Introdução
Aprendizado de máquina e imagens têm uma ótima relação, a classificação de imagens tem sido um dos principais papéis do aprendizado de máquina ao longo dos anos.. Tem sido muito útil durante a pandemia COVID-19 reconhecer pessoas que não seguem as regras, como usar máscaras e manter distância..
Pré-requisitos
Cada programa tem alguns pré-requisitos para resolver problemas relacionados ao meio ambiente. Estamos construindo um conjunto de dados para um projeto de aprendizado de máquina, o requisito mínimo para isso é uma máquina com python3 instalado e um módulo OpenCV nele.
Estou usando o Caderno Jupyter no meu sistema.. Se você também quiser usar as mesmas configurações, você precisa instalar Anaconda em sua máquina e, em seguida, instalar OpenCV.
Instale o OpenCV
Para instalar OpenCV, abrir o prompt de comando se você não estiver usando anaconda. Pelo contrário, abrir o prompt de comando anaconda a partir de pesquisa janelas e digitar o comando fornecido abaixo.
pip instalar opencv-python=3.4.2.17
Agora você está pronto para codificar e preparar seu conjunto de dados.
Etapas envolvidas
Aqui vamos cobrir todas as etapas envolvidas na criação deste programa.
Paso 1: Módulos de importação
Primeiro, temos que importar todos os módulos necessários para o console do programa. Só precisamos de dois módulos., um é o “OpenCV” e o outro é o módulo “os”. O Opencv é usado para capturar e renderizar a imagem usando a câmera do laptop e o módulo do sistema operacional é usado para criar um diretório.

import cv2 as cv
import os
Paso 2: criar um objeto de câmera
Como temos que criar nosso próprio conjunto de dados de imagem, precisamos da câmera, e o OpenCV nos ajuda a criar objetos de câmera que podem ser usados mais tarde para várias ações.

#enredo 0 is given to use the default camera of the laptop camera = cv.VideoCapture(0) #Now check if the camera object is created successfully if not camera.isOpened(): imprimir("A câmera não está aberta... Sair") sair()
Paso 3: criar pastas de tag
Agora, precisamos criar pastas para cada rótulo por uma questão de diferenciação. usar o código abaixo para criar essas pastas, você pode adicionar quantas tags quiser. Nós demos nomes para nossas tags de acordo com o jogo: pedra, papel, tesoura. Estamos preparando um conjunto de dados que poderia classificar a imagem se for uma pedra, um papel, uma tesoura ou apenas um fundo.

#criando uma lista de lables "Você poderia adicionar quantos quiser"
Rótulos = ["Fundo","Pedra","Papel","Tesoura"]
#Now create folders for each label to store images
for label in Labels:
se não os.path.existe(rótulo):
os.mkdir(rótulo)
Paso 4: passo final para capturar imagens
Este é o passo final e mais crucial do programa. Comentários foram escritos online para facilitar a compreensão. Aquí tenemos que capturar imágenes y almacenar esas imágenes de acuerdo con la carpeta de etiquetas. Lea el código a fondo, hemos mencionado cada pequeña cosa aquí.
para pasta em Rótulos:
#usando variável de contagem para nomear as imagens no conjunto de dados.
contagem = 0
#Taking input to start the capturing
print("Pressione 's' para iniciar a coleta de dados para"+pasta)
userinput = entrada()
se o usuário colocar != 's':
imprimir("Entrada errada..........")
sair()
#Clicando 200 imagens por rótulo, você pode mudar como quiser.
enquanto contagem<200:
#read returns two values one is the exit code and other is the frame
status, quadro = câmera.ler()
#check if we get the frame or not
if not status:
imprimir("O quadro não foi capturado. Sair...")
break
#convert the image into gray format for fast caculation
gray = cv.cvtColor(quadro, cv.COLOR_BGR2GRAY)
#display window with gray image
cv.imshow("Janela de vídeo",cinza)
#resizing the image to store it
gray = cv.resize(cinza, (28,28))
#Store the image to specific label folder
cv.imwrite('C:/Usuários/HP/Documentos/AnacondaML/'+pasta+'/img'+str(contar)+'.png',cinza)
count=count+1
#to quite the display window press 'q'
if cv.waitKey(1) == ord('q'):
pausa
# Quando tudo feito, release the capture
camera.release()
cv.destroyAllWindows()
Implementación práctica
Agora, ejecute el programa para crear el conjunto de datos. Primero proporcionaremos el fondo, luego la piedra, el papel y las tijeras. Antes de la implementación, você deve sempre ser claro sobre o que você codificou e como a saída vai ajudá-lo a resolver o requisito do caso de uso. Vamos fazer isso...
