Na era do Big Data, Python se tornou a linguagem mais pesquisada. Neste artigo, vamos nos concentrar em um aspecto específico do Python que o torna uma das linguagens de programação mais poderosas: multiprocessamento.
Agora, antes de mergulharmos nos fundamentos do multiprocessamento, Eu sugiro que você leia meu artigo anterior sobre Threading em Python, pois pode fornecer um melhor contexto para o artigo atual.
Suponha que você seja um estudante do ensino fundamental que recebeu a difícil tarefa de multiplicar 1200 pares de números lição de casa. Suponha que você seja capaz de multiplicar um par de números em 3 segundos. Mais tarde, no total, são precisos 1200 * 3 = 3600 segundos, o que é 1 tempo para resolver toda a tarefa. Mas você tem que acompanhar seu programa de TV favorito no 20 minutos.
O que você faria? um estudante inteligente, embora desonesto, vai chamar mais três amigos que tenham uma habilidade semelhante e dividir a tarefa. então você terá 250 tarefas de multiplicação no seu prato, o que você vai completar em 250 * 3 = 750 segundos, quer dizer, 15 minutos. Portanto, tu, junto com seus outros 3 amigos, terminará a tarefa em 15 minutos, dando a ele 5 minutos de tempo para fazer um lanche e sentar para assistir seu programa de TV. A tarefa durou apenas 15 minutos quando 4 de vocês trabalharam juntos, o que de outra forma teria levado 1 hora.
