No meu artigo anterior, “Combinando conjuntos de dados no SAS – Simplificado”, analisamos três métodos para combinar conjuntos de dados: anexar, concatenar e intercalar. Neste artigo, veremos o método mais comum e usado para combinar conjuntos de dados: FUSION ou UNION.
A necessidade de unir / mesclar conjuntos de dados:
Antes de entrar em detalhes, vamos entender porque realmente precisamos nos unir / fundir. Sempre que temos informações divididas e disponíveis em dois ou mais conjuntos de dados e queremos combiná-los em um único conjunto de dados, precisamos fundir / junte-se a essas mesas. Uma das coisas principais a se ter em mente é que a mesclagem deve ser baseada em critérios ou campos comuns. Por exemplo, em uma empresa de varejo, temos uma tabela de transações diárias (tabela contém detalhes do produto, detalhes de vendas e detalhes do cliente) e uma tabela de inventário (que tem detalhes do produto e quantidade disponível). Contudo, ter as informações sobre o estoque ou a disponibilidade de um produto, que devemos fazer? Combine a tabela de transações com a tabela de estoque com base em Product_Code e subtraia a quantidade vendida da quantidade disponível.
A fusão / a união pode ser de vários tipos e depende dos requisitos de negócios e da relação entre os conjuntos de dados. Primeiro, Vejamos os vários tipos de relacionamentos que os conjuntos de dados podem ter.
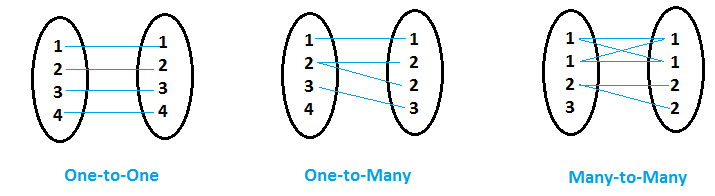
- Quando para cada valor de variável comum (digamos a variável 'x') no primeiro conjunto de dados, o segundo conjunto de dados tem apenas um valor correspondente para aquela variável comum 'x', então é chamado Doze cinquenta e nove relação.
- Quando para os valores da variável comum (digamos a variável 'y') no primeiro conjunto de dados, outros conjuntos de dados têm mais de um valor correspondente para essa variável comum 'y', então é chamado Um para muitos relação.
- Quando ambos os conjuntos de dados têm várias entradas para o mesmo valor de variável comum, então é chamado Muitos para muitos relação.
E SAS, nós podemos fazer sindicatos / fusões através de várias formas, aqui vamos discutir as formas mais comuns: Passo de Dados e PROC SQL. Na etapa de Dados, usamos a declaração de fusão para executar joins, enquanto no PROC SQL, nós escrevemos uma consulta SQL. Vamos analisar o passo dos dados primeiro:
ETAPAS DE DADOS
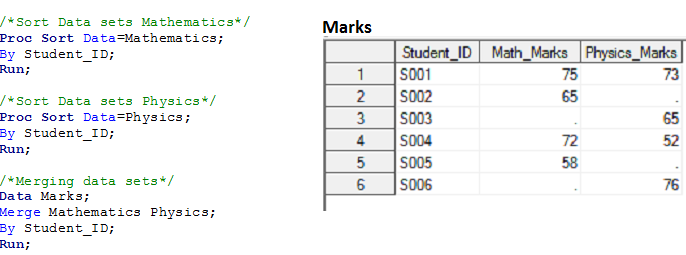
Sintaxe:- Conjunto de dados de dados; Mesclar Dataset1 Dataset2 Dataset3 ... Conjunto de dados; Por CommonVariable1 CommonVariable2...... CommonVariablen; Correr;
Observação: – Os conjuntos de dados devem ser classificados por variável (s) comum e nome, tipo e comprimento da variável comum deve ser o mesmo para todos os conjuntos de dados de entrada.
Vejamos alguns cenários para cada uma das relações entre os conjuntos de dados de entrada.
UM para UM relacionamento
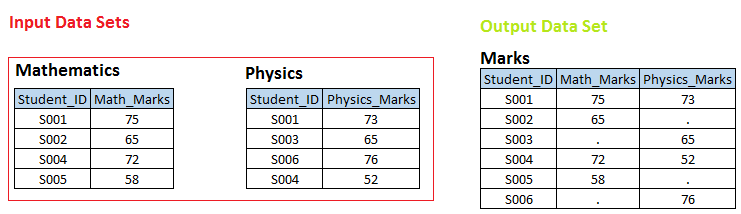
Estágio 1 Nos seguintes conjuntos de dados de entrada, você pode ver que há uma relação um-para-um entre essas duas tabelas em Identidade estudantil. Agora queremos criar um conjunto de dados. MARCAS, onde temos todos os student_ids únicos com as respectivas notas de matemática e física. Se student_id não estiver disponível na tabela matemática, então math_marks deve ter um valor ausente e vice-versa.
