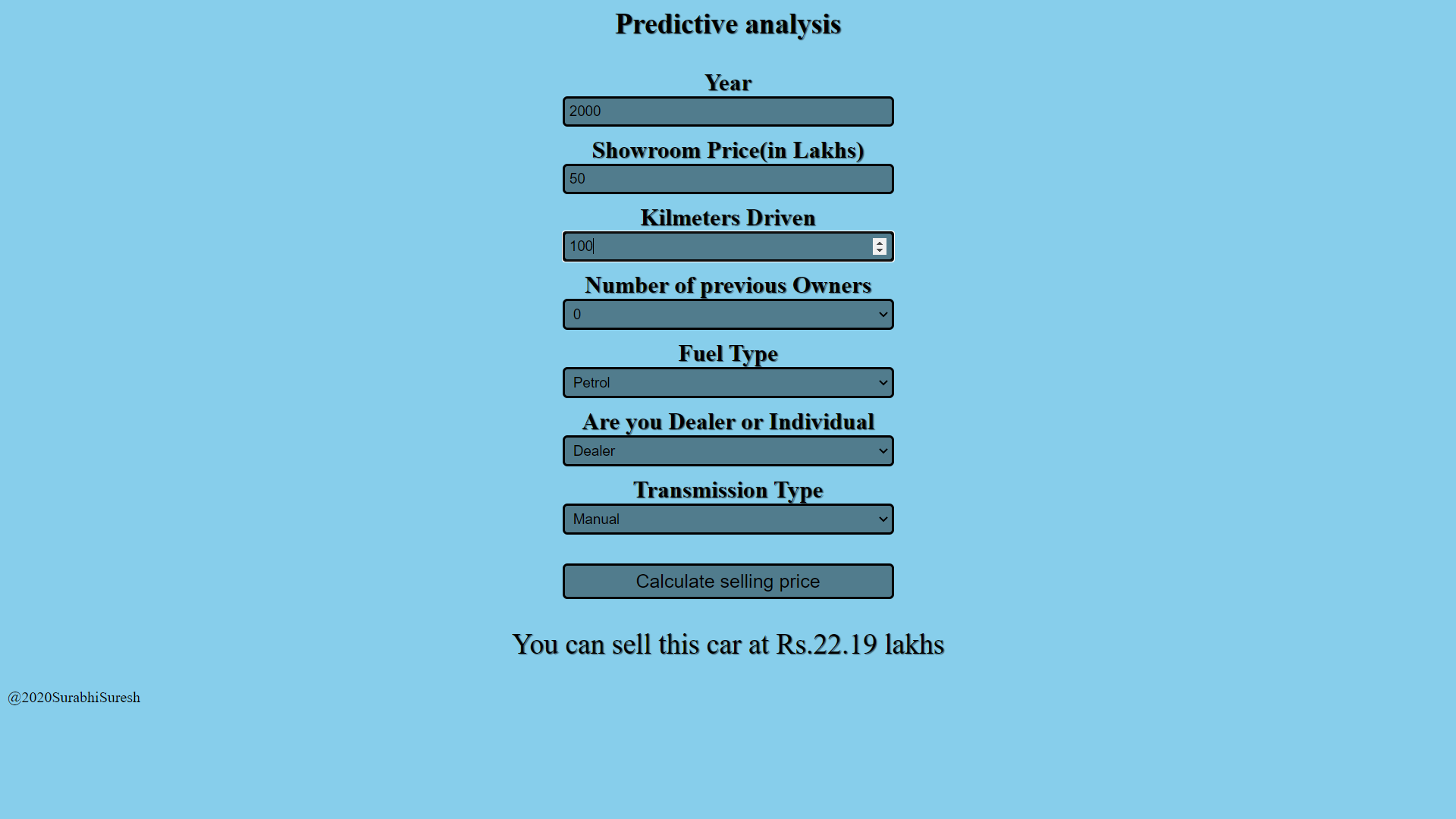
Este é o link para o aplicativo da web que criei usando a plataforma Heroku. Então, vimos o processo de construção e implementação de um modelo de aprendizado de máquina. Você também pode fazer isso, aprenda mais e sinta-se à vontade para experimentar coisas novas e desenvolvê-las.
https://car-price-analysis-app.herokuapp.com/
conclusão
Então, vimos o processo de construção e implementação de um modelo de aprendizado de máquina. Você também pode fazer isso, aprenda mais e sinta-se à vontade para experimentar coisas novas e desenvolvê-las. Sinta-se à vontade para se conectar comigo no ligado em.
Obrigado
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





