Este artigo foi publicado como parte do Data Science Blogathon
Introdução
No processamento de linguagem natural, extração de recursos é uma das etapas triviais para entender melhor o contexto do que estamos lidando. Depois de limpar e normalizar o texto inicial, devemos transformá-lo em suas características para usá-lo na modelagem. Usamos algum método específico para atribuir pesos a palavras específicas em nosso documento antes de modelá-las. Optamos pela representação numérica de palavras individuais, já que é fácil para o computador processar números; em tais casos, optamos por embeddings de palavras.

Fonte: https://www.analyticsvidhya.com/blog/2020/06/nlp-project-information-extraction/
Neste artigo, Discutiremos os vários métodos de incorporação de palavras e extração de recursos que são praticados no processamento de linguagem natural..
Extração de recursos:
Saco de palavras:
Neste método, tomamos cada documento como uma coleção ou bolsa que contém todas as palavras. A ideia é analisar os documentos. O documento aqui se refere a uma unidade. Caso queiramos encontrar todos os tweets negativos durante a pandemia, cada tweet aqui é um documento. Para obter a bolsa de palavras, sempre realizamos todas as etapas anteriores, como a limpeza, derivação, lematización, etc ... Em seguida, geramos um conjunto de todas as palavras que estão disponíveis antes de enviá-lo para o modelo.
“A entrada é a melhor parte do futebol” -> {'entrada', 'Melhor', 'papel', 'futebol'}
Podemos obter palavras repetidas em nosso documento. Uma representação melhor é uma forma vetorial, que pode nos dizer quantas vezes cada palavra pode aparecer em um documento. O seguinte é chamado de matriz de termos de documento e é mostrado abaixo:

Fonte: https://qphs.fs.quoracdn.net/main-qimg-27639a9e2f88baab88a2c575a1de2005
Informa-nos sobre a relação entre um documento e os termos. Cada um dos valores da tabela se refere ao termo frequência. Para encontrar a semelhança, nós escolhemos a medida de similaridade do cosseno.
TF-IDF:
