Introdução
O que é limpeza de dados? Removendo registros nulos, removendo colunas desnecessárias, o tratamento de valores ausentes, retificação de valores indesejados ou outliers, reestruturando os dados para editá-los em um formato mais legível, etc., é conhecido como limpeza de dados.

Um dos exemplos mais comuns de limpeza de dados é sua aplicação em data warehouses. Um data warehouse armazena uma variedade de dados de várias fontes e os otimiza para análise antes que qualquer ajuste de modelo possa ser realizado.
A limpeza de dados não é apenas remover informações existentes para adicionar novas informações, mas encontre uma maneira de maximizar a precisão de um conjunto de dados sem necessariamente fornecer as informações existentes. Diferentes tipos de dados exigirão diferentes tipos de limpeza, mas lembre-se sempre de que a abordagem certa é o fator decisivo.
Depois de limpar os dados, se tornará consistente com outros conjuntos de dados semelhantes no sistema.. Vamos ver as etapas para limpar os dados;
Limpar registros nulos / duplicatas
Se uma determinada linha estiver faltando uma quantidade significativa de dados, então seria melhor deletar essa linha, uma vez que não agregaria nenhum valor ao nosso modelo. pode imputar o valor; fornecer um substituto apropriado para os dados ausentes. Lembre-se também de sempre apagar valores duplicados / redundante do seu conjunto de dados, uma vez que podem resultar em um viés em seu modelo.
Como um exemplo, considere o conjunto de dados do aluno com os seguintes registros.
| Nome | pontuação | Endereço | altura | peso |
| UMA | 56 | Vamos para | 165 | 56 |
| B | 45 | Bombay | 3 | sessenta e cinco |
| C | 87 | Délhi | 170 | 58 |
| D | ||||
| mim | 99 | Mysore | 167 | 60 |
Como vemos que corresponde ao nome do aluno “D”, a maioria dos dados está faltando, por isso, nós descartamos aquela linha particular.
student_df.dropna() # derruba linhas com 1 ou mais valor Nan
#Produção
| Nome | pontuação | Endereço | altura | peso |
| UMA | 56 | Vamos para | 165 | 56 |
| B | 45 | Bombay | 3 | sessenta e cinco |
| C | 87 | Délhi | 170 | 58 |
| mim | 99 | Mysore | 167 | 60 |
Exclua colunas desnecessárias
Quando recebemos dados de partes interessadas, em geral é enorme. Pode haver um registro de dados que pode não agregar nenhum valor ao nosso modelo. É melhor excluir esses dados, uma vez que faria isso com recursos valiosos, como memória e tempo de processamento.
Como um exemplo, observar o desempenho dos alunos em um teste, o peso ou altura dos alunos não tem nada a contribuir para o modelo.
student_df.drop(['altura','peso'], eixo = 1, local = Verdadeiro) #Coluna de queda de altura do dataframe
#Produção
| Nome | pontuação | Endereço |
| UMA | 56 | Vamos para |
| B | 45 | Bombay |
| C | 87 | Délhi |
| mim | 99 | Mysore |
Renomear colunas
É sempre melhor renomear as colunas e formatá-las para o formato mais legível que o cientista de dados e a empresa possam entender.. Como um exemplo, no conjunto de dados do aluno, renomear coluna “Nome” O que “Sudent_Name” faz sentido.
student_df.rename(colunas ={'nome': 'Nome do aluno'}, inplace = True) #renomeia a coluna de nome para Student_Name
#Produção
| Nome do aluno | pontuação | Endereço |
| UMA | 56 | Vamos para |
| B | 45 | Bombay |
| C | 87 | Délhi |
| mim | 99 | Mysore |
Lidar com valores ausentes
Existem muitas alternativas para cuidar de valores ausentes em um conjunto de dados. Cabe ao cientista de dados e ao conjunto de dados em mãos selecionar o método mais apropriado. Os métodos mais utilizados são a imputação do conjunto de dados com média, medianaA mediana é uma medida estatística que representa o valor central de um conjunto de dados ordenados. Para calculá-lo, Os dados são organizados do menor para o maior e o número no meio é identificado. Se houver um número par de observações, Os dois valores principais são calculados em média. Este indicador é especialmente útil em distribuições assimétricas, uma vez que não é afetado por valores extremos.... o moda. Excluir esses registros particulares com um ou mais valores ausentes e, em alguns casos, criar algoritmos de aprendizado de máquina como regressão linear e vizinho mais próximo K também é usado para lidar com valores ausentes.
| Nome do aluno | pontuação | Endereço |
| UMA | 56 | Vamos para |
| B | 45 | Bombay |
| C | Délhi | |
| mim | 99 | Mysore |
Student_df['col_name'].Fillna((Student_df['col_name'].quer dizer()), inplace = True) # Os valores Na em nome_col são substituídos pela média
#Produção
| Nome do aluno | pontuação | Endereço |
| UMA | 96 | Vamos para |
| B | 45 | Bombay |
| C | 66 | Délhi |
| mim | 99 | Mysore |
Detecção de valores atípicos
Outliers podem ser considerados como ruído no conjunto de dados. Pode haver vários motivos para outliers, como erro de entrada de dados, manual de erro, erro experimental, etc.
Como um exemplo, no exemplo a seguir, pontuação do aluno “B” entre 130, o que é claramente incorreto.
| Nome do aluno | pontuação | Endereço | altura | peso |
| UMA | 56 | Vamos para | 165 | 56 |
| B | 45 | Bombay | 3 | sessenta e cinco |
| C | 66 | Délhi | 170 | 58 |
| mim | 99 | Mysore | 167 | 60 |
Plotar a altura em um gráfico de caixa dá o seguinte resultado
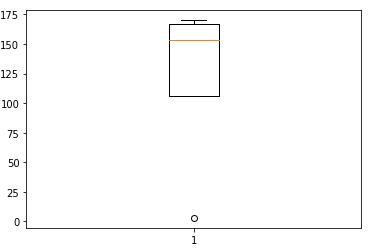
Nem todos os valores extremos são outliers, alguns também podem levar a descobertas interessantes, mas isso é um assunto para outro dia. Testes como o teste de pontuação Z podem ser usados, o box plot ou simplesmente plotar os dados no gráfico irá revelar os outliers.
Reforma / reestruturar os dados
A maioria dos dados de negócios fornecidos ao cientista de dados não está no formato mais legível. É nosso trabalho reformular os dados e colocá-los em um formato que possa ser usado para análise.. Como um exemplo, creando una nueva variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... a partir de las variables existentes o combinando 2 ou mais variáveis.
Notas de rodapé
Certamente, há muitos benefícios em trabalhar com dados limpos, poucos deles são a precisão aprimorada dos modelos, melhor tomada de decisão pelas partes interessadas, la facilidad de implementación del modelo y el ajuste de parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto...., economizando tempo e recursos, e muito mais. Lembre-se sempre de limpar os dados como a primeira e mais importante etapa antes de ajustar qualquer modelo.
Referências
https://www.geeksforgeeks.org/
A mídia mostrada nesta postagem não é propriedade da DataPeaker e é usada a critério do autor.





