Este artigo foi publicado como parte do Data Science Blogathon
1. Introdução
En este trabajo, presentamos la relación del rendimiento del modelo con un tamaño de conjunto de datos variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... y un número variable de clases de destino. Hemos realizado nuestros experimentos en reseñas de productos de Amazon.
El conjunto de datos contiene el título de la reseña, el texto de la reseña y las calificaciones. Hemos considerado las calificaciones como nuestra clase de salida. O que mais, hemos realizado tres experimentos (polaridade 0/1), tres clases (positivo, negativo, neutro) y cinco clases (calificación de 1 uma 5). Hemos incluido tres modelos tradicionales y tres de aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde....
Modelos de aprendizaje automático
1. Regressão logística (LR)
2. Máquina de vetores de suporte (SVM)
3. Naive-Bayes (NB)
Modelos de aprendizagem profunda
1. Neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. de convolución (CNN)
2. Memoria a corto plazo (LSTM)
3. Unidad recurrente cerrada (GRU)
2. El conjunto de datos
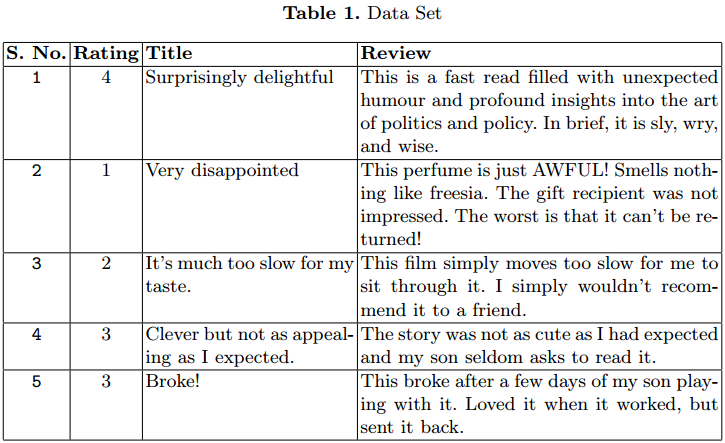
Usamos el conjunto de datos de revisión de productos de Amazon para nuestro experimento. O conjunto de dados contém 3,6 millones de instancias de la revisión del producto en forma de texto.
Se han proporcionado archivos separados de tren (3M) y de prueba (0,6M) em formato CSV. Cada instancia tiene 3 atributos. El primer atributo es el classificação Entre 1 e 5. El segundo atributo es el qualificação de la revisión. El último es el texto de revisión.
En la Tabla 1 se dan algunos casos. Hemos considerado solo 1,5 M.
3. Experimento para análisis
Ya hemos mencionado que todo el experimento se realizó para clasificación binaria, de tres clases y de cinco clases. Hemos realizado algunos pasos de procesamiento previo en el conjunto de datos antes de pasarlo a los modelos de clasificación. Cada experimento se realizó de forma incremental.
Comenzamos nuestra capacitación con 50000 instancias y aumentamos a 1,5 millones de instancias para capacitación. Finalmente, registramos los parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... de rendimiento de cada modelo.
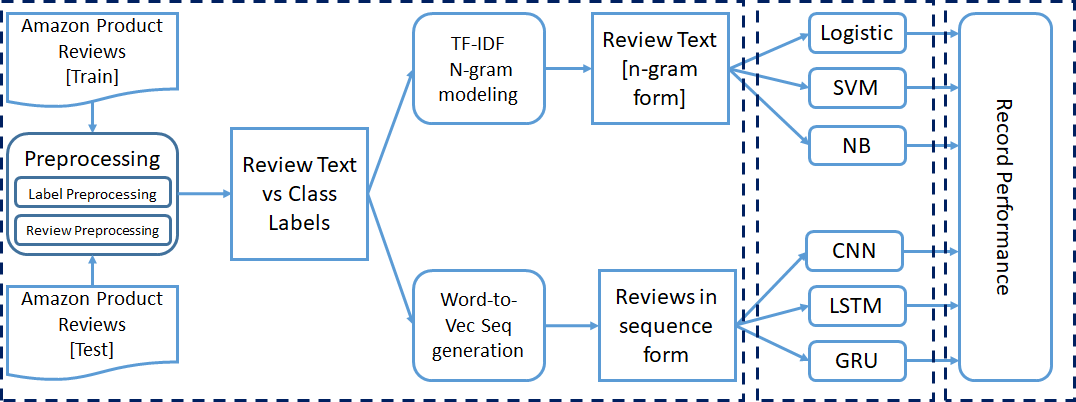
3.1 Pré-processando
3.1.1 Mapeo de etiquetas:
Hemos considerado las calificaciones como la clase para el texto de revisión. El rango del atributo de calificación está entre 1 e 5. Necesitamos asignar estas calificaciones al número de clases, consideradas para el experimento en particular.