Um problema que encontramos com a abordagem do saco de palavras é que ela trata todas as palavras igualmente, mas em um documento, existe uma grande probabilidade de que certas palavras sejam repetidas com mais frequência do que outras. Em reportagem sobre a vitória de Messi na Copa América, a palavra Messi seria repetida com mais frequência. Não podemos dar a Messi o mesmo peso que qualquer outra palavra nesse documento. No relatório, se tomarmos cada frase como um documento, podemos contar o número de documentos cada vez que Messi aparece. Este método é chamado de frequência de documento.
Em seguida, dividimos a frequência do termo pela frequência do documento dessa palavra. Isso nos ajuda com a frequência de aparecimento de termos naquele documento e inversamente ao número de documentos em que ele aparece. Portanto, nós temos o TF-IDF. A ideia é atribuir pesos específicos às palavras que nos dizem o quão importante elas são no documento.
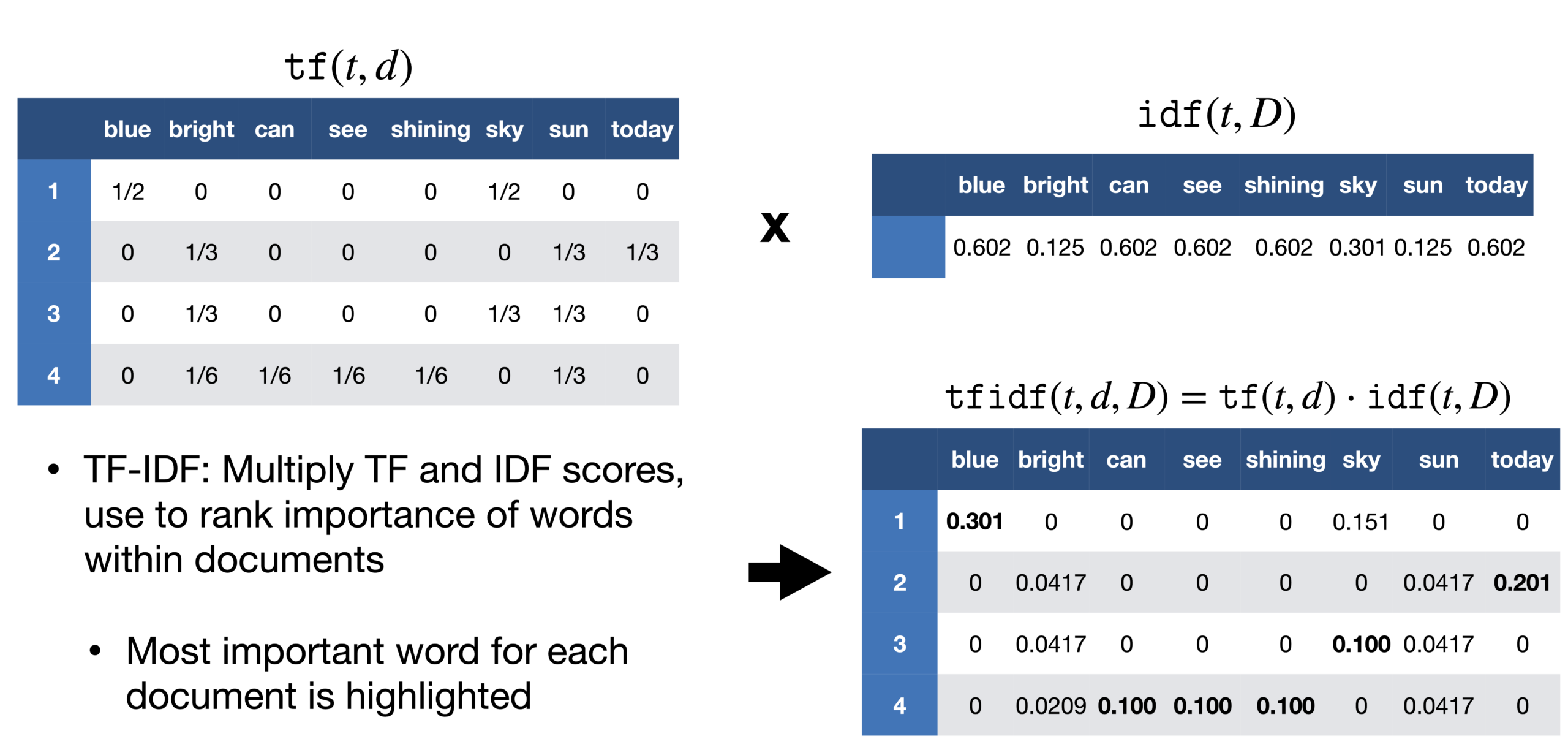
Fonte: https://sci2lab.github.io/ml_tutorial/tfidf/
Codificação one-hot:
Para uma melhor análise do texto que queremos processar, devemos criar uma representação numérica de cada palavra. Isso pode ser corrigido usando o método de codificação One-hot. Aqui, tratamos cada palavra como uma classe e em um documento, onde quer que a palavra esteja, nós atribuímos 1 na tabela e todas as outras palavras nesse documento são 0. Isso é semelhante ao saco de palavras, mas aqui nós apenas mantemos cada palavra em um saco.
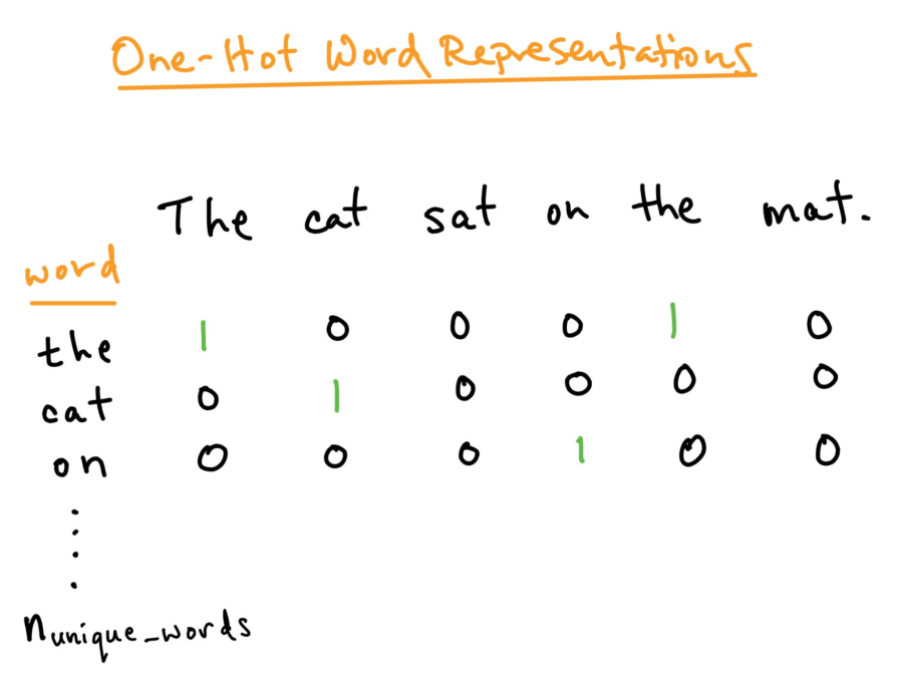
Fonte: https: //directiondatascience.com/word-embedding-in-nlp-one-hot-encoding-and-skip-gram-neural-network-81b424da58f2
Incorporação de palavras:
A codificação one-hot funciona bem quando temos um pequeno conjunto de dados. Quando há um grande vocabulário, podemos codificá-lo usando este método, pois a complexidade aumenta muito. Precisamos de um método que possa controlar o tamanho das palavras que representamos. Fazemos isso limitando-o a um vetor de tamanho fixo. Queremos encontrar um embutimento para cada palavra. Queremos que você nos mostre algumas propriedades. Por exemplo, se duas palavras são semelhantes, devem estar mais próximos uns dos outros em representação, e duas palavras opostas se seus pares existirem, ambos devem ter a mesma diferença de distância. Isso nos ajuda a encontrar sinônimos, analogias, etc.
