Introdução
Você já resolveu um problema único de aprendizado de máquina?
Resolver um problema com o aprendizado de máquina não é fácil. Envolve várias etapas para chegar a uma solução precisa. O processo / etapas a seguir para resolver um problema de ml conhecido como ML Pipeline / Ciclo de ML.
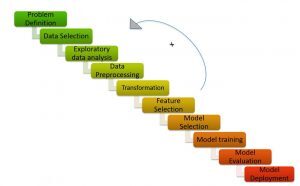
Pipeline de ML / Ciclo de ML (Créditos: https://medium.com/analytics-vidhya/machine-learning-development-life-cycle-dfe88c44222e)
como mostra a imagem, O pipeline de aprendizado de máquina consiste em diferentes etapas, como:
Entenda a declaração do problema, geração de hipótese, Análise exploratória de dados, pré-processamento de dados, engenharia de recursos, seleção de recursos, construção de modelo, ajuste e implementação do modelo.
Eu recomendaria a leitura dos artigos abaixo para obter uma compreensão detalhada do pipeline de aprendizado de máquina:
- Explicação do ciclo de vida do aprendizado de máquina!
- Etapas para concluir um projeto de aprendizado de máquina
O processo de resolver um problema de aprendizado de máquina requer muito tempo e esforço humano. Viva! Não é mais um processo tedioso e demorado! Obrigado ao AutoML por fornecer soluções instantâneas para problemas de aprendizado de máquina.
O AutoML tem tudo a ver com a criação automática de modelos de alto desempenho com o mínimo de intervenção humana.
Bibliotecas AutoML oferecem programação de baixo e nenhum código.
Você provavelmente já ouviu os termos “código baixo” e “sem código”.
- Sem código Frameworks são interfaces de usuário simples que permitem que até mesmo usuários não técnicos construam modelos sem escrever uma única linha de código.
- Baixo código refere-se à codificação mínima.
Embora as plataformas sem código facilitem o treinamento de um modelo de aprendizado de máquina usando uma interface de arrastar e soltar, são limitados em termos de flexibilidade. O ML de baixo código, por outro lado, é o ponto ideal e o meio termo, pois oferecem flexibilidade e código fácil de usar.
Neste artigo, Vamos entender como construir um modelo de classificação de texto dentro de algumas linhas de código usando uma biblioteca AutoML de baixo código, PyCaret.
Tabela de conteúdo
- O que é PyCaret?
- Por que precisamos do PyCaret?
- Diferentes abordagens para resolver a classificação de texto no PyCaret
- Modelagem de tema
- Vetorizador de contagem
- Estudo de caso: classificação de texto com PyCaret
O que é PyCaret?
PyCaret é uma biblioteca de aprendizado de máquina de código aberto e baixo em Python que permite ir da preparação de seus dados à implementação de seu modelo em alguns minutos..

PyCaret (Créditos: https://pycaret.org/)
PyCaret é essencialmente uma biblioteca de baixo código que substitui centenas de linhas de código no scikit learn a 5-6 linhas de código. Aumenta a produtividade da equipe e ajuda a equipe a se concentrar na compreensão do problema e nos recursos de engenharia, em vez de otimizar o modelo.
PyCaret (Créditos: https://pycaret.org/about/)
PyCaret é construído em cima de uma biblioteca de aprendizado do scikit. Como resultado, todos os algoritmos de aprendizado de máquina disponíveis no scikit learn estão disponíveis no pycaret. A partir de agora, PyCaret pode resolver problemas relacionados à classificação, regressão, agrupamento, detecção de anomalia, classificação de texto, mineração de regras e séries temporais associadas.
Agora, Vamos analisar as razões por trás do uso do PyCaret.
Por que precisamos do PyCaret?
PyCaret cria automaticamente o modelo de referência dado um conjunto de dados dentro 5-6 linhas de código. Vamos ver como o pycaret simplifica cada etapa do pipeline de aprendizado de máquina.
- Preparação de dados: PyCaret realiza limpeza e pré-processamento de dados com o mínimo de intervenção manual.
- Engenharia de funções: PyCaret cria as características matemáticas automaticamente e seleciona as características mais importantes necessárias para o modelo
- Construção do modelo: Simplifica muito a parte de modelagem do seu projeto. Podemos construir diferentes modelos e selecionar os modelos de melhor desempenho com uma única linha de código.
- Ajuste do modelo: PyCaret ajusta o modelo sem passar explicitamente hiperparâmetros para cada modelo.
A seguir, vamos nos concentrar em resolver um problema de classificação de texto no PyCaret.