Solução usando etapas de dados: –
Como funciona:-
- O SAS compara os dois conjuntos de dados e cria um PDV (Vetor de dados do programa) para todas as variáveis únicas e inicializa-as com valores ausentes (o vetor de dados do programa é um intermediário entre os conjuntos de dados de entrada e saída). No exemplo atual, Eu criaria um POV como este:

- Leia a primeira observação dos conjuntos de dados de entrada e compare os valores da variável BY em ambos os conjuntos de dados:
- se os valores são iguais, é comparado com o valor da variável BY no POS.
- se não for o mesmo, as variáveis de POV são reiniciadas com os valores ausentes e o valor de observação atual é copiado para o POV enquanto a outra observação permanece perdida
- Se for igual, Variáveis POS não são reinicializadas. O valor disponível da observação atual é atualizado no PDV
- Depois disso, o ponteiro do registro se move para a próxima observação em ambos os conjuntos de dados e, enquanto a instrução RUN está em execução, Os valores PDV são passados para o conjunto de dados de saída.
- Se o valor de Por variável não corresponder, a observação do conjunto de dados com o valor mais baixo é copiada para o POS. O ponteiro de registro do conjunto de dados que tem um valor de variável BY inferior é movido para a próxima observação e etapa 2 (uma) repete novamente.
- se os valores são iguais, é comparado com o valor da variável BY no POS.
- As etapas acima são repetidas até que o EOF de ambos os conjuntos de dados seja alcançado.
Você pode executar um teste para avaliar o conjunto de dados de resultados.
Estágio 2: – Com base nos conjuntos de dados de entrada do cenário 1, queremos criar os seguintes conjuntos de dados de saída.
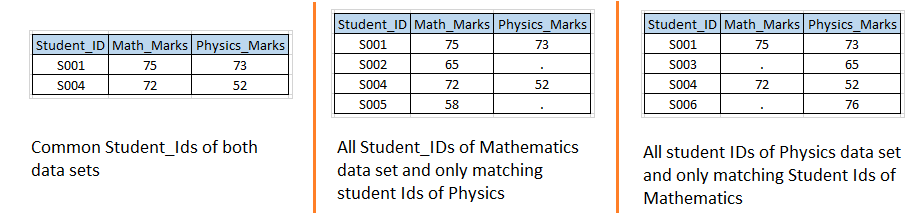
Solução usando etapas de dados: – Vamos escrever um código semelhante ao cenário 1 com a opção IN. 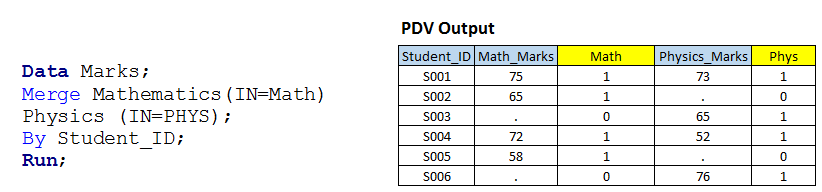 Acima, você pode ver que usamos a opção IN com ambos os conjuntos de dados de entrada e valores atribuídos destes às variáveis temporárias MATH e PHYS porque são variáveis temporárias, então não podemos vê-los no conjunto de dados de saída.
Acima, você pode ver que usamos a opção IN com ambos os conjuntos de dados de entrada e valores atribuídos destes às variáveis temporárias MATH e PHYS porque são variáveis temporárias, então não podemos vê-los no conjunto de dados de saída.
Eu te mostrei a mesa (Dados PDV) que tem um valor variável para todas as observações junto com as variáveis temporárias. Agora, com base no valor dessas variáveis, podemos escrever código para subconfiguração e operações JOIN conforme precisamos:
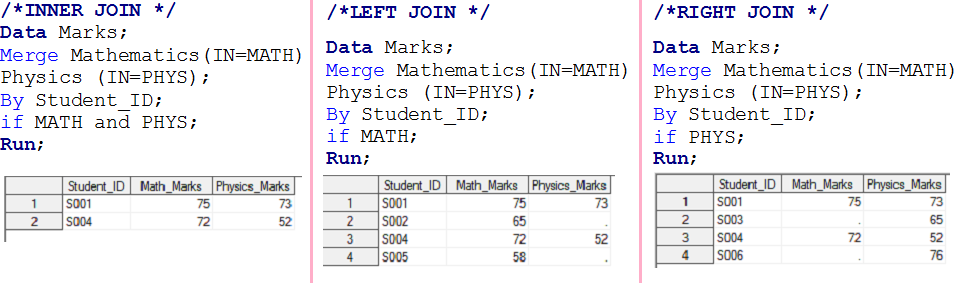
- Se MATH e PHYS tiverem valor 1, irá criar o primeiro conjunto de dados de saída e será chamado INNER JOIN.