Esta é a ideologia básica do multiprocessamento. Se você tem um algoritmo que pode ser dividido em diferentes trabalhadores (processadores), então você pode acelerar o programa. Hoje em dia, as maquinas acompanham 4,8 e 16 núcleos, que pode ser implementado em paralelo.
Processamento múltiplo em ciência de dados
O multiprocessamento tem duas aplicações cruciais na ciência de dados.
1. Processos de entrada-saída
Qualquer pipeline com uso intensivo de dados possui processos de E/S nos quais milhões de bytes de dados fluem por todo o sistema. Em geral, o processo de leitura (entrada) de dados não vai demorar muito, mas o processo de gravação de dados nos armazenamentos de dados leva muito tempo. O processo de escrita pode ser feito em paralelo, economizando muito tempo.
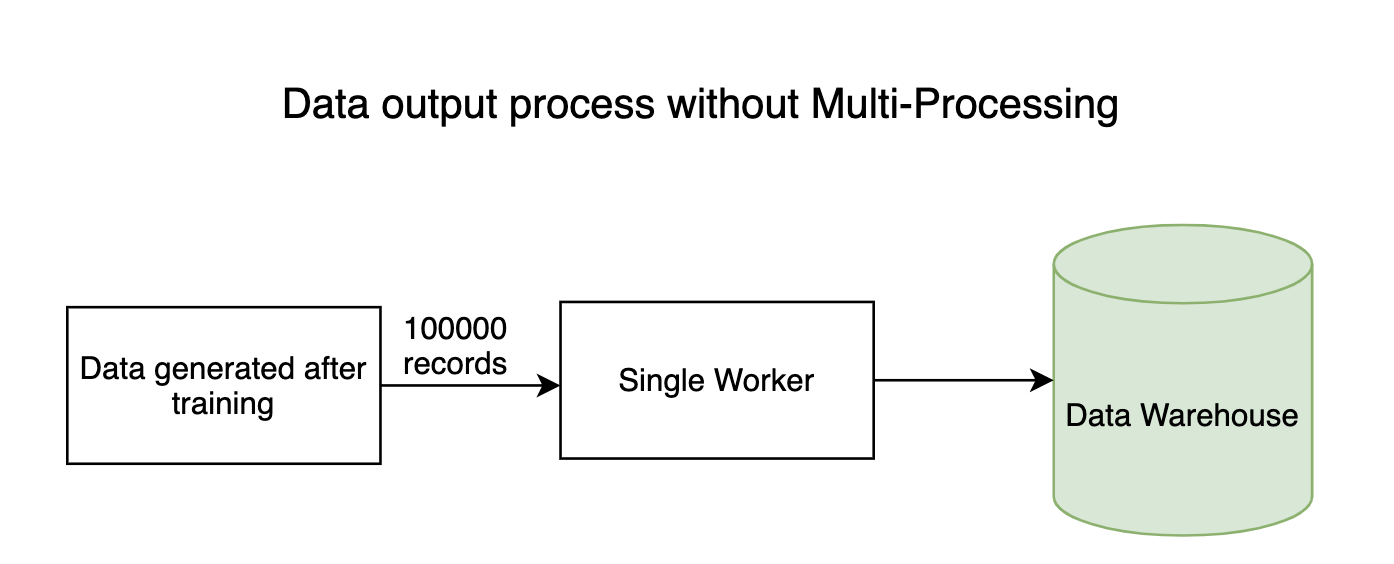
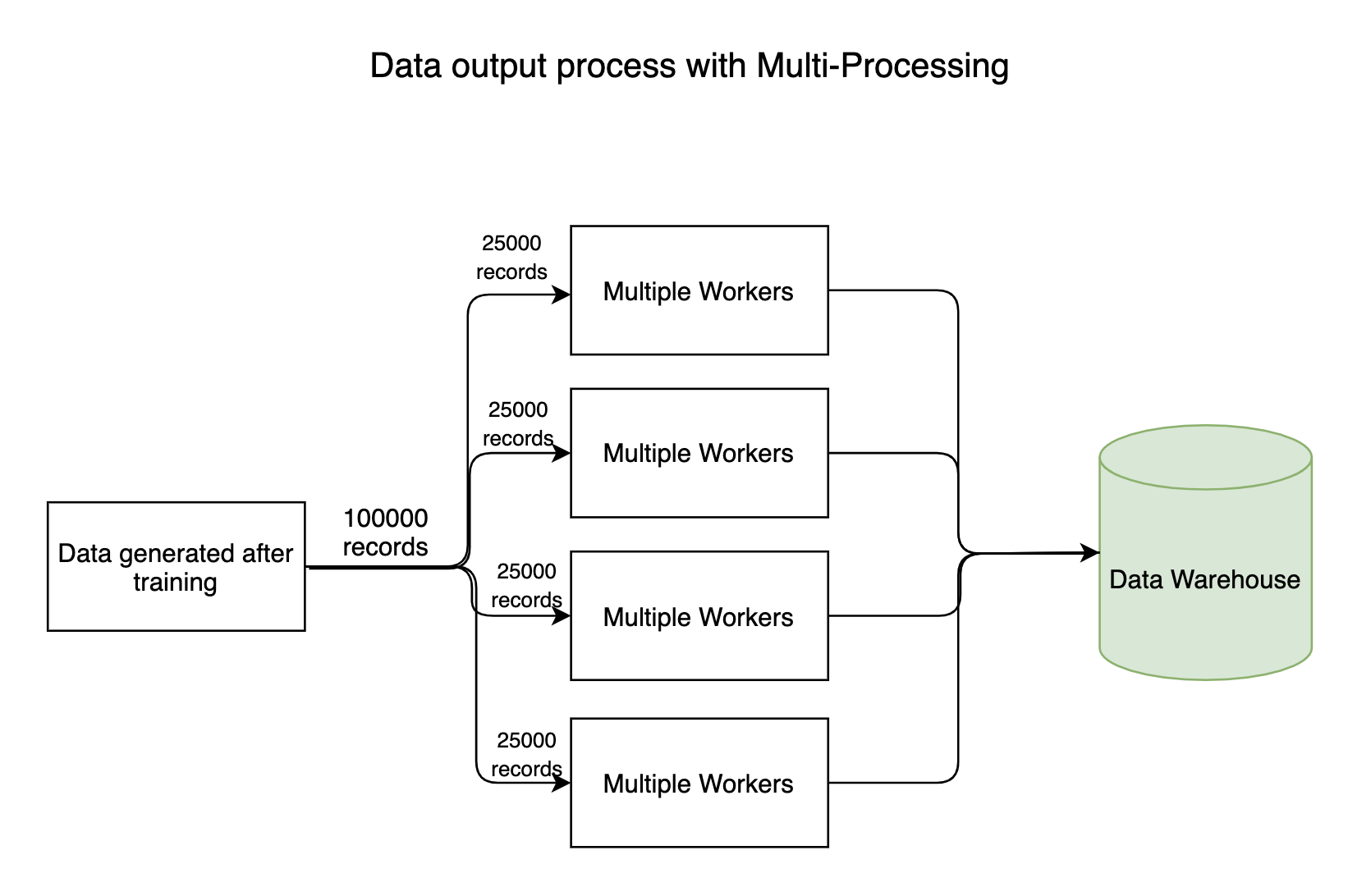
2. Modelos de treinamento
Embora nem todos os modelos possam ser treinados em paralelo, Poucos modelos possuem recursos inerentes que permitem que sejam treinados usando processamento paralelo.. Por exemplo, o algoritmo florestal aleatório implementa várias árvores de decisão para tomar uma decisão cumulativa. Essas árvores podem ser construídas em paralelo. De fato, a API sklearn vem com um parâmetro chamado n_jobs, que oferece uma opção para usar vários trabalhadores.