Execute o programa de uma vez
Estamos usando o caderno jupyter para executar este programa, você pode usar qualquer intérprete Python. Primeiro, ir para o menu celular e clicar “Corra tudo”, isso vai executar todas as células disponíveis em um swoop caiu.
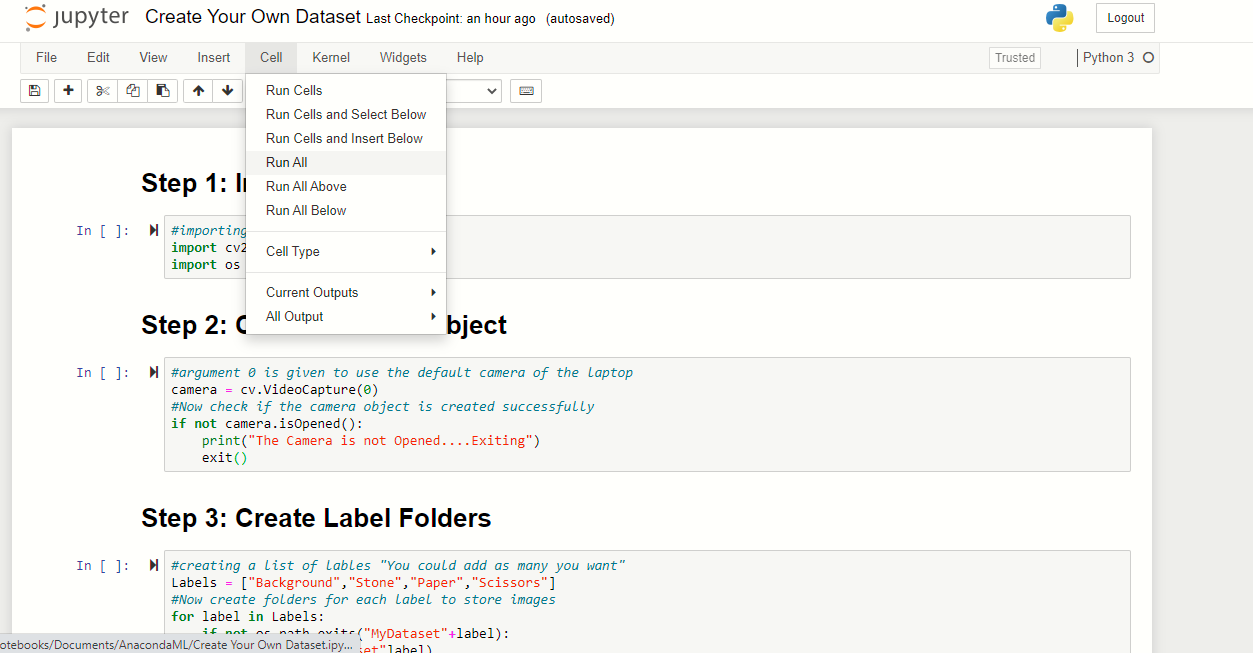
Agora, uma mensagem de entrada será gerada, imprensa 's’ e pressione enter para começar a salvar imagens para o fundo.