- Se MATH tiver 1, irá criar um segundo conjunto de dados de saída e será chamado LEFT JOIN.
- Se PHYS tiver 1, irá criar um terceiro conjunto de dados de saída e será chamado de RIGHT JOIN
- Se MATH e PHYS tiverem 1, funcionará como FULL JOIN, também foi resolvido no estágio 1.
Relacionamento de UM para MUITOS
Estágio – 3 Aqui temos dois conjuntos de dados, Aluna e Exame e queremos criar um conjunto de dados de saída Marcas Registradas.
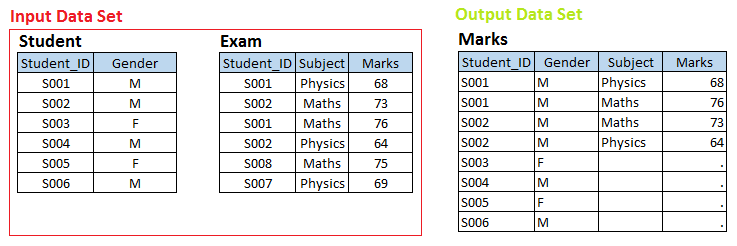
Acima dos conjuntos de dados de entrada, existe uma relação um-para-muitos entre o aluno e o exame. Agora, se você deseja criar marcas de conjunto de dados de saída com observação individual para cada exame do aluno, estes pertencem ao conjunto de dados STUDENT, quer dizer, Saiu sindicato.
Solução usando etapas de dados: –
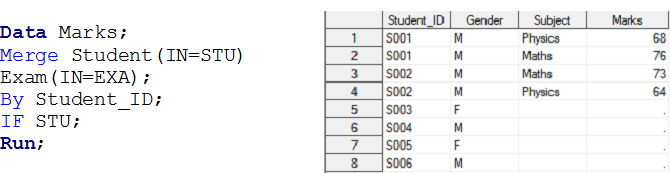
de forma similar, podemos realizar operações para junção interna, certo e completo para um relacionamento um-para-muitos usando o operador IN.
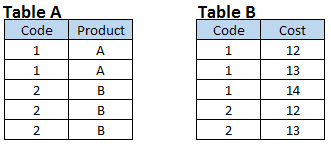
Proporção de MUITOS para MUITOS
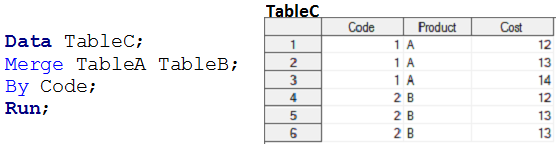
Estágio 4: Crie conjuntos de dados de saída que tenham todas as junções baseadas em um campo comum. Você também pode ver que ambos os conjuntos de dados de entrada têm um relacionamento muitos para muitos.
As etapas de dados não fazem um relacionamento de MUITOS a MUITOS, porque eles não fornecem saída como um produto cartesiano. Quando mesclamos a tabela A e a tabela B usando etapas de dados, a saída é semelhante ao seguinte instantâneo.
 Nós vimos anteriormente, Como podemos usar as etapas de dados para mesclar dois ou mais conjuntos de dados que possuem qualquer um dos relacionamentos, exceto MUITOS a MUITOS? Agora veremos os métodos PROC SQL para ter uma solução para requisitos semelhantes.
Nós vimos anteriormente, Como podemos usar as etapas de dados para mesclar dois ou mais conjuntos de dados que possuem qualquer um dos relacionamentos, exceto MUITOS a MUITOS? Agora veremos os métodos PROC SQL para ter uma solução para requisitos semelhantes.
PROC SQL
Para entender a metodologia de junção em SQL, devemos primeiro entender o produto cartesiano. O produto cartesiano é uma consulta que possui várias tabelas na cláusula from e produz todas as combinações possíveis de linhas das tabelas de entrada. Se tivermos duas tabelas com 2 e 4 registros respectivamente, usando o produto cartesiano, nós temos uma mesa com 2 X 4 = 8 registros.