Processamento múltiplo em Python usando Processo classe-
Agora vamos colocar nossas mãos no Multiprocessamento Biblioteca Python.
Dê uma olhada no seguinte código
import time
def sleepy_man():
imprimir('Começando a dormir')
hora de dormir(1)
imprimir('Dormindo')
tic = time.time()
sleepy_man()
sleepy_man()
toc = time.time()
imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
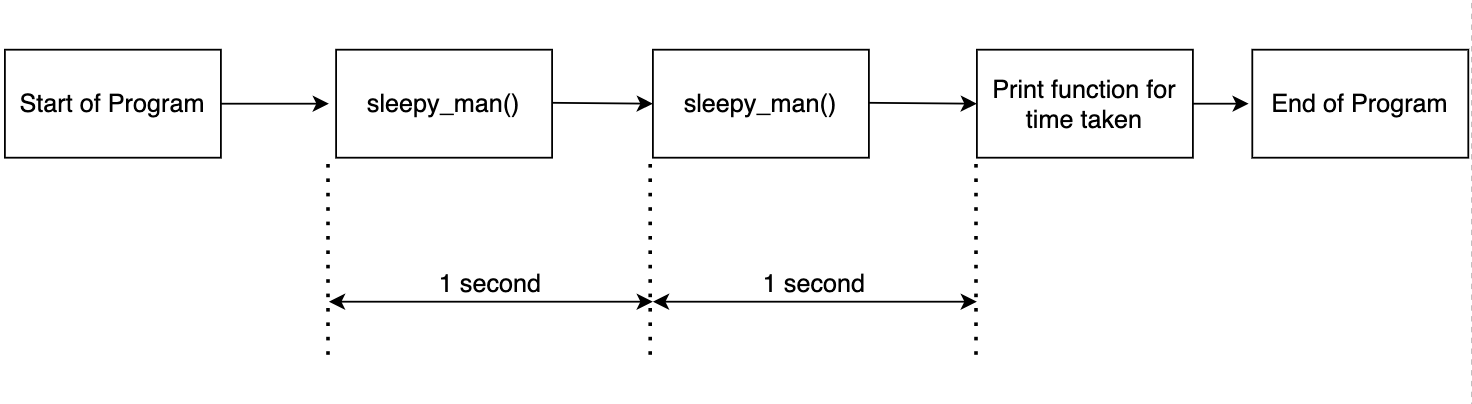
O código acima é simples. A função hombre_soñoliento dormir por um segundo e chamar a função duas vezes. Registramos o tempo necessário para as duas chamadas de função e imprimimos os resultados. A saída é como mostrado abaixo.
Starting to sleep
Done sleeping
Starting to sleep
Done sleeping
Done in 2.0037 Segundos
Isso é esperado como chamamos a função duas vezes e registramos o tempo. o fluxo é mostrado no diagrama a seguir.
