Visão geral
- A engenharia de recursos na PNL é sobre a compreensão do contexto do texto.
- Neste blog, veremos alguns dos recursos comuns de engenharia da PNL.
- Iremos comparar os resultados de uma tarefa de classificação com e sem a execução de engenharia de recursos.
Tabela de conteúdos
- Introdução
- Visão geral da tarefa de PNL
- Lista de recursos com código
- Implementação
- Comparação de resultados com e sem engenharia de função
- conclusão
Introdução
“Se ele 80 por cento do nosso trabalho é preparação de dados, garantir a qualidade dos dados é o trabalho importante de uma equipe de aprendizado de máquina”. – Andrew Ng

A engenharia de funções é uma das etapas mais importantes no aprendizado de máquina. É o processo de usar o conhecimento de domínio dos dados para criar características que fazem os algoritmos de aprendizado de máquina funcionarem.. Pense no algoritmo de aprendizado de máquina como uma criança que aprende; mais precisas são as informações que você fornece, mais eles serão capazes de interpretar bem as informações. Focar em nossos dados primeiro nos dará melhores resultados do que focar apenas em modelos. A engenharia de recursos nos ajuda a criar dados melhores que ajudam o modelo a entendê-los bem e fornecer resultados razoáveis.
PNL é um subcampo da inteligência artificial em que entendemos a interação humana com máquinas usando linguagens naturais. Para entender uma linguagem natural, é necessário entender como escrevemos uma frase, como expressamos nossos pensamentos usando palavras diferentes, sinais, caracteres especiais, etc., basicamente, devemos entender o contexto da frase para interpretar seu significado.
Se pudermos usar esses contextos como características e alimentá-los em nosso modelo, então o modelo será capaz de entender melhor a frase. Algumas das características comuns que podemos extrair de uma frase são o número de palavras, o número de palavras maiúsculas, o número da pontuação, o número de palavras únicas, o número de palavras vazias, o comprimento médio da frase, etc. Podemos definir essas características com base em nosso conjunto de dados que estamos usando. Neste blog, usaremos um conjunto de dados do Twitter para que possamos adicionar algumas outras características como o número de hashtags, a quantidade de menções, etc. Vamos discuti-los em detalhes nas próximas seções..
Visão geral da tarefa de PNL
Para entender a tarefa de engenharia de funções em PNL, vamos implementá-lo em um conjunto de dados do Twitter. Nós vamos usar Conjunto de dados de notícias falsas COVID-19. A tarefa é classificar o tweet como Falso o Verdade. O conjunto de dados é dividido em trem, validação e conjunto de teste. Abaixo está a distribuição,
| Separar | Verdade | Falso | Total |
| Trem | 3360 | 3060 | 6420 |
| Validação | 1120 | 1020 | 2140 |
| Teste | 1120 | 1020 | 2140 |
Lista de recursos
Vou listar um total de 15 recursos que podemos usar para o conjunto de dados acima, o número de recursos depende totalmente do tipo de conjunto de dados que você está usando.
1. Número de caracteres
Conte o número de caracteres presentes em um tweet.
def count_chars(texto):
return len(texto)
2. Número de palavras
Conte o número de palavras presentes em um tweet.
def count_words(texto):
return len(text.split())
3. Número de letras maiúsculas
Conte o número de caracteres maiúsculos presentes em um tweet.
def count_capital_chars(texto):
contagem = 0
para eu no texto:
se i.isupper():
contagem + = 1
contagem de retorno
4. Número de palavras maiúsculas
Conte o número de palavras maiúsculas presentes em um tweet.
def count_capital_words(texto):
soma de retorno(mapa(str.isupper,text.split()))
5. Conte o número de pontuações
Nesta função, nós devolvemos um dicionário de 32 sinais de pontuação com contagens, que podem ser usados como recursos autônomos, que discutirei na próxima seção.
def count_punctuations(texto):
pontuações ="!"#$%&"()*+,-./:;<=>[e-mail protegido][]^ _`{|}~ '
d = dict()
para i em pontuações:
d[str(eu)+' contar']= text.count(eu)
retorno d
6. Número de palavras entre aspas
O número de palavras entre aspas simples e aspas duplas.