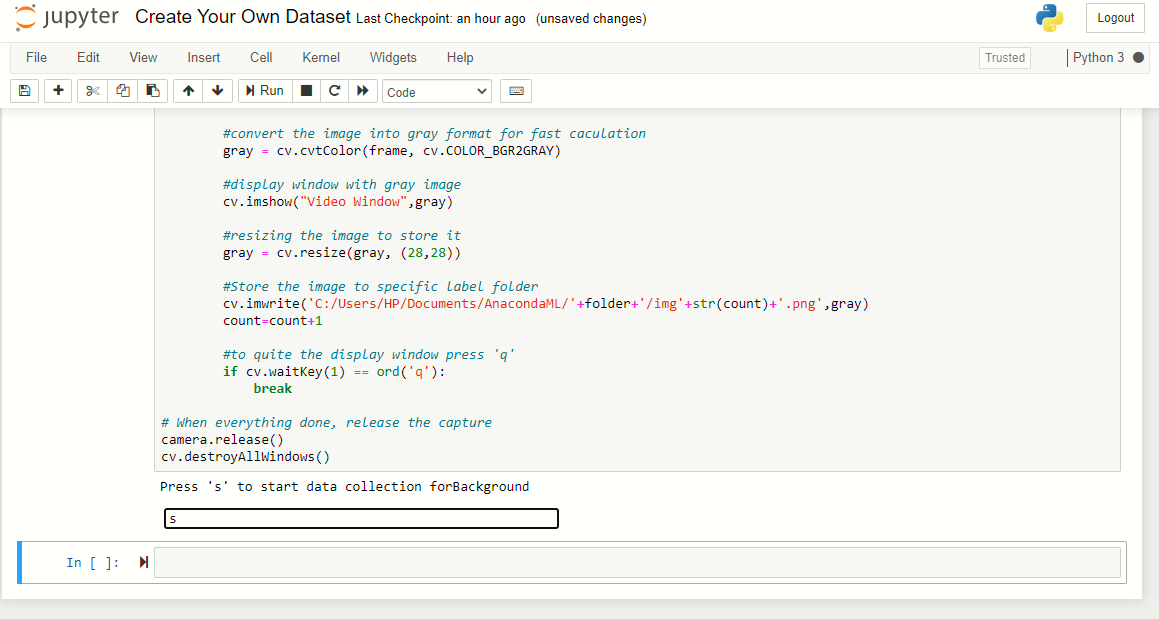
Depois de pressionar 's', Capturar 200 imagens de fundo. A janela de visualização aparecerá e começará a capturar as imagens, então saia do quadro e permita que a câmera capture o fundo.
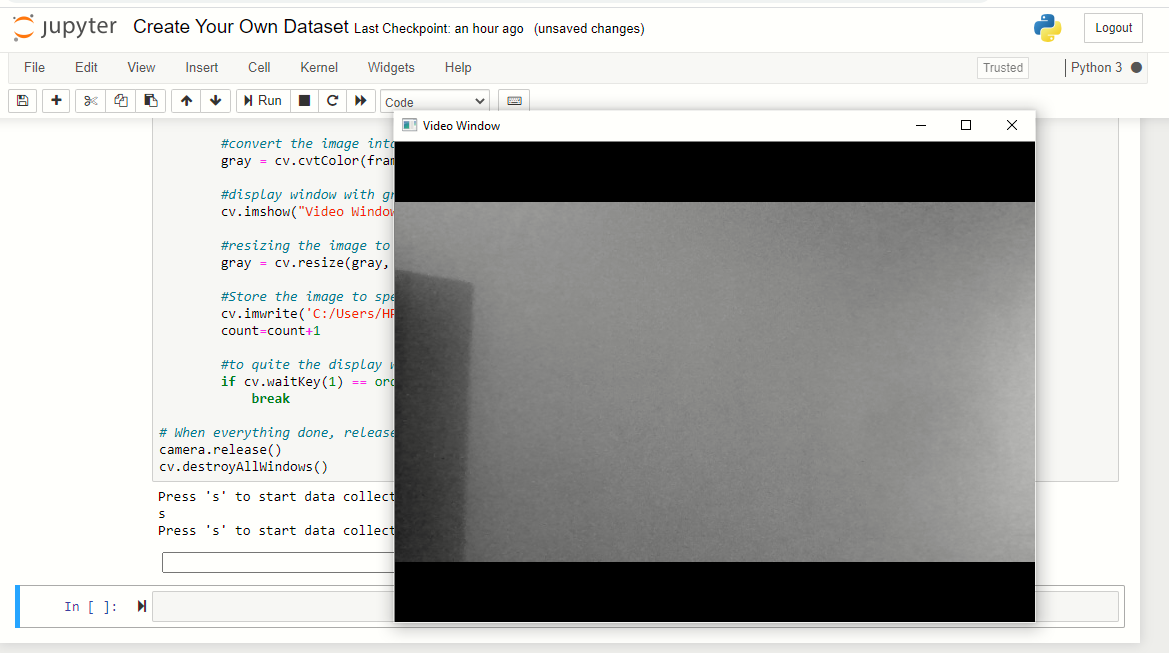
Agora, vai pedir 's’ e capturar imagens de “pedra”. Então, fechar o punho e mostrá-lo para a câmera em várias posições.