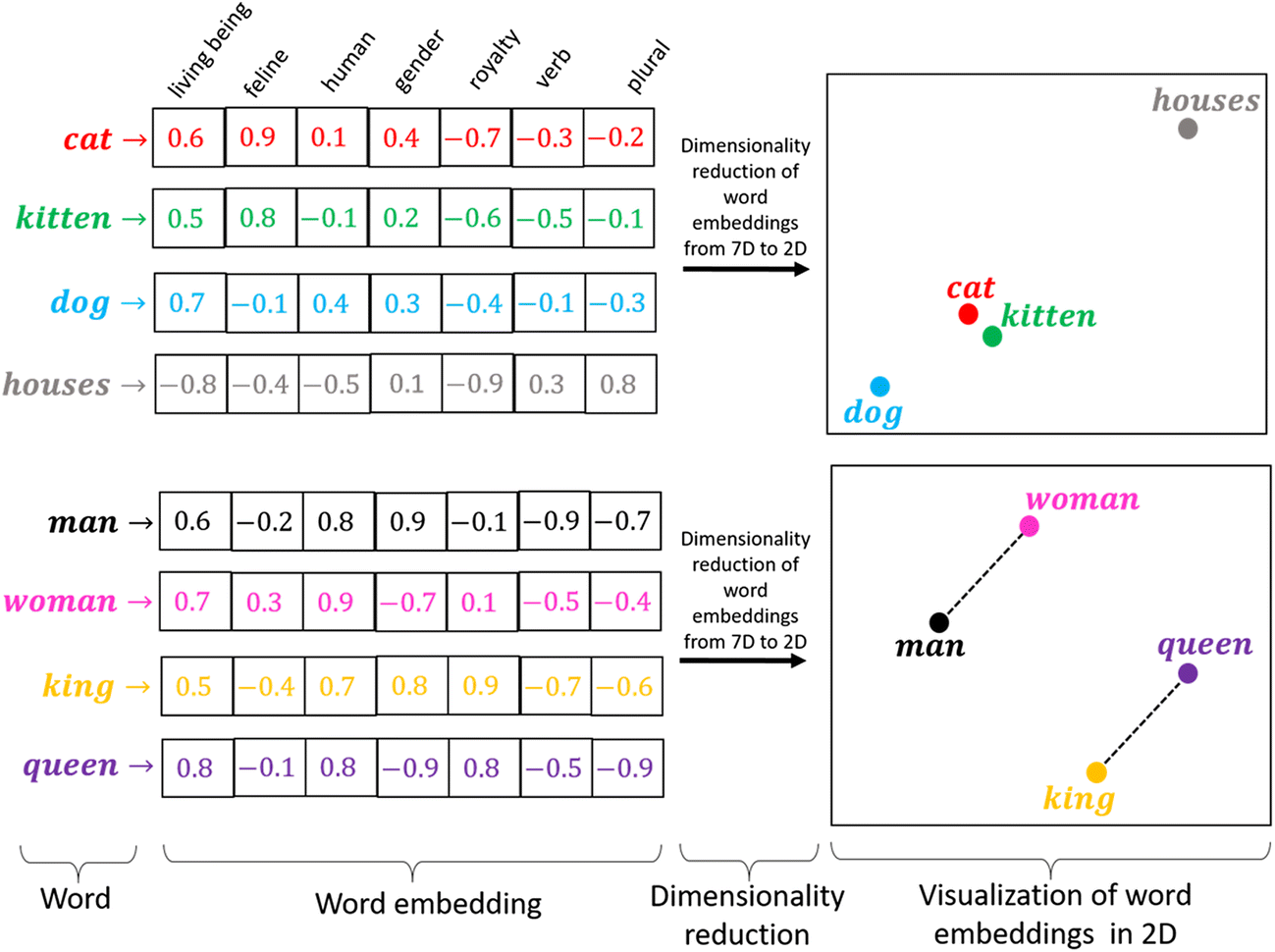
Fonte: https://miro.medium.com/max/1400/1*sAJdxEsDjsPMioHyzlN3_A.png
Word2Vec:
Word2Vec é amplamente utilizado na maioria dos modelos de PNL. Transforme a palavra em vetores. Word2vec é uma rede de duas camadas que processa texto com palavras. A entrada está no corpus do texto e a saída é um conjunto de vetores: os vetores de recursos representam as palavras nesse corpus. Embora Word2vec não seja uma rede neural profunda, converter texto em uma forma inequívoca de cálculo para redes neurais profundas. O objetivo e benefício do Word2vec é coletar vetores das mesmas palavras no espaço vetorial. Quer dizer, encontrar semelhanças matemáticas. Word2vec cria vetores que são distribuídos usando exibições numéricas de elementos de palavras, características como o contexto de palavras individuais. Faz isso sem intervenção humana.
Com dados suficientes, uso e condições, Word2vec pode fazer as previsões mais precisas sobre o significado de uma palavra com base em aparições anteriores. Essa conjectura pode ser usada para formar combinações de palavras e palavras (por exemplo, “grande”, quer dizer, "Grande" para dizer que "pequeno" é "minúsculo"), ou grupos de textos e separá-los por tópico. Essas coleções podem formar a base para a pesquisa, análise emocional e recomendações em vários campos, como pesquisa científica, descoberta legal, e-commerce e gestão de relacionamento com o cliente. O resultado da rede Word2vec é um glossário onde cada elemento tem um vetor anexado, que pode ser inserida em uma rede de leitura profunda ou apenas solicitada a encontrar a relação entre as palavras.