def count_words_in_quotes(texto):
x = re.findall("'.'|"."", texto)
contagem = 0
se x for nenhum:
Retorna 0
outro:
para i em x:
t = i[1:-1]
count + = count_words
contagem de retorno
7. Número de sentenças
Conte o número de frases em um tweet.
def count_sent(texto):
return len(nltk.sent_tokenize(texto))
8. Conte o número de palavras únicas.
Conte o número de palavras únicas em um tweet.
def count_unique_words(texto):
return len(definir(text.split()))
9. Contagem de hashtag
Como estamos usando o conjunto de dados do Twitter, podemos contar quantas vezes os usuários usaram a hashtag.
def count_htags(texto):
x = re.findall(r '(#C[A-Za-z0-9]*)', texto)
return len(x)
10. Contagem de menções
E Twitter, na maioria das vezes as pessoas respondem ou mencionam alguém em seu tweet, contar o número de menções também pode ser tratado como uma característica.
def count_mentions(texto):
x = re.findall(r '(@C[A-Za-z0-9]*)', texto)
return len(x)
11. Contagem de palavras vazias
Aqui, contaremos o número de palavras irrelevantes usadas em um tweet.
def count_stopwords(texto):
stop_words = set(stopwords.words('inglês'))
word_tokens = word_tokenize(texto)
stopwords_x = [w para w em word_tokens if w em stop_words]
return len(stopwords_x)
12. Calcule o comprimento médio das palavras
Isso pode ser calculado dividindo o número de caracteres pelo número de palavras.
df['avg_wordlength'] = df['char_count']/df['word_count']
13. Cálculo da duração média das frases
Isso pode ser calculado dividindo a contagem de palavras pela contagem de frases.
df['avg_sentlength'] = df['word_count']/df['sent_count']
14. palavras únicas vs função de contagem de palavras
Esta característica é basicamente a proporção de palavras únicas para um número total de palavras.
df['unique_vs_words'] = df['unique_word_count']/df['word_count']
15. Parar a contagem de palavras vs. função de contagem de palavras
Essa característica também é a relação entre o número de palavras de parada e o número total de palavras.
df['stopwords_vs_words'] = df['stopword_count']/df['word_count']
Implementação
Você pode baixar o conjunto de dados em aqui. Após o download, podemos começar a implementar todas as funções que definimos acima. Vamos nos concentrar mais na engenharia de funções, para isso, vamos manter a abordagem simples, usando TF-IDF e pré-processamento simples. Todo o código estará disponível no meu repositório GitHub https://github.com/ahmadkhan242/Feature-Engineering-in-NLP.
-
Leitura de trem, validação e teste de suíte com pandas.
train = pd.read_csv("train.csv") val = pd.read_csv("validação.csv") test = pd.read_csv(testWithLabel.csv") # Para esta tarefa, combinaremos o conjunto de dados de treinamento e validação e, em seguida, usaremos # simples teste de trem dividido de sklern. df = pd.concat([Comboio, val]) df.head()
-
Aplicar extração de recursos previamente definidos no trem e no conjunto de teste.
df['char_count'] = df["tweet"].Aplique(lambda x:count_chars(x)) df['word_count'] = df["tweet"].Aplique(lambda x:count_words(x)) df['sent_count'] = df["tweet"].Aplique(lambda x:count_sent(x)) df['capital_char_count'] = df["tweet"].Aplique(lambda x:count_capital_chars(x)) df['capital_word_count'] = df["tweet"].Aplique(lambda x:count_capital_words(x)) df['quoted_word_count'] = df["tweet"].Aplique(lambda x:count_words_in_quotes(x)) df['stopword_count'] = df["tweet"].Aplique(lambda x:count_stopwords(x)) df['unique_word_count'] = df["tweet"].Aplique(lambda x:count_unique_words(x)) df['htag_count'] = df["tweet"].Aplique(lambda x:count_htags(x)) df['menção_contagem'] = df["tweet"].Aplique(lambda x:count_mentions(x)) df['punct_count'] = df["tweet"].Aplique(lambda x:count_punctuations(x)) df['avg_wordlength'] = df['char_count']/df['word_count'] df['avg_sentlength'] = df['word_count']/df['sent_count'] df['unique_vs_words'] = df['unique_word_count']/df['word_count'] df['stopwords_vs_words'] = df['stopword_count']/df['word_count'] # SIMILARMENTE, VOCÊ PODE APLICÁ-LOS NO CONJUNTO DE TESTE
-
dding alguns recursos adicionais usando contagem de pontuação
Iremos criar um DataFrame a partir do dicionário retornado pela função "punct_count" e então iremos fundi-lo com o conjunto de dados principal.