Observação: basta mover a mão com o punho perto, não fixar a mão em uma posição para produzir um conjunto de dados bem rotulado.
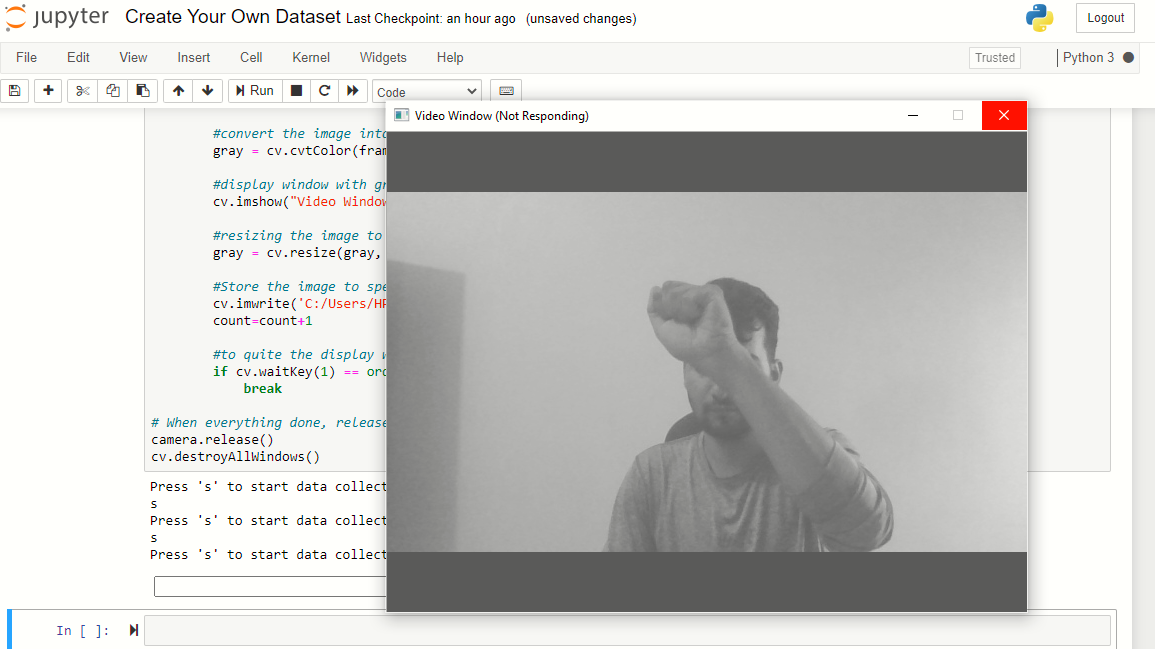
Agora, repetir o mesmo processo para imagens de papel e tesoura. Não se esqueça de pressionar’ quando solicitado, pelo contrário, ele vai parecer que a janela de exibição está presa, mas não é.