Agora vamos incorporar o multiprocessamento no código.
import multiprocessing
import time
def sleepy_man():
imprimir('Começando a dormir')
hora de dormir(1)
imprimir('Dormindo')
tic = time.time()
p1 = multiprocessamento. Processo(sleepy_man alvo=)
p2 = multiprocessamento. Processo(sleepy_man alvo=)
p1.start()
p2.start()
toc = time.time()
imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
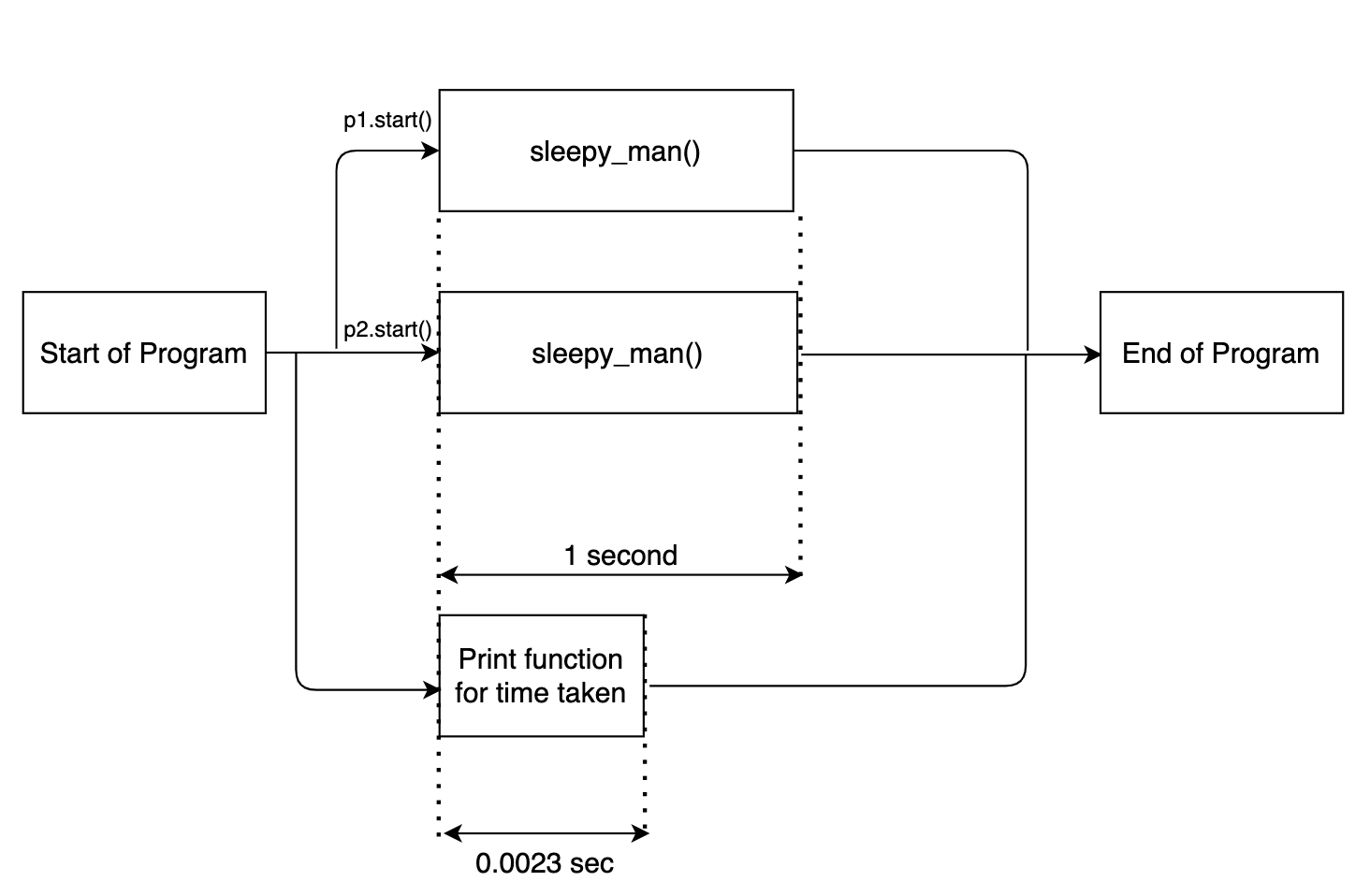
Aqui Multiprocessamento. Processo (alvo = sleepy_man) define uma instância multithreaded. Passamos a função necessária para ser executada, hombre_soñoliento, como um argumento. Nós ativamos as duas instâncias por p1.start ().
