Este artigo foi publicado como parte do Data Science Blogathon
Introdução:
Extração de dados é o processo de extrair dados de várias fontes, como arquivos CSV, rede, PDF, etc. Embora em alguns arquivos, os dados podem ser facilmente extraídos como em CSV, enquanto em arquivos como PDF não estruturado, temos que realizar tarefas adicionais para extrair dados.
Existem algumas bibliotecas Python com as quais você pode extrair dados de arquivos PDF. Por exemplo, você pode usar o PyPDF2 biblioteca para extrair texto de arquivos PDF onde o texto é sequencial ou formatado, quer dizer, em linhas ou formas. Você também pode extrair tabelas para PDF por meio do Camelot Biblioteca. Em todos esses casos, os dados estão na forma estruturada, quer dizer, sequencial, formulários ou tabelas.
Porém, No mundo real, a maioria dos dados não está presente em nenhum dos formulários e não há ordem de dados. Está presente de forma não estruturada. Neste caso, não é viável usar as bibliotecas python acima, uma vez que eles darão resultados ambíguos. Para analisar dados não estruturados, precisamos convertê-los para uma forma estruturada.
Como tal, não há técnica ou procedimento específico para extrair dados de arquivos PDF não estruturados, já que os dados são armazenados aleatoriamente e dependem do tipo de dados que você deseja extrair do PDF.
Aqui, Vou mostrar a você uma técnica mais bem-sucedida e uma biblioteca Python por meio da qual você pode extrair dados de caixas delimitadoras em arquivos PDF não estruturados e, em seguida, execute a operação de limpeza de dados nos dados extraídos e converta-os em um formato estruturado.
PyMuPDF:
Eu usei o PyMuPDF biblioteca para este propósito. Esta biblioteca forneceu muitos aplicativos, como extrair imagens de PDF, extrair textos de maneiras diferentes, faça anotações, desenhe uma caixa delimitadora ao redor dos textos junto com recursos de biblioteca como PyPDF2.
Agora, Vou mostrar como extraí dados de caixas delimitadoras em um PDF com várias páginas.
Aqui está o PDF e as caixas delimitadoras vermelhas de que precisamos para extrair os dados.
Eu tentei muitas bibliotecas python como PyPDF2, PDFMiner, luciopdf, Camelot y tabulado. Porém, nenhum deles funcionou, exceto PyMuPDF.
Antes de inserir o código, é importante entender o significado de 2 termos importantes que ajudariam você a entender o código.
Palavra: Sequência de caracteres sem espaços. Ex – cinza, 23, 2, 3.
Anotações: uma anotação associa um objeto como uma nota, uma imagem ou caixa delimitadora com uma localização em uma página de um documento PDF, ou fornece uma maneira de interagir com o usuário usando o mouse e o teclado. Os objetos são chamados de anotações.
tenha em conta que, no nosso caso, caixa delimitadora, anotações e retângulos são iguais. Por tanto, esses termos seriam usados indistintamente.
Primeiro, vamos extrair texto de uma das caixas delimitadoras. Em seguida, usaremos o mesmo procedimento para extrair dados de todas as caixas delimitadoras de pdf.
Código:
import fitz
import pandas as pd
doc = fitz.open('Mansfield--70-21009048 - ConvertToExcel.pdf')
page1 = doc[0]
palavras = page1.get_text("palavras")
Em primeiro lugar, importamos o Fitz módulo do PyMuPDF biblioteca panda e biblioteca. Mais tarde, o objeto do arquivo pdf é criado e armazenado no documento e a primeira página do pdf é armazenada na página 1. page.get_text () extrai todas as palavras da página 1. Cada palavra consiste em uma tupla com 8 elementos.
Em palavras variáveis, o primeiro 4 elementos representam as coordenadas da palavra, o quinto elemento é a própria palavra, o sexto, sétimo, oito elementos são números de blocos, linha e palavra, respectivamente.