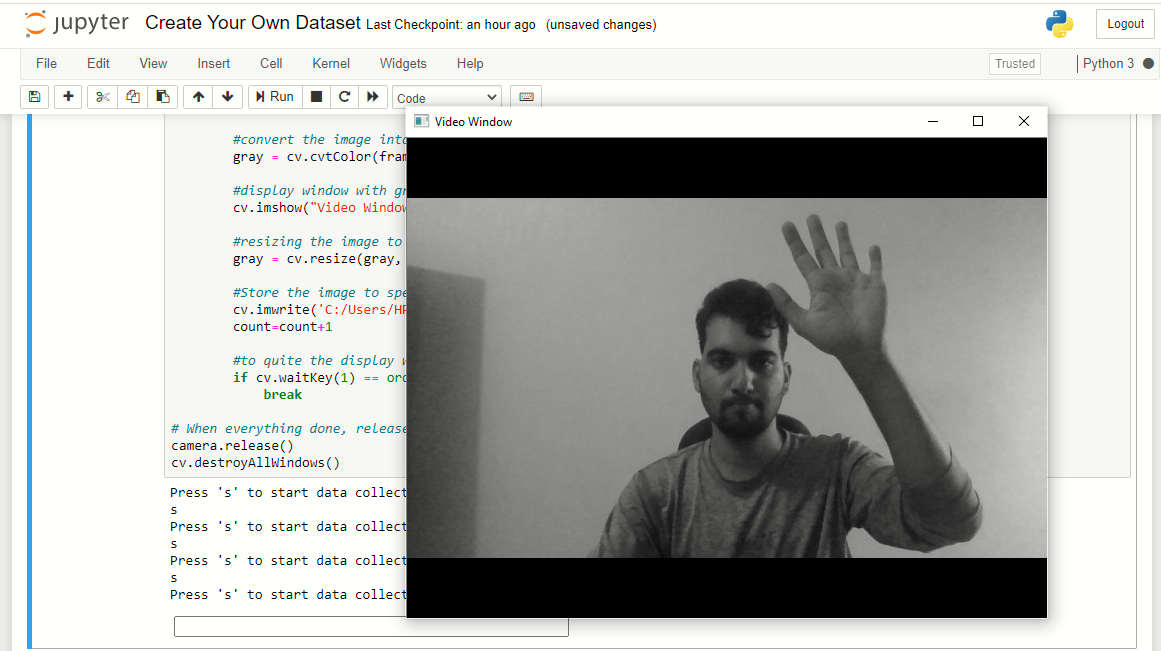
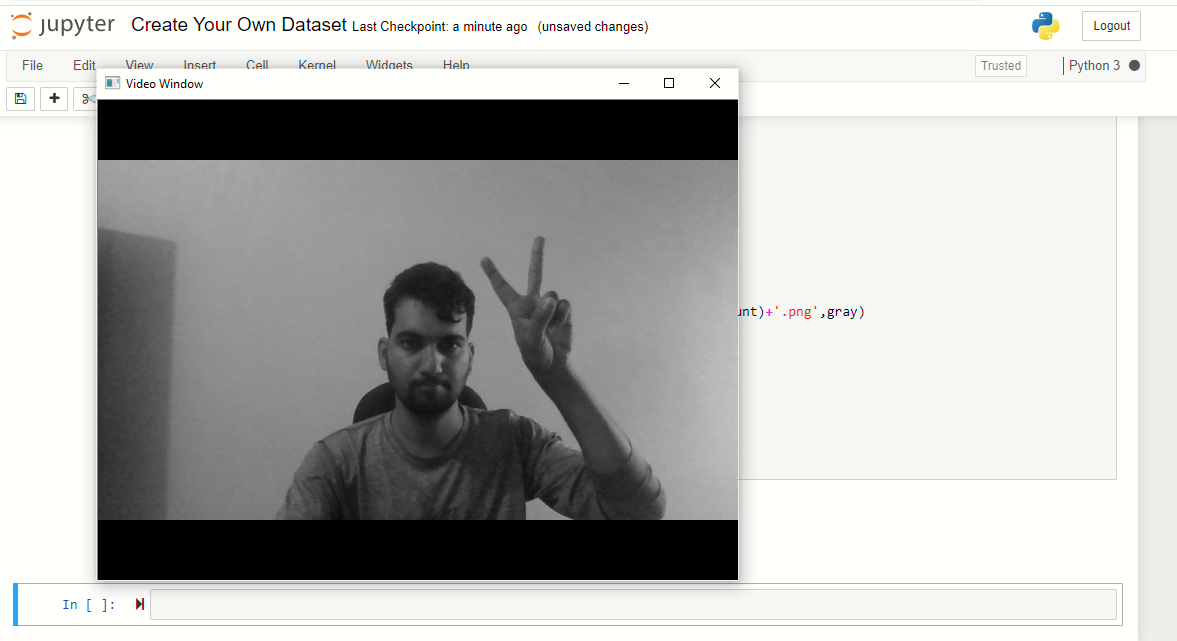
O programa fechará automaticamente. Agora você pode verificar navegando se o conjunto de dados foi criado ou não.
Observação: o conjunto de dados de imagem será criado no mesmo diretório onde o programa python é armazenado. quatro diretórios serão criados de acordo com o rótulo atribuído a eles.