A saída é a seguinte:
Doe em 0.0023 seconds
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Agora note uma coisa. A declaração de impressão de registro de tempo foi executada primeiro. Isto é porque, juntamente com as instâncias multithreaded habilitadas para o hombre_soñoliento Função, o código principal da função foi executado separadamente em paralelo. O fluxograma mostrado abaixo vai esclarecer as coisas.
Para executar o resto do programa após a execução das funções multithreaded, precisamos executar a função entrar().
import multiprocessing
import time
def sleepy_man():
imprimir('Começando a dormir')
hora de dormir(1)
imprimir('Dormindo')
tic = time.time()
p1 = multiprocessamento. Processo(sleepy_man alvo=)
p2 = multiprocessamento. Processo(sleepy_man alvo=)
p1.start()
p2.start()
p1.join()
p2.join()
toc = time.time()
imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
Agora, o resto do bloco de código só será executado após as tarefas de multiprocessamento serem executadas. A saída é mostrada abaixo.
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Done in 1.0090 Segundos
O fluxograma é mostrado abaixo.
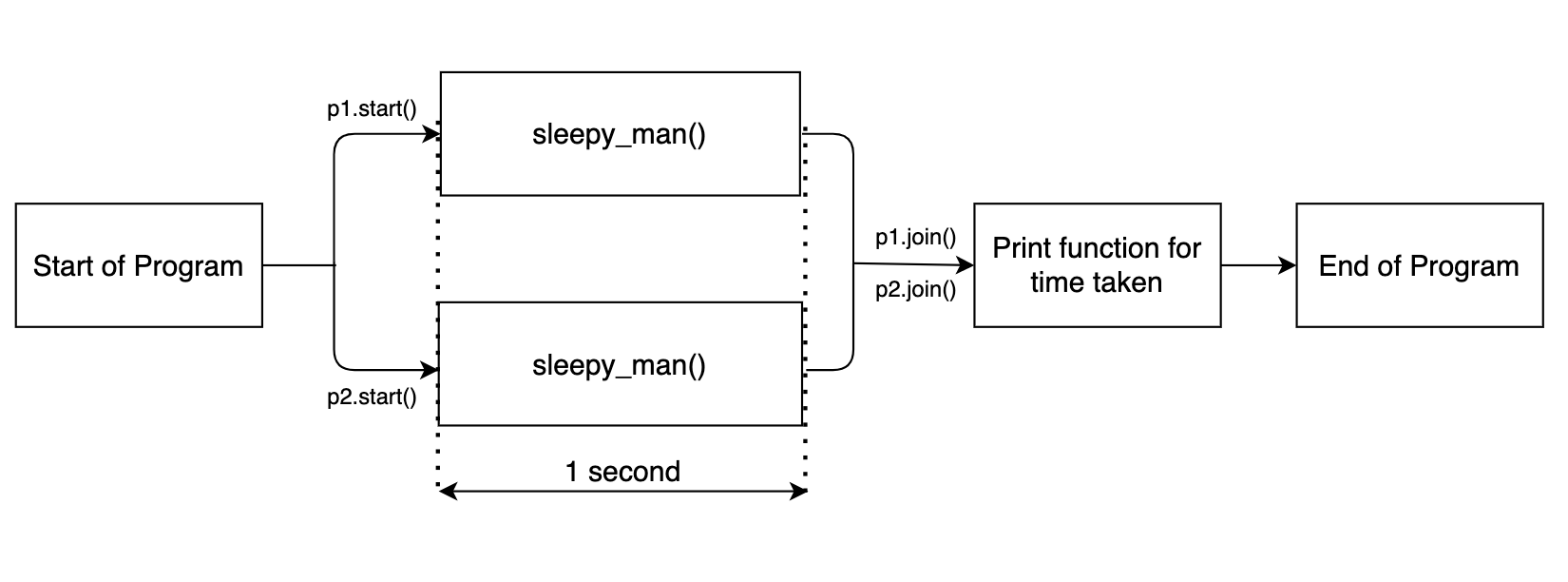
Uma vez que as duas funções de suspensão funcionam em paralelo, a função como um todo leva em torno de 1 segundo.