df_punct = pd.DataFrame(Lista(df.punct_count)) test_punct = pd.DataFrame(Lista(test.punct_count)) # Mesclando o DataFrame de pontuação com o DataFrame principal df = pd.merge(df, df_punct, left_index = True, right_index = True) test = pd.merge(teste, test_punct,left_index = True, right_index = True)
# Podemos largar "punt_count" coluna de df e teste DataFrame df.drop(colunas =['punct_count'],inplace = True) test.drop(colunas =['punct_count'],inplace = True) df.columns
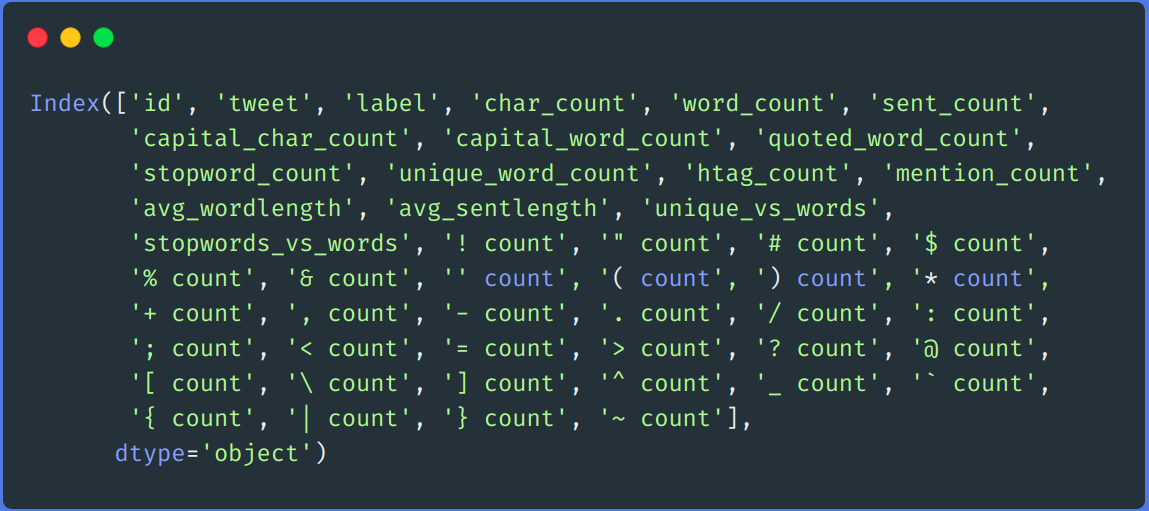
-
reprocessamento
Realizamos uma etapa simples antes do processamento, como remover links, remover nome de usuário, números, Espaço duplo, pontuação, minúsculas, etc.
