O mundo da detecção de objetos
Eu amo trabalhar no espaço de aprendizado profundo. Francamente, é um vasto campo com uma infinidade de técnicas e estruturas para analisar e aprender. E a verdadeira emoção de modelar a visão computacional e o aprendizado profundo surge quando vejo aplicações do mundo real, como reconhecimento facial e rastreamento de bola no críquete., entre outras coisas.
E um dos meus conceitos favoritos de visão de máquina e aprendizado profundo é a detecção de objetos.. A capacidade de construir um modelo que pode passar por imagens e me dizer quais objetos estão presentes, É um sentimento inestimável!

Quando os humanos olham para uma imagem, reconhecemos o objeto de interesse em questão de segundos. Este não é o caso das máquinas. Portanto, a detecção de objetos é um problema de visão computacional para localizar instâncias de objetos em uma imagem.
Esta é a boa notícia: aplicativos de detecção de objetos estão mais fáceis de desenvolver do que nunca. As abordagens atuais se concentram no pipeline de ponta a ponta, que melhorou significativamente o desempenho e também ajudou a desenvolver casos de uso em tempo real.
Neste artigo, Vou mostrar como construir um modelo de detecção de objetos usando a popular API TensorFlow. Se você é um iniciante no aprendizado profundo, visão computacional e o mundo da detecção de objetos, Eu recomendo que você consulte os seguintes recursos:
Tabela de conteúdo
- Uma estrutura geral para detecção de objetos
- O que é uma API? Por que precisamos de uma API?
- API TensorFlow Object Detection
Uma estrutura geral para detecção de objetos
Normalmente, seguimos três etapas ao criar uma estrutura de detecção de objeto:
- Primeiro, um algoritmo ou modelo de aprendizado profundo é usado para gerar um grande conjunto de caixas delimitadoras que abrangem toda a imagem (quer dizer, um componente localizador de objetos)

- A seguir, características visuais são extraídas para cada uma das caixas delimitadoras. Eles são avaliados e é determinado se e quais objetos estão presentes nas caixas com base nas características visuais (quer dizer, um componente de classificação de objeto)

- Na última etapa de pós-processamento, caixas sobrepostas são combinadas em uma única caixa delimitadora (quer dizer, supressão não máxima)




Isso é tudo, Você está pronto com sua primeira estrutura de detecção de objetos!
O que é uma API? Por que precisamos de uma API?
API significa Interface de Programação de Aplicativos. Uma API fornece aos desenvolvedores um conjunto de operações comuns para que eles não tenham que escrever código do zero.
Pense em uma API como um menu de restaurante que fornece uma lista de pratos junto com uma descrição de cada prato. Quando especificamos qual prato queremos, o restaurante faz o trabalho e nos fornece pratos prontos. Não sabemos exatamente como o restaurante prepara aquela comida, e realmente não é necessário.
De algum modo, APIs economizam muito tempo. Eles também oferecem conveniência aos usuários em muitos casos. Pense nisso: Usuários do Facebook (incluindo eu!) Eles apreciam a capacidade de fazer login em muitos aplicativos e sites usando seu ID do Facebook. Como você acha que isso funciona?? Usando as APIs do Facebook, claro!
Então, neste artigo, veremos a API TensorFlow desenvolvida para a tarefa de detecção de objetos.
API TensorFlow Object Detection
A TensorFlow Object Detection API é a estrutura para a criação de uma rede de aprendizado profundo que resolve problemas de detecção de objetos.
Já existem modelos previamente treinados em sua estrutura, que são referidos como Model Zoo. Isso inclui uma coleção de modelos previamente treinados e treinados no conjunto de dados COCO., o conjunto de dados KITTI e o conjunto de dados de imagem aberta. Esses modelos podem ser usados para inferências se estivermos interessados em categorias apenas neste conjunto de dados.
Eles também são úteis para inicializar seus modelos ao treinar no novo conjunto de dados. As várias arquiteturas usadas no modelo pré-treinado são descritas nesta tabela:

MobileNet-SSD
A arquitetura SSD é uma rede de convolução única que aprende a prever os locais da caixa delimitadora e a classificar esses locais em uma única passagem. Portanto, SSD pode ser treinado ponta a ponta. A rede SSD consiste em uma arquitetura básica (MobileNet neste caso) seguido por várias camadas de convolução:

