Este artigo foi publicado como parte do Data Science Blogathon
Visão geral
- Aprenda o conceito básico de mineração de dados
- Compreenda as aplicações da mineração de dados
Pré-requisitos
- Conhecimento básico de Python
- Conhecimento básico de DataBase
Bem-vindos, caras!
Aqui, vou dar-lhe uma breve compreensão dos fundamentos da mineração de dados. Sabemos que en todas partes hay datos en varios formatos que se almacenarán en una base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos..... De acordo com a escala de dados, podemos escolher um banco de dados adequado. Então, existem bancos de dados populares que conhecemos, como PostgreSQL, NoSQL, MongoDB, Microsoft SQL Server e muitos mais.
Neste artigo, você terá uma ideia de mineração de dados.
Então vamos continuar …
O que é mineração de dados?
“Processamento de dados”, que extrai os dados. Em palavras simples, se define como encontrar insights ocultos (em formação) do banco de dados, extrair padrões de dados.
Existem diferentes algoritmos para diferentes tarefas. A função desses algoritmos é ajustar o modelo. Esses algoritmos identificam as características dos dados. Existem 2 tipos de modelos.
1) Modelo preditivo
2) Modelo descritivo
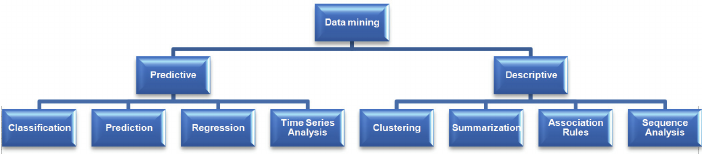
Tarefas básicas de mineração de dados
Nesta secção, veremos algumas das funções / tarefas de mineração.
1) Classificação
Este término viene bajo aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em.... Os algoritmos de classificação requerem que as classes sejam definidas com base em variáveis. As características dos dados definem a qual classe eles pertencem. O reconhecimento de padrões é um dos tipos de problemas de classificação em que a entrada (Padrão) é classificado em diferentes classes com base em sua similaridade de classe definida.
2) Predição
Na vida real, Muitas vezes vemos coisas que predizem / valores futuros / ou de outra forma com base em dados anteriores e presentes. A previsão também é um tipo de tarefa de classificação. De acordo com o tipo de aplicação, por exemplo, prever inundações onde as variáveis dependentes são o nível de água do rio, sua umidade, escala de chuva, etc. são os atributos.