uma) Clasificación binaria: –
Aqui, asignamos la calificación 1 e 2 a la clase 0 y calificación 4 e 5 a clase 1. Esta forma de clasificación puede tratarse como un problema de clasificación de sentimientos, donde las reseñas con 1 e 2 calificaciones están en clase negativa y 4 e 5 están en clase positiva.
No hemos considerado las revisiones con una calificación de 3 para el experimento de clasificación binaria. Portanto, obtenemos menos instancias para el TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... en comparación con los otros dos experimentos.
b) Clasificación de tres clases: –
Aqui, ampliamos nuestro experimento de clasificación anterior. Ahora consideramos la calificación 3 como una nueva clase separada. La nueva asignación de calificaciones a clases es la siguiente: Qualificação 1 e 2 asignada a la clase 0 (Negativo), Classificação 3 asignada a la clase 1 (Neutro) y calificación 4 e 5 asignados a la clase 2 (Positivo).
Instancias para clase 1 son muy inferiores a la clase 0 e 2, lo que crea un problema de desequilibrio de clases. Portanto, nós usamos micropromedio al calcular las medidas de rendimiento.
c) Clasificación de cinco clases: –
Aqui, consideramos cada calificación como una clase separada. La asignación es la siguiente: Classificação 1 asignada a la clase 0, Classificação 2 asignada a la clase 1, Classificação 3 asignada a la clase 2, Classificação 4 asignada a la clase 3y la clasificación 5 asignada a la clase 4.
3.1.2 Revisar el procesamiento previo de texto:
Las reseñas de productos de Amazon están en formato de texto. Necesitamos convertir los datos de texto a un formato numérico, que se puede utilizar para entrenar los modelos.
Para los modelos de aprendizaje automático, convertimos el texto de revisión en formato vectorial TF-IDF con la ayuda de el sklearn Biblioteca. En lugar de tomar cada palabra individualmente, consideramos el modelo de n-gramas mientras creamos los vectores TF IDF. El rango de N-gramos se establece en 2 – 3, y el valor de función máxima se establece en 5000.
Para los modelos de aprendizaje profundo, necesitamos convertir los datos de secuencia de texto en datos de secuencia numérica. Aplicamos el palabra a vector modelado para convertir cada palabra en el vector equivalente.
El conjunto de datos contiene una gran cantidad de palabras; portanto, la codificación en caliente 1- es muy ineficaz. Aquí hemos utilizado un pre-entrenado word2Vec modelo para representar cada palabra con un vector de columna de tamaño 300. Establecemos la longitud máxima de la secuencia igual a 70.
Las reseñas con una longitud de palabra inferior a 70 se rellenan con ceros al principio. Para las reseñas con una longitud de palabra superior a 70, seleccionamos las primeras 70 palabras para el procesamiento de word2Vec.
3.2 Entrenamiento del modelo de clasificación
Hemos mencionado anteriormente que hemos tomado tres modelos tradicionales de aprendizaje automático (LR, SVM, NB) y tres modelos de aprendizaje profundo (CNN, LSTM, GRU). El texto preprocesado con la información de la etiqueta se pasa a modelos para su entrenamiento.
No princípio, entrenamos los seis modelos con 50000 instancias y los probamos con 5000 instancias. Para la próxima iteración, agregamos 50000 e 5000 instancias más en el tren y el conjunto de prueba, respectivamente. Realizamos 30 iterações; portanto, Nós consideramos 1.5 M, 150000 instancias para el tren y el conjunto de prueba en la última iteración.
La formación mencionada anteriormente se realiza para los tres tipos de experimentos de clasificación.