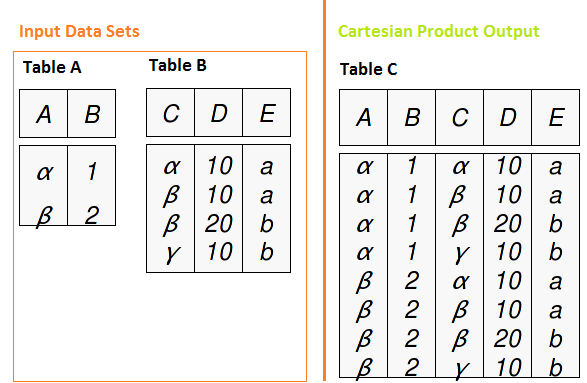
As junções SQL funcionam para cada uma das relações entre os conjuntos de dados (um a um, um para muitos e muitos para muitos). Vamos ver como funciona com tipos de junções.
Sintaxe:-
Por favor selecione Coluna-1, Coluna-2,… Coluna-n da tabela1 JUNTA INTERIOR / DEIXOU / DIREITO / COMPLETO tcapaz2 SOBRE Condição de junção ;
Observação:-
- As tabelas podem ou não ser ordenadas por variáveis comuns.
- O nome das variáveis comuns pode não ser semelhante, mas deve ser semelhante em comprimento e tipo.
- Funciona com no máximo duas tabelas.
Vamos resolver os requisitos acima usando PROC SQL.
Estágio 1 :- Este foi um exemplo de FULL Join, onde todos os Student_IDs eram necessários no conjunto de dados de saída com os respectivos sinalizadores MATH e PHYSICS.

Acima no conjunto de dados de saída, você pode ver que Student_ID está faltando para os alunos que compareceram apenas ao exame de física. Para resolvê-lo, usaremos uma função COALESCE. Retorna o valor do primeiro argumento que não está faltando nas variáveis fornecidas.
Sintaxe:-
COALESCE (argumento-1, argumento-2, ... argumento-n)
Vamos modificar o código acima: –
Estágio 2: – Este foi um exemplo de INNER, Unir Esquerda e Direita. Aqui estamos resolvendo para Inner Join. Do mesmo modo, podemos fazer para a junção esquerda e direita.
Do mesmo modo, podemos fazer para a junção esquerda e direita.
Estágio -3 Este foi um problema de ligação esquerda para um relacionamento de UM para MUITOS.
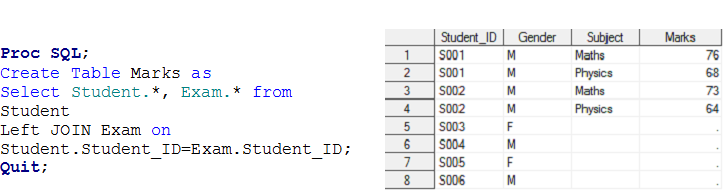
Estágio -4 Este foi um problema de relacionamento de muitos para muitos.. Já discutimos que o SQL pode produzir um produto cartesiano que contém todas as combinações de registros entre duas tabelas.

Acima, vimos Proc SQL para se juntar / mesclar conjuntos de dados.
Nota final: –
Nesta série de artigos sobre a combinação de conjuntos de dados no SAS, analisamos vários métodos para combinar conjuntos de dados, como adicionar, concatenar, intercalar, fusível. Particularmente neste artigo, discutimos que, dependendo da relação entre os conjuntos de dados, vários tipos de junções e como podemos resolvê-los com base em diferentes cenários. Usamos dois métodos (Etapas de dados y PROC SQL) para alcançar resultados. Veremos a eficiência desses métodos em um dos próximos artigos..
Esta série foi útil para você? Simplificamos um tópico complexo como combinar conjuntos de dados e tentamos apresentá-lo de uma forma compreensível. Se você precisar de mais ajuda com a combinação de conjuntos de dados, sinta-se à vontade para fazer suas perguntas através dos comentários abaixo.
PS Você já entrou?? Discutir Vidhya Analítico ainda? Sim, não é assim, muitos debates sobre ciência de dados estão sendo perdidos. Estas são algumas das discussões que acontecem no SAS:
1. Selecione as variáveis e transfira-as para um novo conjunto de dados no SAS
2. Importar o primeiro 20 registros de Excel a SAS
3. Onde a declaração não funciona no SAS