Diferentes abordagens para resolver a classificação de texto no PyCaret
Vamos resolver um problema de classificação de texto no PyCaret usando 2 técnicas diferentes:
- Modelagem de tema
- Vetorizador de contagem
Vou tocar em cada foco em detalhes
Modelagem de tema
Modelagem de tema, Como o nome implica, é uma técnica para identificar diferentes temas presentes nos dados do texto.
Os temas são definidos como um grupo repetitivo de símbolos (ou palavras) estatisticamente significativo em um corpus. Aqui, significância estatística refere-se a palavras importantes no documento. Em geral, palavras que aparecem com frequência com pontuações mais altas do TF-IDF são consideradas palavras estatisticamente significativas.
A modelagem de tópicos é uma técnica não supervisionada para encontrar automaticamente tópicos ocultos em dados de texto. Também pode ser chamada de abordagem de mineração de texto para encontrar padrões recorrentes em documentos de texto.
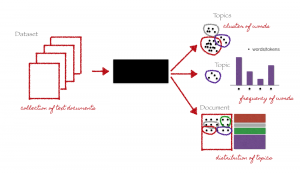
Modelagem de tema (Créditos: https://medium.com/analytics-vidhya/topic-modeling-using-lda-and-gibbs-sampling-explained-49d49b3d1045)
Alguns casos de uso comuns para modelagem de tema incluem o seguinte:
-  Resolver problemas de classificação / regressão de texto
- Crie tags relevantes para documentos
- Gerar informações para formulários de feedback do cliente, Opinião dos consumidores, resultados da pesquisa, etc.
Exemplo de modelagem de tema
Suponha que você trabalhe para um escritório de advocacia e esteja trabalhando para uma empresa onde algum dinheiro foi desviado e você sabe que há informações importantes nos e-mails que foram distribuídos na empresa.
- Então, verifique e-mails e há centenas de milhares de e-mails. Agora, o que você precisa fazer é descobrir quais estão relacionados a dinheiro em comparação com outros tópicos.
- Você pode etiquetá-los manualmente com base no que lê no texto, o que levaria muito tempo, ou você pode usar a técnica chamada modelagem de tema para descobrir o que são essas tags e marcar automaticamente todos esses e-mails.
Como explicado acima, o objetivo da modelagem de tema é extrair diferentes temas do texto bruto. Mas, Qual é o algoritmo subjacente para alcançá-lo?
Isso nos leva aos diferentes algoritmos / técnicas para modelagem de temas: atribuição dirichlet latente (LDA), fatoração de matriz não negativa (NNMF), atribuição semântica latente (LSA).
Eu recomendo que você consulte os seguintes recursos para ler em detalhes sobre os algoritmos
- Papel 2: Modelagem de tema e atribuição de Dirichlet latente (LDA) usando Gensim e Sklearn
- Guia do iniciante para modelagem de tema em Python
- Modelagem de tema com LDA: uma introdução prática
Chegando à modelagem de tema, é um processo de 2 Passos:
- Distribuição de tópicos do termo: Encontre os tópicos mais importantes do corpus.
- Distribuição de documento para tópico: Atribua pontuações para cada tópico de cada documento.
Tendo entendido a modelagem do tema, veremos como resolver a classificação de texto usando modelagem de tópicos com a ajuda de um exemplo.
Considere um corpus:
- Documento 1: Eu quero comer frutas no café da manhã.
- Documento 2: Eu gosto de comer amêndoas, ovos e frutas.
- Documento 3: Vou levar frutas e biscoitos comigo quando for ao zoológico.
- Documento 4: O tratador alimenta o leão com muito cuidado.
- Documento 5: Biscoitos de boa qualidade devem ser dados aos seus cães.
O algoritmo de modelagem do tema (LDA) identifica os tópicos mais importantes nos documentos.
- Tema 1: 30% frutas, 15% ovos, 10% biscoitos,… (refeição)
- Tema 2: 20% Leão, 10% cachorros, 5% Jardim zoológico,… (animais)
A seguir, atribua pontuações para cada tópico aos documentos da seguinte forma.
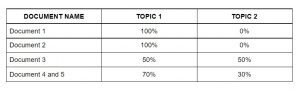
Atribuir tópicos a cada documento usando LDA
Esta matriz atua como características do algoritmo de aprendizado de máquina. A seguir, vamos ver o saco de palavras.
Saco de palavras
Saco de palavras (ARCO) é outro algoritmo popular para representar texto em números. Depende da frequência das palavras no documento. BOW tem inúmeras aplicações, como classificação de documentos, modelagem de tema e similaridade de texto. E BOW, cada documento é representado como a frequência de palavras presentes no documento. Então, a frequência das palavras representa a importância das palavras no documento.