Word2Vec pode capturar o significado contextual das palavras muito bem. Existem dois sabores. Em um dos métodos, recebemos as palavras vizinhas chamadas saco contínuo de palavras (CBoW), e em que nos é dada a palavra do meio chamada skip-gram e prevemos as palavras vizinhas. Assim que obtivermos um conjunto de pesos previamente treinados, podemos salvá-lo e isso pode ser usado mais tarde para a vetorização de palavras sem a necessidade de transformar novamente. Nós os armazenamos em uma tabela de pesquisa.
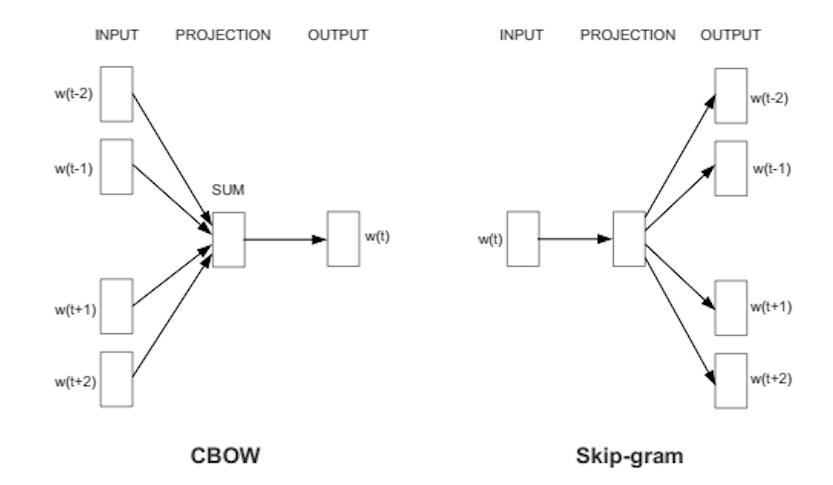
Fonte: https://wiki.pathmind.com/word2vec
Luva:
Luva – vetor global para representação de palavras. Um algoritmo de aprendizado não supervisionado de Stanford é usado para gerar palavras embutidas combinando uma matriz de palavras para a coocorrência de palavras da matriz do corpus.. O texto incorporado pop-up exibe uma formatação de linha atraente para uma palavra no espaço vetorial. O modelo GloVe é treinado na matriz global de coocorrência de nível zero, que mostra a frequência com que as palavras são encontradas em um determinado corpus. O preenchimento desta matriz requer uma passagem por corporação inteira para coletar estatísticas. Para um grande corpus, esta transação pode custar um computador, mas é uma despesa única no futuro. O treinamento pós-acompanhamento é muito mais rápido porque o número de entradas não matriciais geralmente é muito menor do que o número total de entradas no corpus.