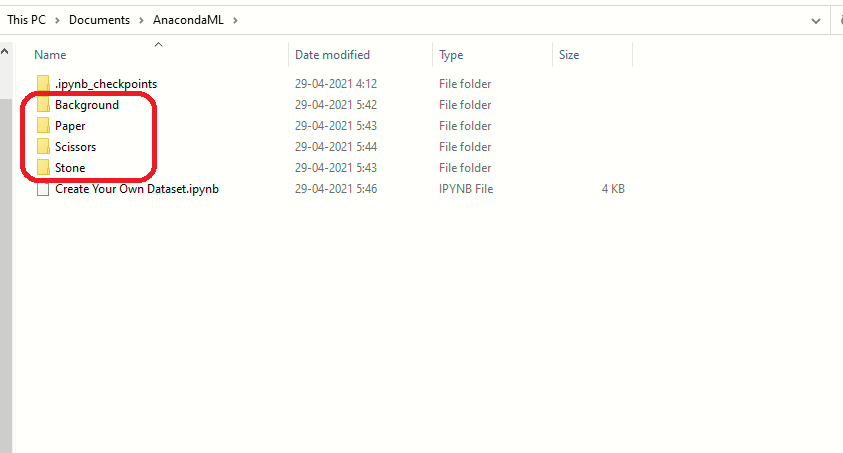
sim, pastas foram criadas com sucesso, agora verificar se as imagens foram capturadas e salvas. O tamanho da imagem não será o mesmo que o que você estava vendo durante o processo de captura. Reduzimos o tamanho da imagem para que, quando usado em um projeto de aprendizagem de máquina para treinar o modelo, requer menos recursos e tempo.
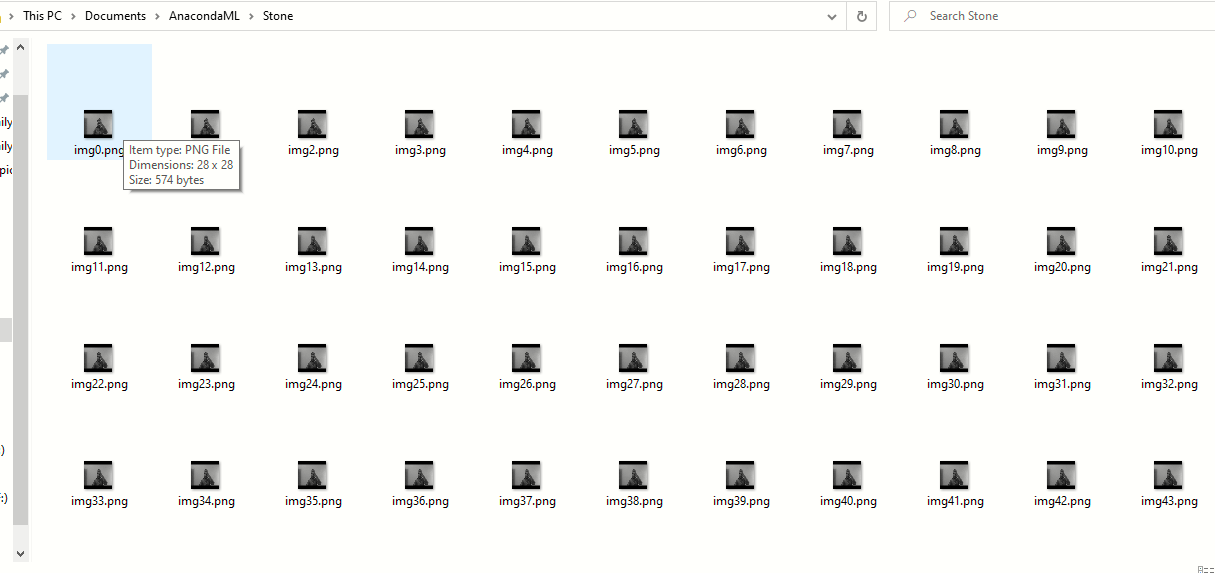
Viva! Criamos nosso próprio conjunto de dados de imagem que, O que mais, pode ser usado em projetos de aprendizado de máquina para classificação.