SSD opera em mapas de recursos para detectar a localização de caixas delimitadoras. Lembrar: um mapa de feições tem o tamanho Df * Df * M. Para cada local no mapa de recursos, k caixas delimitadoras são previstas. Cada caixa delimitadora carrega consigo as seguintes informações:
- Caixa delimitadora 4 cantos compensar Localizações (cx, cy, C, h)
- Probabilidades de classe C (c1, c2, ... cp)
SSD não prever a forma da caixa, ao invés, onde está a caixa. Cada uma das k caixas delimitadoras tem uma forma padrão. Os formulários são definidos antes do treinamento real. Por exemplo, na figura anterior, existem 4 casillas, o que significa k = 4.
Perda no MobileNet-SSD
Com o conjunto final de quadrados emparelhados, podemos calcular a perda desta forma:
L = 1 / N (Classe L + Caixa L)
Aqui, N é o número total de caixas emparelhadas. A classe L é a perda softmax para a classificação e a 'caixa L’ é a perda suave L1 que representa o erro das caixas emparelhadas. A perda suave L1 é uma modificação da perda L1 que é mais robusta para outliers. No caso de N ser 0, perda também é definida para 0.
MobileNet
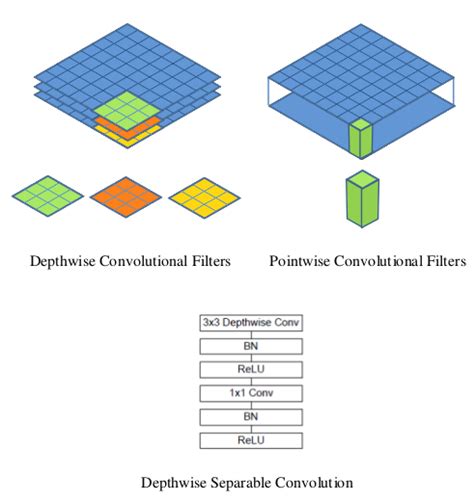
O modelo MobileNet é baseado em convoluções separáveis em profundidade, que são uma forma de convoluções fatoradas. Estes fatoram uma convolução padrão em uma convolução profunda e uma convolução de 1 × 1 chamado de convolução de ponto.
Para MobileNets, convolução de profundidade aplica um único filtro a cada canal de entrada. A convolução de pontos então aplica uma convolução 1 × 1 para combinar as saídas da convolução em profundidade.
Uma convolução padrão filtra e combina entradas em um novo conjunto de saídas em uma única etapa. Convolução separável em profundidade divide isso em duas camadas: uma camada separada para filtrar e uma camada separada para combinar. Essa fatoração tem o efeito de reduzir drasticamente o cálculo e o tamanho do modelo..
Como carregar o modelo?
Abaixo está o processo passo a passo a seguir no Google Colab para que você possa visualizar facilmente a detecção de objetos. Você também pode seguir o código.
Instale o modelo
Assegure-se de ter pycocotools instalado:
Pegue tensorflow/models o cd para o diretório principal do repositório:
Crie protobufs e instale o object_detection pacote:
Importe as bibliotecas necessárias
Importar o módulo de detecção de objetos:
Preparação de modelo
Carregador
Carregando mapa de etiqueta
Rotule mapas de índice de mapas com nomes de categorias para que, quando nossa rede de convolução preveja 5, deixe-nos saber que isso corresponde a um avião:
Por uma questão de simplicidade, vamos testar em 2 imagens:
Modelo de detecção de objetos usando a API TensorFlow
Carregar um modelo de detecção de objeto:
Verifique a assinatura de entrada do modelo (espere um lote de imagens de 3 cores do tipo int8):
Adicione uma função de wrapper para chamar o modelo e limpar as saídas:
Execute-o em cada imagem de teste e exiba os resultados:
Abaixo está o exemplo de imagem testado em ssd_mobilenet_v1_coco (MobileNet-SSD habilitado no conjunto de dados COCO):