A seguir está uma representação visual de incrustações de palavras:
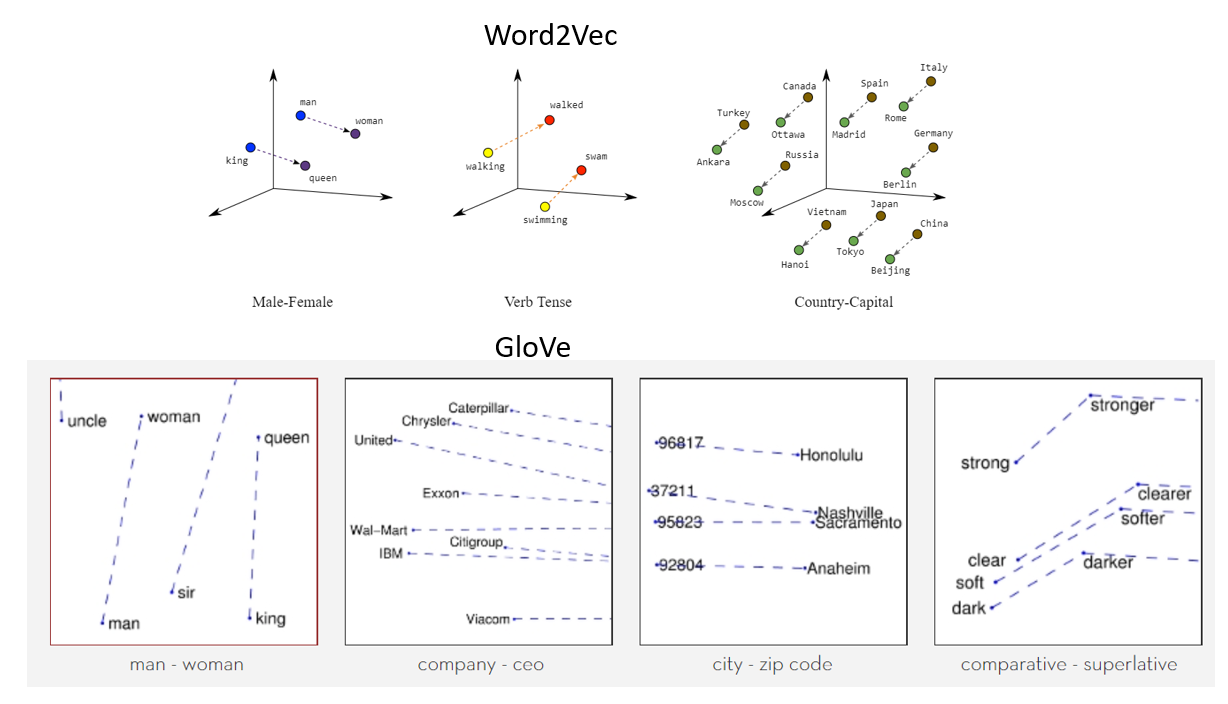
Fonte: https://miro.medium.com/max/1400/1*gcC7b_v7OKWutYN1NAHyMQ.png
Referências:
1. Imagem – https://www.develandoo.com/blog/do-robots-read/
2. https://nlp.stanford.edu/projects/glove/
3. https://wiki.pathmind.com/word2vec
4. https://www.udacity.com/course/natural-language-processing-nanodegree–nd892
conclusão:

Fonte: https: //medium.com/datatobiz/the-past-present-and-the-future-of-natural-language-processing-9f207821cbf6
Sobre mim: Sou um estudante de pesquisa interessado na área de aprendizagem profunda e processamento de linguagem natural e atualmente estou fazendo uma pós-graduação em Inteligência Artificial.
Sinta-se à vontade para se conectar comigo em:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698