PRODUÇÃO
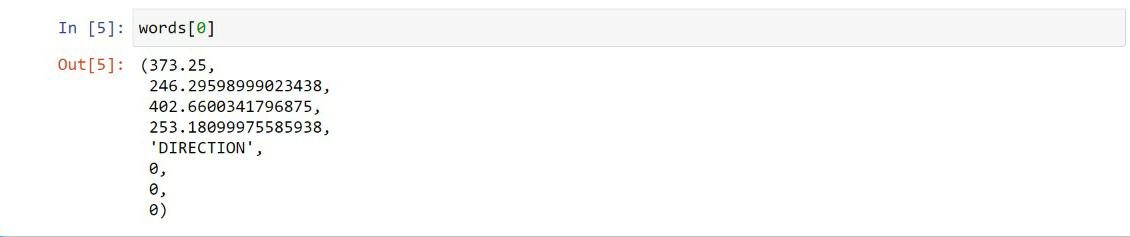
Extrai as coordenadas do primeiro objeto:
first_annots=[]
rec=page1.first_annot.rect
rec
#Information of words in first object is stored in mywords
mywords = [w para w em palavras se fitz. Rect(C[:4]) em rec]
ann= make_text(mywords)
first_annots.append(Ann)
Esta função seleciona as palavras contidas na caixa, classifica as palavras e retorna na forma de uma cadeia:
def make_text(palavras):
line_dict = {}
palavras.classificar(key=lambda w: C[0])
para w em palavras:
y1 = rodada(C[3], 1)
palavra = w[4]
linha = line_dict.get(e1, [])
line.append(palavra)
line_dict[e1] = line
lines = list(line_dict.itens())
linhas.classificar()
Retorna "n".Junte([" ".Junte(linha[1]) para linha em linhas])
PRODUÇÃO

page.first_annot () dá a primeira anotação, quer dizer, a caixa delimitação na página.
.reto dá as coordenadas de um retângulo.
Agora, temos as coordenadas do retângulo e todas as palavras na página. Em seguida, filtramos as palavras que estão presentes em nossa caixa delimitadora e as armazenamos em minhas palavras variável.
Temos todas as palavras do retângulo com suas coordenadas. Porém, essas palavras estão em ordem aleatória. Como precisamos do texto sequencialmente e isso só faz sentido, usamos uma função make_text () que primeiro ordena as palavras da esquerda para a direita e depois de cima para baixo. Retorna o texto em formato de string.
Viva! Extraímos dados de um comentário. Nossa próxima tarefa é extrair dados de todas as anotações em pdf, o que seria feito com a mesma abordagem.
Extraindo cada página do documento e todas as anotações / rectanges:
para pageno no intervalo(0,len(doc)-1):
página = doc[pageno]
palavras = page.get_text("palavras")
para anotar em page.anos():
se annot!= Nenhum:
rec=annot.rect
mywords = [w para w em palavras se fitz. Rect(C[:4]) em rec]
ann= make_text(mywords)
all_annots.append(Ann)
all_annots, uma lista é inicializada para armazenar o texto de todas as anotações no pdf.
A função do ciclo externo no código acima é atravessar cada página do PDF, enquanto o do loop interno é revisar todas as anotações na página e realizar a tarefa de adicionar textos à lista all_annots conforme discutido acima.
Imprimir all_annots nos dá o texto de todas as anotações do pdf que você pode ver abaixo.
PRODUÇÃO
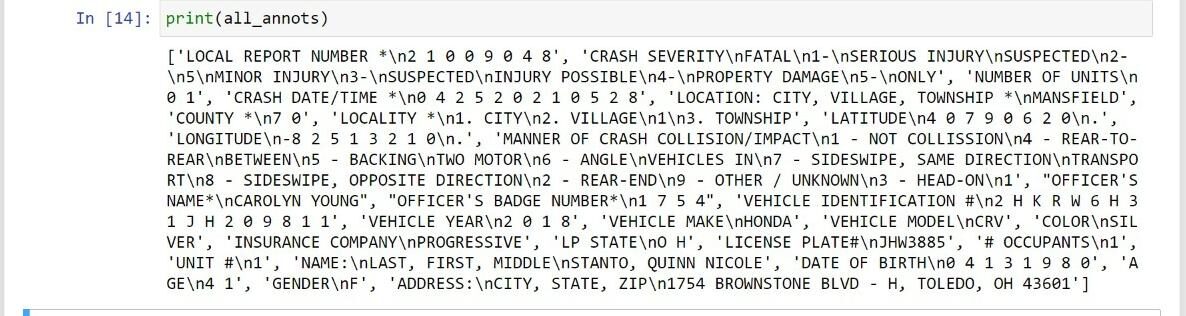
Finalmente, nós extraímos os textos de todas as anotações / caixas delimitadoras.
É hora de limpar os dados e trazê-los de uma forma compreensível.
Limpeza e processamento de dados
Dividindo para formar o nome da coluna e seus valores:
cont =[]
para eu no alcance(0,len(all_annots)):
cont.append(all_annots[eu].dividir('n',1))
Remover símbolos desnecessários *, # ,:
liss=[]
para eu no alcance(0,len(Cont)):
lis=[]
para j em cont[eu]:
j=j.substituir('*','')
j=j.substituir('#','')
j=j.substituir(':','')
j=j.strip()
#imprimir(j)
lis.append(j)
liss.append(Lis)
Divida em chaves e valores e exclua espaços em valores que contêm apenas dígitos:
chaves=[]
valores =[]
para i em liss:
keys.append(eu[0])
values.append(eu[1])
para eu no alcance(0, len(valores)):
para j no intervalo(0,len(valores[eu])):
se valores[eu][j]>='A' e valores[eu][j]<='Z':
break
if j==len(valores[eu])-1:
valores[eu]=valores[eu].substituir('','')
Dividimos cada sequência de acordo com um novo caractere de linha (n) para separar o nome da coluna de seus valores. Limpando mais, símbolos desnecessários, como (*, #, 🙂. Espaços entre dígitos são removidos.