Home-SSD
A arquitetura do modelo Inception-SSD é semelhante à do MobileNet-SSD anterior. A diferença é que a arquitetura básica aqui é o modelo Inception. Para saber mais sobre a rede doméstica, Vai aqui: Compreender a rede de inicialização do zero.
Como carregar o modelo?
Basta alterar o nome do modelo na parte de descoberta da API:
Mais tarde, fazer a previsão seguindo as etapas que seguimos acima. ¡Voila!
RCNN mais rápido
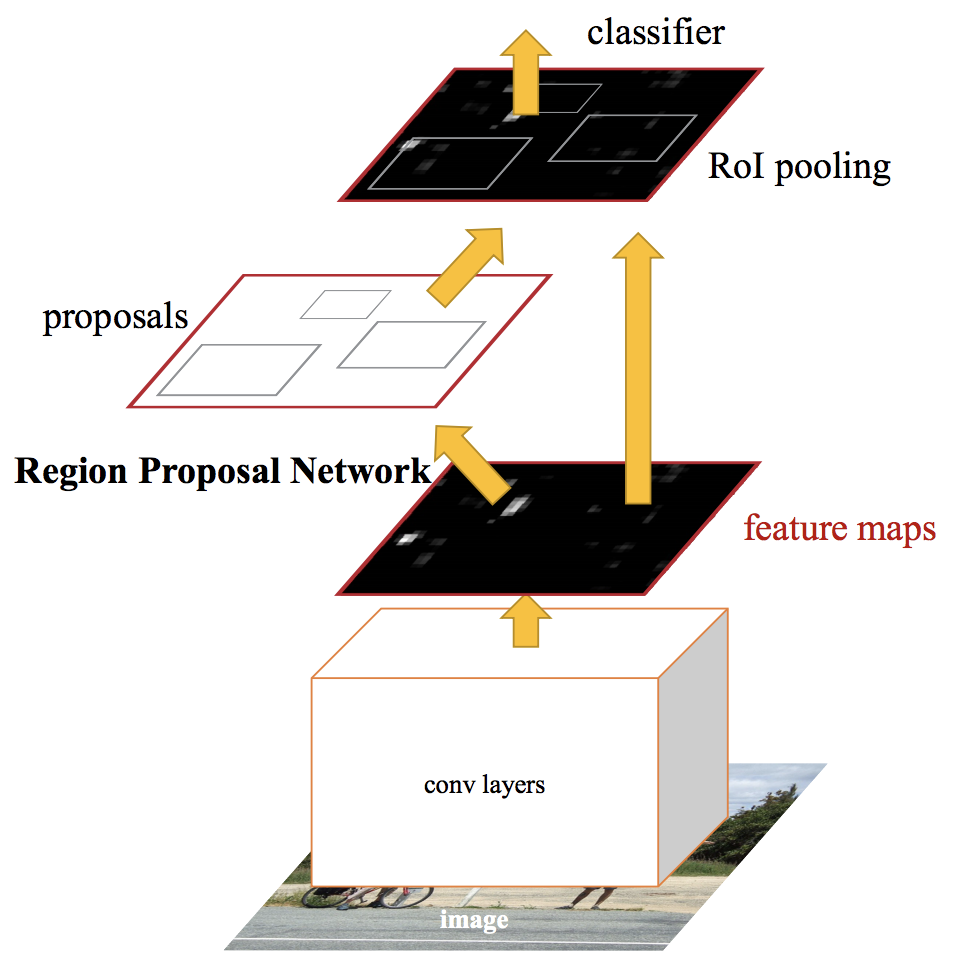
Redes de detecção de objetos de última geração contam com algoritmos de proposição de região para formular hipóteses sobre a localização de objetos. Avanços como SPPnet e Fast R-CNN reduziram o tempo de execução dessas redes de detecção, expondo o cálculo da proposta da região como um gargalo.
Um RCNN mais rápido, alimentamos a imagem de entrada para a rede neural convolucional para gerar um mapa de características convolucionais. Do mapa de características convolucionais, identificamos a região das propostas e as deformamos em quadrados. E ao usar uma camada de agrupamento de RoI (região de camada de interesse), nós os remodelamos em um tamanho fixo para que caibam em uma camada totalmente conectada.
Do vetor de recursos RoI, usamos uma camada softmax para prever a classe da região proposta e também os valores de deslocamento para a caixa delimitadora.
Para ler mais sobre o Faster RCNN, leia este artigo incrível – Uma implementação prática do algoritmo Faster R-CNN para detecção de objetos (Papel 2 – com códigos Python).
Como carregar o modelo?
Basta alterar o nome do modelo na parte de descoberta da API novamente:
Mais tarde, fazer a previsão seguindo os mesmos passos que seguimos anteriormente. Abaixo está a imagem de exemplo quando fornecida a um modelo RCNN mais rápido:

Como você pode ver, isso é muito melhor do que o modelo SSD-Mobilenet. Mas isso vem com uma compensação: é muito mais lento que o modelo anterior. Esses são os tipos de decisões que você precisará tomar ao escolher o modelo de detecção de objetos certo para seu projeto de aprendizado profundo e visão computacional..
Qual modelo de detecção de objeto devo escolher?
Dependendo de seus requisitos específicos, você pode escolher o modelo correto da API TensorFlow. Se quisermos um modelo de alta velocidade que possa trabalhar na detecção da transmissão de vídeo em fps altos, a rede de detecção de tiro único (SSD) funciona melhor. Como o próprio nome sugere, A rede SSD determina todas as probabilidades da caixa delimitadora de uma vez; por tanto, é um modelo muito mais rápido.
Porém, com detecção de tiro único, ganhe velocidade ao custo da precisão. Con FasterRCNN, obteremos alta precisão, mas baixa velocidade. Portanto, explore e no processo, você vai perceber o quão poderosa esta API TensorFlow pode ser.