3) Regressão
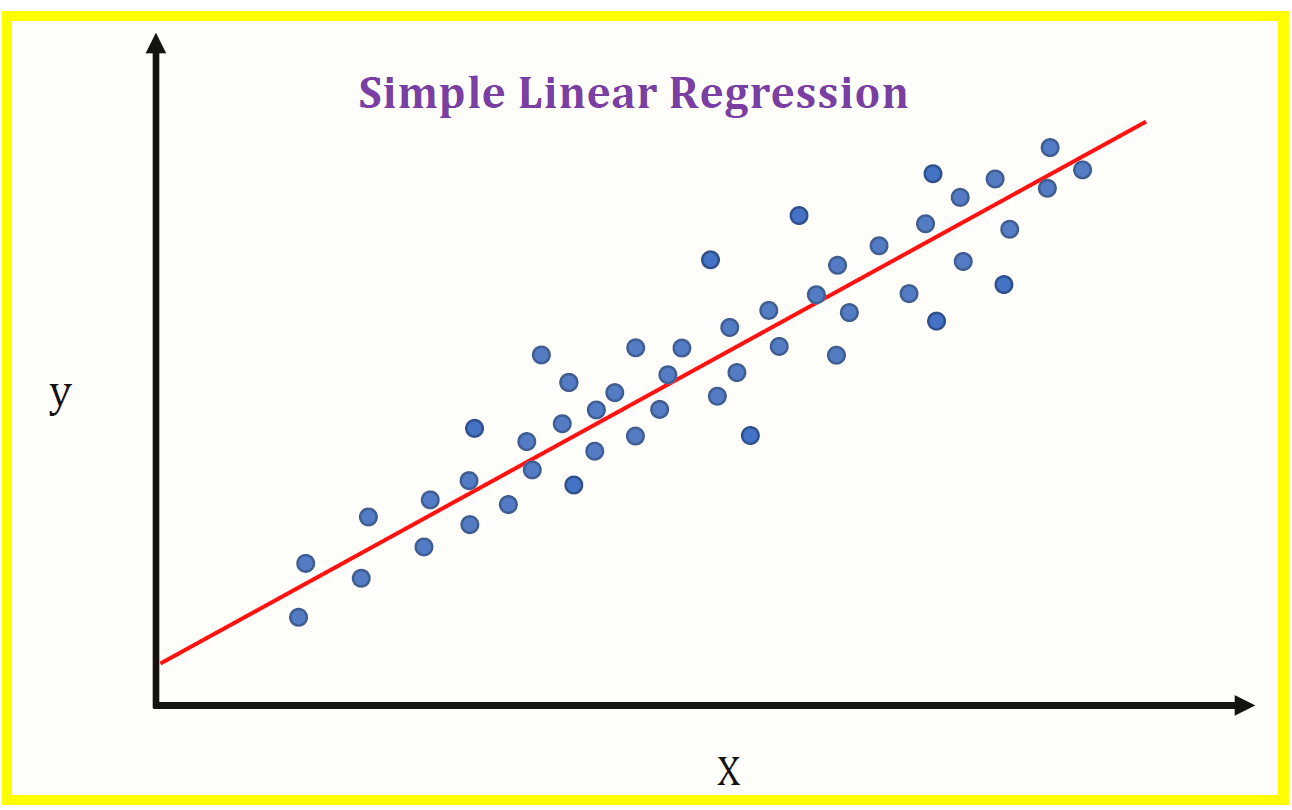
A regressão é uma técnica estatística usada para determinar a relação entre as variáveis (x) e as variáveis dependentes (e). Existem alguns tipos de regressão, como Linear, Logística, etc. A regressão linear é usada em valores contínuos (0,1,1,5,… .e assim por diante) e a Regressão Logística é utilizada quando existe a possibilidade de apenas dois eventos à medida que ocorrem / fracasso, verdade / falso, sim / não, etc.
4) Análise de série temporal
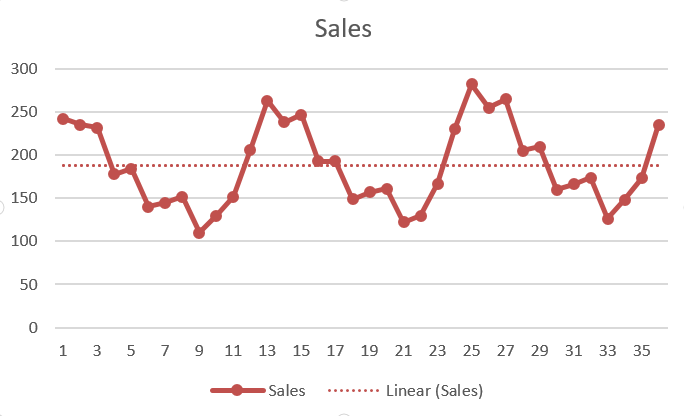
Na análise de séries temporais, uma variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... cambia su valor según el tiempo. Isso significa que a análise passa por padrões de identificação de dados ao longo de um período de tempo. Pode ser variação sazonal, variação irregular, tendência secular e flutuação cíclica. Por exemplo, chuva anual, preço da bolsa, etc.
5) Agrupamento
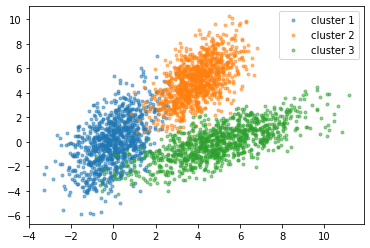
O agrupamento é igual à classificação, quer dizer, agrupar os dados. O clustering está incluído no aprendizado de máquina não supervisionado. É um processo de divisão dos dados em grupos com base em tipos de dados semelhantes.
6) Resumo
O resumo nada mais é do que caracterização ou generalização. Recupere informações significativas de dados. Ele também oferece um resumo das variáveis numéricas como média, moda, medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos...., etc.
7) Regras de associação
É a principal tarefa de Data Mining. Ajuda a encontrar padrões apropriados e conhecimento significativo do banco de dados. A regra de associação é um modelo que extrai tipos de associações de dados. Por exemplo, Análise de cesta de compras onde as regras de associação são aplicadas ao banco de dados para saber quais itens o cliente compra junto.