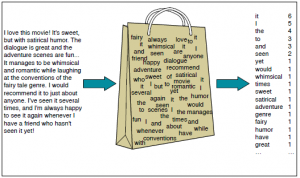
Saco de palavras (Créditos: Jurafsky et al., 2018)
Siga o artigo abaixo para obter uma compreensão detalhada do Saco de Palavras:
Na próxima seção, vamos resolver o problema de classificação de texto no PyCaret.
Estudo de caso: classificação de texto com PyCaret
Vamos entender a declaração do problema antes de resolvê-lo.
Compreendendo a declaração do problema
Steam é um serviço de distribuição de videogame digital com uma vasta comunidade de jogadores em todo o mundo. Muitos jogadores escrevem comentários na página do jogo e têm a opção de escolher se recomendariam este jogo a outras pessoas ou não.. Porém, determinar esse sentimento automaticamente a partir do texto pode ajudar o Steam a marcar automaticamente as avaliações retiradas de outros fóruns da Internet e pode ajudá-los a julgar melhor a popularidade dos jogos.
Dado o texto do comentário com a recomendação do usuário, a tarefa é prever se o revisor recomendou os títulos de jogos disponíveis no conjunto de teste com base no texto da revisão e outras informações.
Em termos mais simples, a tarefa em mãos é identificar se uma determinada avaliação do usuário é boa ou ruim. Você pode baixar o conjunto de dados em aqui.
Implementação
Para avaliar as análises de jogos do Steam usando o PyCaret, Eu discuti 2 diferentes abordagens no artigo.
- A primeira abordagem usa modelagem de tema usando PyCaret.
- A segunda abordagem usa os recursos do Bag Of Words. Use essas funções para classificação usando PyCaret.
Vamos implementar a abordagem BOW agora.
Observação: O tutorial é implementado no Google Colab. Eu recomendaria executar o código nele.
Instalação PyCaret
Você pode instalar o PyCaret como qualquer outra biblioteca Python.
- Instale o PyCaret no Google Colab ou Azure Notebooks
Importação de bibliotecas
Carregando dados
Como o PyCaret não suporta o vetorizador de contagem, importe o módulo CountVectorizer de sklearn.feature_extraction.
Mais tarde, Eu inicializo um objeto CountVectorizer chamado 'tf_vectorizer'.
O que exatamente a função fit_transform faz com seus dados?
- “Ajustar” extrai as características do conjunto de dados.
- “Transformar” realmente realiza as transformações no conjunto de dados.
Vamos converter a saída de fit_transform para o quadro de dados.
Agora, concatenar as características e o objetivo ao longo da coluna.
A seguir, vamos dividir o conjunto de dados em dados de teste e treinamento.
Agora que a extração de recursos está concluída. Vamos usar essas funções para construir modelos diferentes. Então, o próximo passo é configurar o ambiente no PyCaret.
Configurando o ambiente
- Esta função configura a estrutura de treinamento e constrói o processo de transição. A função de configuração deve ser chamada antes que qualquer outra função possa ser chamada.
- O único parâmetro obrigatório são os dados e o objetivo.
Criação de modelos
Ajuste do modelo
Da saída anterior, podemos ver que as métricas do modelo ajustado são melhores do que as métricas do modelo base.
Avalie e preveja o modelo
Aqui, Eu previ os valores de sinalização para nosso conjunto de dados processados, ‘Tuned_lightgbm’.
Notas finais
PyCaret, treinamento de modelos de aprendizado de máquina em um ambiente de baixo código, despertou meu interesse. Do seu ambiente de laptop preferido, PyCaret ajuda você a ir da preparação de dados à implementação do modelo em segundos. Antes de usar PyCaret, Eu tentei outros métodos tradicionais para resolver o problema do hackathon JanataHack PNL, Mas os resultados não foram muito satisfatórios!!
O PyCaret provou ser exponencialmente rápido e eficiente em comparação com outras bibliotecas de aprendizado de máquina de código aberto e também tem a vantagem de substituir várias linhas de código com apenas algumas palavras..
Aqui, se você evitar a primeira parte da minha abordagem, onde eu uso as técnicas de incorporação do vetorizador de contagem no meu conjunto de dados e, em seguida, passo para a configuração e criação de modelos usando PyCaret, então você pode notar que todas as transformações, como hot coding , a imputação de valores perdidos, etc., acontecerá nos bastidores automaticamente, e então você obterá um quadro de dados com previsões, Como o que temos!
Espero ter deixado minha abordagem geral do hackathon clara.