Com pares de valor-chave, criamos um dicionário mostrado abaixo:
Conversão para dicionário:
relatório=dict(fecho eclair(chaves,valores))
relatório['IDENTIFICAÇÃO DO VEÍCULO']= relatório['IDENTIFICAÇÃO DO VEÍCULO'].substituir(‘ ‘,”)
dec=[relatório['LOCALIDADE'],relatório['FORMA DE COLISÃO/IMPACTO DO ACIDENTE'],relatório['GRAVIDADE DO ACIDENTE']] l=0 val_after=[] para local em dic: li=[] lii=[] k='' extract="" l=0 for i in range(0,len(local)-1): se local[i+1]>='0' e local[i+1]<='9': li.append(local[eu:i+1]) l=i+1 li.append(local[eu:]) imprimir(no) para i em li: se eu[0] em lii: k=i[0] break lii.append(eu[0]) para i em li: se eu[0]==k:
extrato = me
val_after.append(extrair)
break
report['LOCALIDADE']=val_after[0]
relatório['FORMA DE COLISÃO/IMPACTO DO ACIDENTE']=val_after[1]
relatório['GRAVIDADE DO ACIDENTE']=val_after[2]
PRODUÇÃO
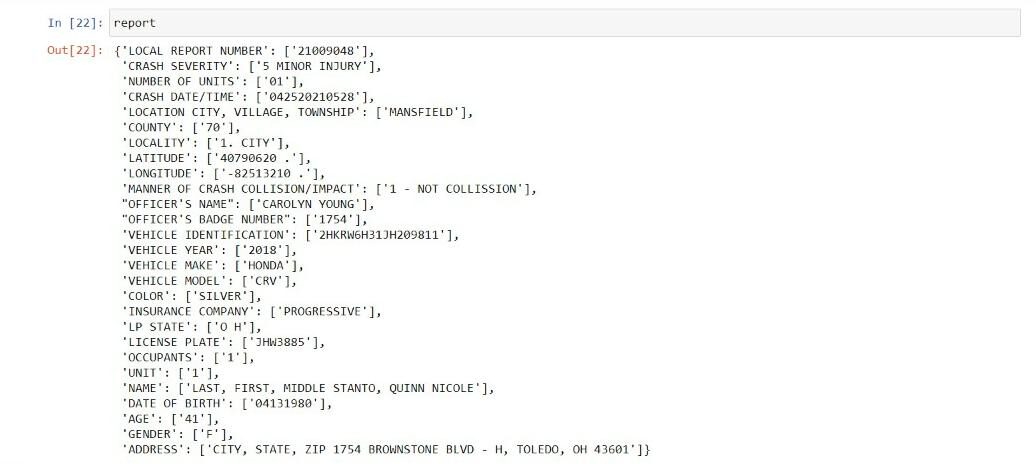
Por último, dicionário é convertido em data frame com a ajuda dos pandas.
Converter para DataFrame e exportar para CSV:
data = pd.DataFrame.from_dict(relatório)
data.to_csv('final.csv',index = False)
PRODUÇÃO
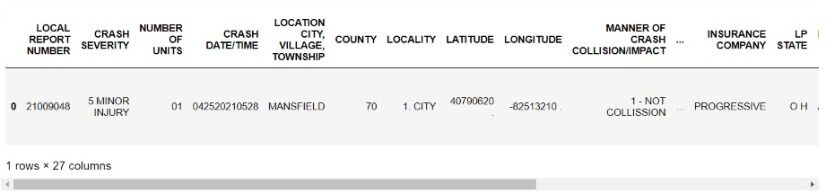
Agora, podemos realizar análises de nossos dados estruturados ou exportá-los para o Excel.
Espero que você tenha gostado de ler este blog e ele deu uma ideia de como lidar com dados não estruturados..
Referências:
Fonte da imagem em destaque: Python real https://realpython.com/python-data-engineer/
Documentação PyMuPDF: https://pymupdf.readthedocs.io/en/latest/
Sobre o autor:
Olá! Soy Ashish Choudhary. Estou estudando B.Tech da Universidade de Ciência e Tecnologia JC Bose. Ciência de dados é minha paixão e tenho orgulho de escrever blogs interessantes relacionados a ela. Não hesite em me contatar no Linkedin linkedin.com/in/ashish-choudhary-7b6029166.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