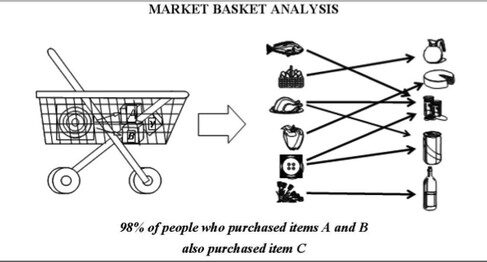
8) Descoberta de sequência
Também chamada de análise sequencial. É usado para descobrir ou encontrar o padrão sequencial nos dados.
Padrão sequencial significa o padrão que é puramente baseado em uma sequência de tempo. Esses padrões são semelhantes às regras de associação encontradas no banco de dados ou os eventos estão relacionados, mas seu relacionamento é baseado apenas em "Tempo".
Até aqui, vimos todas as funções ou tarefas básicas de mineração de dados. Vamos prosseguir para descobrir mais sobre mineração de dados …
Mineração de dados VS KDD (descoberta de conhecimento no banco de dados)
Processamento de dados: Processo de uso de algoritmos para extrair informações significativas e padrões derivados do processo KDD. É uma etapa envolvida no KDD.
KDD: É um processo significativo de identificação de padrões e informações significativas nos dados. A entrada fornecida para este processo são os dados e a saída fornece informações úteis dos dados.
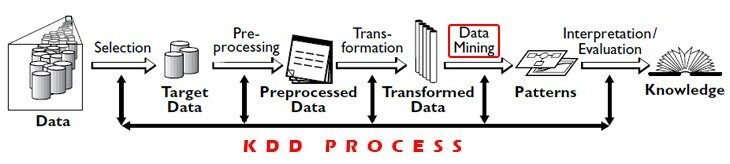
O processo KDD consiste em 5 Passos:
1) Seleção: Necessidade de obter dados de várias fontes de dados, bases de dados.
2) Pré-processando: Este processo de limpeza de dados em termos de dados ruins, valores ausentes, dados errados.
3) Transformação: Os dados de várias fontes devem ser convertidos e codificados em algum formato para pré-processamento.
4) Mineração de dados: Nesse processo, algoritmos são aplicados aos dados transformados para alcançar a saída ou resultados desejados.
5) Interpretação / avaliação: Você tem que fazer algumas visualizações para apresentar resultados de mineração de dados que são muito importantes.
Aplicativos de mineração de dados
1) Comércio eletrônico
O comércio eletrônico é uma de suas aplicações na vida real. Empresas de comércio eletrônico são como a Amazon, Flipkart, Myntra, etc. Eles usam técnicas de mineração de dados para ver a funcionalidade de cada produto de forma que "qual produto é mais visto pelo cliente e também o que o outro gostou".
2) retalho
É outro aplicativo de mineração de dados do mercado de varejo. Os varejistas encontram o padrão de “frescor, frequência, monetário (em termos de moeda)”. Varejistas rastreiam vendas e transações de produtos.
3) Educação
A educação é um campo emergente e popular hoje. É sobre a descoberta de conhecimento a partir de dados educacionais. O principal objetivo desta aplicação é estudar ou identificar o padrão de comportamento do aluno em termos de aprendizagem futura, efeitos de estudo, conhecimento de aprendizagem avançado, etc. Essas técnicas de mineração de dados são usadas por instituições para tomar decisões precisas e também prever resultados adequados..
Ferramentas de mineração de dados
– KNIME
-WEKA
-LARANJA
Algoritmos de mineração de dados
- Agrupamento de meias K
- Máquinas de vetor de suporte
- A priori
- KNN
- Bayes ingenuo
- CART e muitos mais …
Estes são alguns algoritmos.
* Agora vou fornecer informações sobre as bibliotecas necessárias abaixo.
– A priori:
de apyori import apriori
– Agrupamento de meias K:
from kneed import KneeLocator
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler– Máquinas de vetor de suporte:
de sklearn import svm
-Baías ingénuas:
de sklearn.naive_bayes import GaussianNB
-CARRO:
de sklearn.tree import DecisionTreeRegressor
-KNN:
fromsklearn.neighborsimportKNeighborsClassifier
Então, aqui estão algumas bibliotecas que precisam ser instaladas enquanto o algoritmo está executando.
conclusão
Espero que tenha gostado do meu artigo. Se você tiver alguma dúvida, você pode deixar comentários abaixo. Obrigado!
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