def remove_links(tweet): '' 'Pega uma string e remove links da web dela' '' tweet = re.sub(r'httpS + ', '', tweet) # remover links http tweet = re.sub(r'bit.ly / S + ', '', tweet) # rempve bitly links tweet = tweet.strip('https://www.analyticsvidhya.com/blog/2021/04/a-guide-to-feature-engineering-in-nlp/ ') # retirar [links] tweet de retorno def remove_users(tweet): '' 'Pega uma string e remove retweetar e informações de @ usuário' '' tweet = re.sub('([e-mail protegido][A-Za-z]+[A-Za-z0-9-_]+)', '', tweet) # remover retuíte tweet = re.sub('(@[A-Za-z]+[A-Za-z0-9-_]+)', '', tweet) # remover tweetado em tweet de retorno my_punctuation = '!"$%&'()*+,-./:;<=>?[]^ _`{|}~ • @ ' pré-processo def(enviei): enviado = remove_users(enviei) enviado = remove_links(enviei) enviado = enviado.lower() # minúsculas enviado = re.sub('['+ minha_punctuação + ']+', '', enviei) # tira de pontuação enviado = re.sub('s +', '', enviei) #remova o espaçamento duplo enviado = re.sub('([0-9]+)', '', enviei) # remover números sent_token_list = [palavra por palavra em enviado.('')] enviado =" ".Junte(sent_token_list) retorno enviado df['tweet'] = df['tweet'].Aplique(lambda x: pré-processamento(x)) teste['tweet'] = teste['tweet'].Aplique(lambda x: pré-processamento(x))
-
Codificação de texto
Codificaremos nossos dados de texto usando TF-IDF. Primeiro ajustamos a transformação em nossa coluna de tweet de trem e conjunto de teste e, em seguida, mesclamos com todas as colunas de recursos.
vectorizer = TfidfVectorizer() train_tf_idf_features = vectorizer.fit_transform(df['tweet']).arranjar() test_tf_idf_features = vectorizer.transform(teste['tweet']).arranjar() # Convertendo a lista acima em DataFrame train_tf_idf = pd.DataFrame(train_tf_idf_features) test_tf_idf = pd.DataFrame(test_tf_idf_features) # Saparating trem e etiquetas de teste de todos os recursos train_Y = df['rótulo'] test_Y = teste['rótulo'] #Listando todos os recursos recursos = ['char_count', 'word_count', 'sent_count', 'capital_char_count', 'capital_word_count', 'quoted_word_count', 'stopword_count', 'unique_word_count', 'htag_count', 'menção_contagem', 'avg_wordlength', 'avg_sentlength', 'unique_vs_words', 'stopwords_vs_words', '! contar', '" contar', '# contar', '$ count', '% contar', '& contar', '' contar', '( contar', ') contar', '* contar', '+ contagem', ', contar', '- contar', '. contar', '/ contar', ': contar', '; contar', '< contar', '= contar', '> contar', '? contar', '@ contar', '[ contar', ' contar', '] contar', '^ contagem', '_ contar', '' contar ', '{ contar', '| contar', '} contar', '~ contar'] # Finalmente mesclando todos os recursos com o TF-IDF acima. train = pd.merge(train_tf_idf,df[recursos],left_index = True, right_index = True) test = pd.merge(test_tf_idf,teste[recursos],left_index = True, right_index = True) -
Treinamento
Para treinamento, usaremos o algoritmo de floresta aleatório da biblioteca de aprendizagem sci-kit.
X_train, X_test, y_train, y_test = train_test_split(Comboio, train_Y, test_size = 0.2, random_state = 42) # Classificador Random Forest clf_model = RandomForestClassifier(n_estimators = 1000, min_samples_split = 15, random_state = 42) clf_model.ajuste(X_train, y_train) _RandomForestClassifier_prediction = clf_model.predict(X_test) val_RandomForestClassifier_prediction = clf_model.predict(teste)
Comparação de resultados
Para comparação, primeiro treinamos nosso modelo no conjunto de dados acima usando técnicas de engenharia de recursos e, em seguida, sem usar técnicas de engenharia de recursos. Em ambas as abordagens, nós pré-processamos o conjunto de dados usando o mesmo método descrito acima e TF-IDF foi usado em ambas as abordagens para codificar os dados de texto. Você pode usar qualquer técnica de codificação que desejar, como word2vec, luva, etc.
