Este artigo foi publicado como parte do Data Science Blogathon.
Visão geral
passou a ser, verdade? Nós agrupamos os pontos de dados em 3 grupos com base em sua semelhança ou proximidade.
Tabela de conteúdo
1.Introdução ao K significa
2.K significa ++ algoritmo
3.Como escolher o valor K em K significa?
4.Considerações práticas em média K
5.Tendência de cluster
1. Introdução
Vamos apenas entender o agrupamento de K-médias com exemplos da vida diária. Sabemos que hoje em dia todo mundo adora assistir séries da web ou filmes no Amazon Prime, Netflix. Você já observou algo sempre que abre o Netflix? quer dizer, filmes de grupo baseados em seu gênero, quer dizer, crime, suspenso, etc., Espero que você tenha observado ou já saiba. portanto, o agrupamento de gênero do Netflix é um exemplo fácil de entender de agrupamento. vamos entender mais sobre k significa algoritmo de agrupamento.
Definição: Agrupe pontos de dados com base em sua semelhança ou proximidade uns com os outros, em termos simples, o algoritmo precisa encontrar os pontos de dados cujos valores são semelhantes entre si e, portanto, esses pontos pertenceriam ao mesmo grupo.
Então, Como o algoritmo encontra os valores entre dois pontos para agrupá-los? O algoritmo encontra os valores usando o método de 'Medição de distância'. aqui, a medida de distância é 'distância euclidiana’
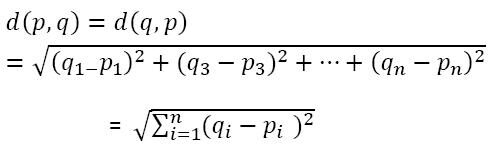
As observações mais próximas ou semelhantes entre si teriam uma distância euclidiana baixa e, então, seriam agrupadas.
mais uma fórmula que você precisa saber para entender os meios de K é ‘Centroid’. O algoritmo k-means usa o conceito de centróide para criar 'grupos k'.
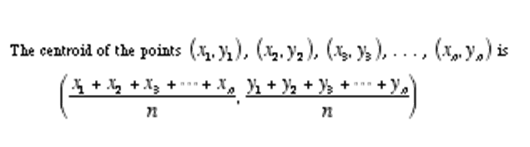
Agora você está pronto para entender as etapas do algoritmo de agrupamento k-means.
Etapas em K-médias:
paso 1: escolha o valor k para ex: k = 2
paso 2: inicializar centroides aleatoriamente
Paso 3: calcular a distância euclidiana dos centróides a cada ponto de dados e formar grupos próximos aos centróides
paso 4: encontre o centróide de cada grupo e atualize os centróides
paso: 5 repita o passo 3
Cada vez que os grupos são feitos, atualização de centróides, o centróide atualizado é o centro de todos os pontos que caem no grupo. Este processo continua até que o centróide não mude mais, quer dizer, a solução converge.
Você pode brincar com o algoritmo K-means usando o link abaixo, tente.
https://stanford.edu/class/engr108/visualizations/kmeans/kmeans.html
Então, que segue? Como você escolhe os centróides iniciais aleatoriamente?
Aí vem o conceito do algoritmo k-médias ++.
2. Algoritmo K-Means ++:
Eu não vou te estressar por isso, então não se preocupe. É muito fácil de entender. Então, O que é k-significa ++ ??? Digamos que queremos escolher dois centróides inicialmente (k = 2), você pode escolher um centróide aleatoriamente ou você pode escolher um dos pontos de dados aleatoriamente. Simples verdade? Nossa próxima tarefa é escolher outro centróide, Como você escolhe? alguma ideia?
Escolhemos o próximo centróide dos pontos de dados que está a uma grande distância do centróide existente ou aquele que está a uma grande distância de um grupo existente que tem uma grande probabilidade de capturar.
3.Como escolher o valor K em K-médias:
1.Método do cotovelo
Passos:
Paso 1: calcular algoritmo de agrupamento para diferentes valores de k.
por exemplo k =[1,2,3,4,5,6,7,8,9,10]
paso 2: para cada k, calcular a soma dos quadrados dentro do cluster (WCSS).
Paso 3: plotar a curva WCSS de acordo com o número de clusters.
Paso 4: A localização da curva no gráfico é geralmente considerada um indicador do número aproximado de clusters.
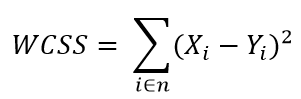
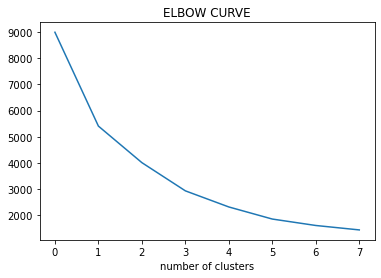
Considerações práticas em K-means:
- Uma série de clusters escolhidos com antecedência (K).
- Padronização de dados (escalado).
- Dados categóricos (pode ser resolvido com o modo K).
- Impacto de centróides e outliers iniciais.
5. Tendência de cluster:
Antes de aplicar um algoritmo de agrupamento aos dados fornecidos, é importante verificar se os dados fornecidos têm alguns clusters significativos ou não. O processo de avaliação dos dados para verificar se os dados são viáveis para clustering ou não é conhecido como 'tendência de clustering', portanto, não devemos aplicar cegamente o método de agrupamento e verificar a tendência de agrupamento. Quão?
Usamos a 'Estatística de Hopkins’ para saber se deve realizar clustering ou não para um determinado conjunto de dados. Examine se os pontos de dados diferem significativamente dos dados uniformemente distribuídos no espaço multidimensional.
Isso conclui nosso artigo sobre o algoritmo de agrupamento de k-médias.. No meu próximo artigo, Vou falar sobre a implementação Python do algoritmo de agrupamento K-means.
Obrigado!
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