3.3 Configuraciones del modelo
Hemos utilizado la configuración predeterminada de hiperparámetros de todos los clasificadores tradicionales utilizados en este experimento. E CNN, el tamaño de entrada es 70 con un tamaño de incrustación de 300. La omisión de la capa de incrustación se establece en 0.3. Se ha aplicado una convolución 1-D en la entrada, con el tamaño de salida de la convolución establecido en 100. El tamaño del kernel se mantiene en 3. ReluA função de ativação do ReLU (Unidade linear retificada) É amplamente utilizado em redes neurais devido à sua simplicidade e eficácia. Definido como ( f(x) = máx.(0, x) ), O ReLU permite que os neurônios disparem apenas quando a entrada é positiva, o que ajuda a mitigar o problema do desbotamento do gradiente. Seu uso demonstrou melhorar o desempenho em várias tarefas de aprendizado profundo, tornando o ReLU uma opção... o função de despertarA função de ativação é um componente chave em redes neurais, uma vez que determina a saída de um neurônio com base em sua entrada. Seu principal objetivo é introduzir não linearidades no modelo, permitindo que você aprenda padrões complexos em dados. Existem várias funções de ativação, como o sigmóide, ReLU e tanh, cada um com características particulares que afetam o desempenho do modelo em diferentes aplicações.... se ha utilizado en la capa de convolución. Para el proceso de agrupación, se utiliza la agrupación máxima. El Optimizador de Adam se utiliza con una Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e... de entropía cruzada.
LSTM y GRU también tienen la misma configuración de hiperparámetros. El tamaño de la Camada de saídao "Camada de saída" é um conceito utilizado no campo da tecnologia da informação e design de sistemas. Refere-se à última camada de um modelo ou arquitetura de software que é responsável por apresentar os resultados ao usuário final. Essa camada é crucial para a experiência do usuário, uma vez que permite a interação direta com o sistema e a visualização dos dados processados.... cambia con el experimento en ejecución.
3.4 Medidas de desempeño

Fórmula de puntuación F
Hemos tomado la puntuación F1 para analizar el rendimiento de los modelos de clasificación con diferentes etiquetas de clase y recuento de instancias. Existe una compensación entre Precision y Recall si intentamos mejorar Recall, Precision se vería comprometida, y lo mismo se aplica a la inversa.
La puntuación F1 combina precisión y recuerdo en forma de media armónica.
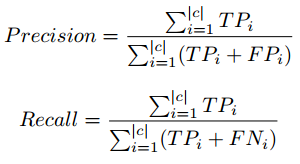
Precisão, fórmula de recuperación en micropromedio
En la clasificación de tres y cinco clases, observamos que el recuento de instancias con calificación 3 es muy inferior en la comparación de otras calificaciones, lo que crea el problema de desequilibrio de clases.
Portanto, utilizamos el concepto de micropromedio al calcular los parámetros de rendimiento. El micropromedio se encarga del desequilibrio de clases al calcular la precisión y la recuperación. Para obtener información detallada sobre Precision, Recall, visite el siguiente enlace: enlace wiki.
4 Resultados y observación
Nesta secção, hemos presentado los resultados de nuestros experimentos con diferentes tamaños de conjuntos de datos y el número de etiquetas de clase. Se ha presentado un gráfico separado para cada experimento. Los gráficos se trazan entre el tamaño del conjunto de pruebas y la puntuación F1.
O que mais, proporcionamos la Figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas.... 5, que contiene seis subparcelas. Cada subparcela corresponde a un clasificador. Hemos presentado la tasa de cambio entre las puntuaciones de rendimiento de dos experimentos con respecto al tamaño variable del conjunto de pruebas.
Figura 2
A Figura 2 presenta el desempeño de los clasificadores en la tarea de clasificación binaria. Neste caso, el tamaño real de la prueba es menor que los datos que hemos tomado para la prueba porque se eliminaron las reseñas con calificación 3.
Los clasificadores de aprendizaje automático (LR, SVM, NB) funcionan de manera constante excepto por ligeras variaciones en los puntos de partida.
El clasificador de aprendizaje profundo (GRU y CNN) comienza con menos rendimiento en comparación con SVM y LR. Después de tres iteraciones iniciales, GRU y CNN dominan continuamente los clasificadores de aprendizaje automático.
El LSTM realiza el aprendizaje más eficaz. LSTM comenzó con el rendimiento más bajo. UMA mediro "medir" É um conceito fundamental em várias disciplinas, que se refere ao processo de quantificação de características ou magnitudes de objetos, Fenômenos ou situações. Na matemática, Usado para determinar comprimentos, Áreas e volumes, enquanto nas ciências sociais pode se referir à avaliação de variáveis qualitativas e quantitativas. A precisão da medição é crucial para obter resultados confiáveis e válidos em qualquer pesquisa ou aplicação prática.... que el conjunto de entrenamiento cruza 0.3 M, LSTM ha mostrado un crecimiento continuo y terminó con GRU.