1. Sem usar técnicas de engenharia de funções
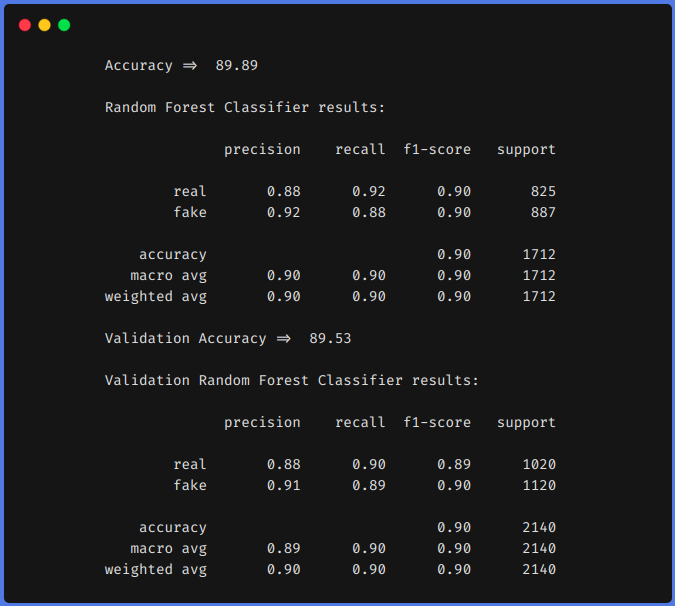
2. Uso de técnicas de engenharia de funções
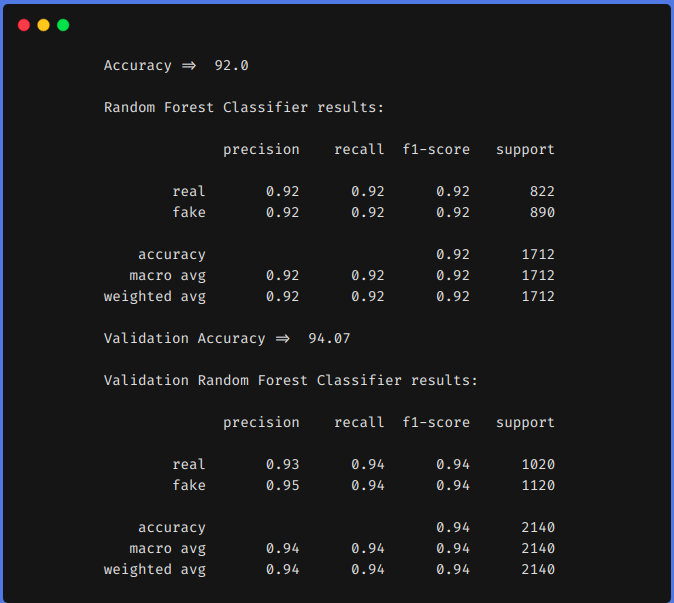
Dos resultados anteriores, podemos ver que as técnicas de engenharia de recursos nos ajudaram a aumentar nosso f1 a partir de 0,90 até 0,92 no trem e de 0,90 até 0,94 na equipe de teste.
conclusão
Os resultados acima mostram que se realizarmos a engenharia de funções, podemos alcançar maior precisão usando algoritmos clássicos de aprendizado de máquina. Usar um modelo baseado em transformador é um algoritmo demorado e que consome muitos recursos. Se funcionarmos a engenharia da maneira certa, quer dizer, depois de analisar nosso conjunto de dados, podemos obter resultados comparáveis.
Também podemos fazer alguma outra engenharia de recursos, como contar o número de emojis usados, o tipo de emojis usado, que frequências de palavras únicas, etc. Podemos definir nossas características analisando o conjunto de dados. Espero que você tenha aprendido algo com este blog, compartilhe com outros. Confira meu blog pessoal de aprendizado de máquina (https://code-ml.com/) para obter conteúdo novo e empolgante em diferentes domínios de ML e IA.
Sobre o autor
Mohammad Ahmad (B.Tech) LinkedIn - https://www.linkedin.com/in/mohammad-ahmad-ai/ Blog Pessoal - https://code-ml.com/ GitHub - https://github.com/ahmadkhan242 Twitter - https://twitter.com/ahmadkhan_242
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