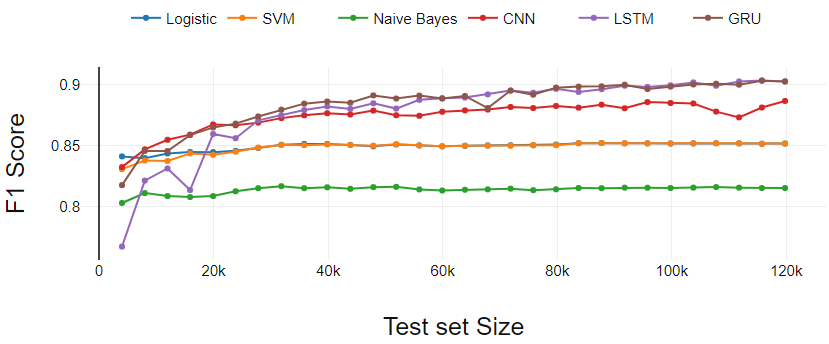
FIG 2. Análisis de rendimiento de clasificación binaria
figura 3
A Figura 3 presenta los resultados del experimento de clasificación de tres clases. El rendimiento de todos los clasificadores se degrada a medida que aumentan las clases. El rendimiento es similar a la clasificación binaria si comparamos un clasificador en particular con otros.
La única diferencia está en el rendimiento de LSTM. Aqui, LSTM ha aumentado continuamente el rendimiento a diferencia de la clasificación binaria. LR funcionó un poco mejor en comparación con SVM. Tanto LR como SVM se desempeñaron por igual en el experimento de clasificación binaria.
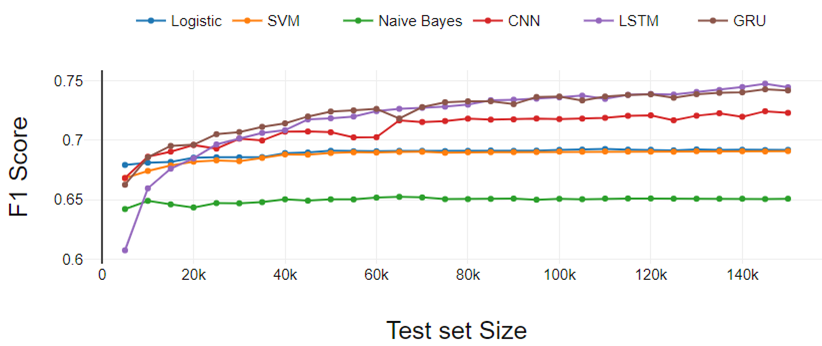
FIG 3. Análisis de rendimiento de clasificación de tres clases
Figura 4
A Figura 4 representa los resultados del experimento de clasificación de cinco clases. Los resultados siguen las mismas tendencias que aparecieron en el experimento de clasificación binaria y de tres clases. Aquí la diferencia de rendimiento entre LR y SVM aumentó un poco más.
Portanto, podemos concluir que la brecha de desempeño de LR y SVM aumenta a medida que aumenta el número de clases.
A partir del análisis general, los clasificadores de aprendizaje profundo funcionan mejor a medida que aumenta el tamaño del conjunto de datos de entrenamiento y los clasificadores tradicionales muestran un rendimiento constante.
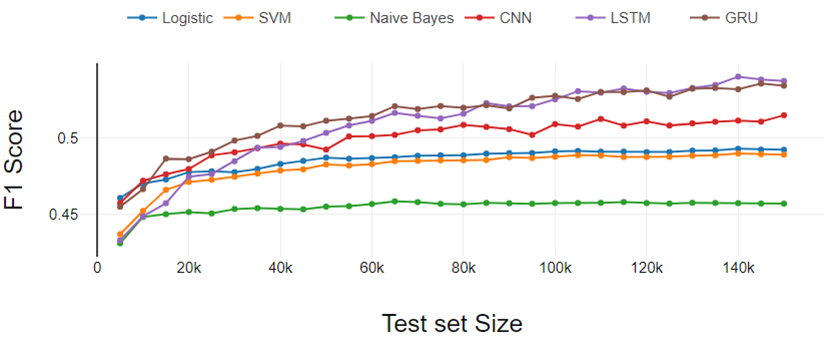
FIG 4. Análisis de rendimiento de clasificación de cinco clases
Figura 5
A Figura 5 representa la relación de rendimiento con respecto al cambio en el número de clases y el tamaño del conjunto de datos. La figura contiene seis subparcelas, una para cada clasificador. Cada subtrama tiene dos líneas; una línea muestra la relación de rendimiento entre la clasificación de tres clases y la clase binaria en diferentes tamaños de conjuntos de datos.
Otra línea representa la relación de rendimiento entre la clasificación de cinco clases y la de tres clases en diferentes tamaños de conjuntos de datos. Hemos encontrado que los clasificadores tradicionales tienen una tasa de cambio constante. Para clasificadores tradicionales, ritmo de cambio es independiente del tamaño del conjunto de datos. No podemos comentar sobre el comportamiento de los modelos de aprendizaje profundo con respecto al cambio en las clases numéricas y el tamaño del conjunto de datos debido al patrón variable en la tasa de cambio.
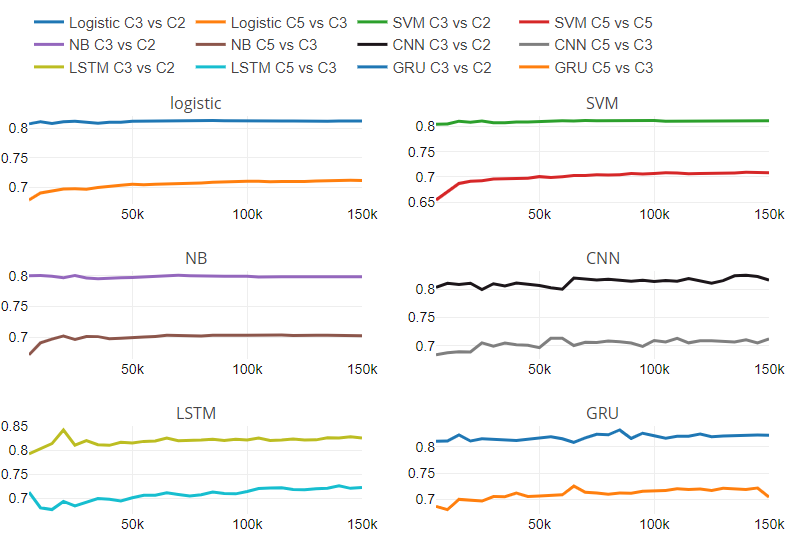
Además del análisis experimental mencionado anteriormente, hemos analizado los datos de texto clasificados erróneamente. Encontramos observaciones interesantes que afectaron la clasificación.
Palabras sarcásticas: –
Los clientes escribieron reseñas sarcásticas sobre los productos. Le han dado la calificación 1 o 2, pero usaron muchas palabras de polaridad positiva. Por exemplo, un cliente calificó a 1 y escribió la siguiente reseña: “¡Oh! ¡¡Qué cargador tan fantástico tengo !! ”. El clasificador se confundió con este tipo de palabras y frases de polaridad.
Uso de palabras de alta polaridad: –
Los clientes han otorgado una calificación promedio (3) pero utilizaron palabras muy polarizadas en sus reseñas. Por exemplo, fantástico, tremendo, notable, patético, etc.
Uso de palabras raras: –
Teniendo un conjunto de datos de tamaño 3.6M, todavía encontramos muchas palabras poco comunes, que afectaron el desempeño de la clasificación. Los errores ortográficos, los acrónimos, las palabras de formas cortas utilizadas por los revisores también son factores importantes.
5. Nota final
Hemos analizado el rendimiento de los modelos tradicionales de aprendizaje automático y aprendizaje profundo con diferentes tamaños de conjuntos de datos y el número de la clase objetivo.
Hemos descubierto que los clasificadores tradicionales pueden aprender mejor que los clasificadores de aprendizaje profundo si el conjunto de datos es pequeño. Con el aumento en el tamaño del conjunto de datos, los modelos de aprendizaje profundo obtienen un impulso en el rendimiento.
Hemos investigado la tasa de cambio en el desempeño del clasificador de binario a tres clases e tres clases a cinco clases problema con el tamaño variable del conjunto de datos.
Nós usamos Duro biblioteca de aprendizaje profundo para la experimentación. Los resultados y los scripts de Python están disponibles en el siguiente enlace: Detecção de vídeo.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