Podemos definir qualquer número de instâncias de multiprocessamento. Confira o código abaixo. Define 10 diferentes instâncias de multiprocessamento usando um para um loop.
import multiprocessing
import time
def sleepy_man():
imprimir('Começando a dormir')
hora de dormir(1)
imprimir('Dormindo')
tic = time.time()
process_list = []
para eu no alcance(10):
p = multiprocessamento. Processo(sleepy_man alvo=)
p.start()
process_list.append(p)
para o processo em process_list:
process.join()
toc = time.time()
imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
A saída do código acima é mostrada abaixo.
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done in 1.0117 Segundos
Aqui, todas as dez execuções de funções são processadas em paralelo e, portanto, todo o programa leva apenas um segundo. Agora minha máquina não tem 10 processadores. Quando definimos mais processos do que nossa máquina, a biblioteca de multiprocessamento tem lógica para agendar os trabalhos. Então você não precisa se preocupar com isso.
Também podemos passar argumentos para o Processo função usando argumentos.
import multiprocessing
import time
def sleepy_man(segundo):
imprimir('Começando a dormir')
hora de dormir(segundo)
imprimir('Dormindo')
tic = time.time()
process_list = []
para eu no alcance(10):
p = multiprocessamento. Processo(sleepy_man alvo=, argumentos = [2])
p.start()
process_list.append(p)
para o processo em process_list:
process.join()
toc = time.time()
imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
A saída do código acima é mostrada abaixo.
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Starting to sleep
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done sleeping
Done in 2.0161 Segundos
Como passamos um argumento, a hombre_soñoliento função dormiu durante 2 segundos em vez de 1 segundo.
Processamento múltiplo em Python usando Piscina classe-
No último trecho de código, nós executamos 10 processos diferentes usando um loop for. No lugar disso, podemos usar o Piscina método para fazer o mesmo.
import multiprocessing
import time
def sleepy_man(segundo):
imprimir('Começando a dormir por {} segundo'.formato(segundo))
hora de dormir(segundo)
imprimir('Terminou de dormir para {} segundo'.formato(segundo))
tic = time.time()
pool = multiprocessamento.Pool(5)
pool.map(sleepy_man, faixa(1,11))
piscina.fechar()
toc = time.time()
imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
multiprocessamento de pool (5) definir o número de trabalhadores. Aqui definimos o número como 5. pool.map () é o método que desencadeia a execução da função. Chamar pool.map (hombre_soñoliento, classificação (1,11)). Aqui, hombre_soñoliento é a função a ser chamada com os parâmetros para as execuções de funções definidas por classificação (1,11) (geralmente uma lista é aprovada). A saída é a seguinte:
Começando a dormir para 1 seconds Starting to sleep for 2 seconds Starting to sleep for 3 seconds Starting to sleep for 4 seconds Starting to sleep for 5 seconds Done sleeping for 1 seconds Starting to sleep for 6 seconds Done sleeping for 2 seconds Starting to sleep for 7 seconds Done sleeping for 3 seconds Starting to sleep for 8 seconds Done sleeping for 4 seconds Starting to sleep for 9 seconds Done sleeping for 5 seconds Starting to sleep for 10 seconds Done sleeping for 6 seconds Done sleeping for 7 seconds Done sleeping for 8 seconds Done sleeping for 9 seconds Done sleeping for 10 seconds Done in 15.0210 Segundos
Piscina classe é uma melhor maneira de implementar multiprocessamento porque distribui tarefas para processadores disponíveis usando o programa First Enter, primeiro a sair. É quase semelhante à arquitetura de redução de mapas, em essência, atribui entrada a diferentes processadores e coleta saída de todos os processadores como uma lista. Os processos em execução são armazenados na memória e outros processos que não são executados são armazenados fora da memória.
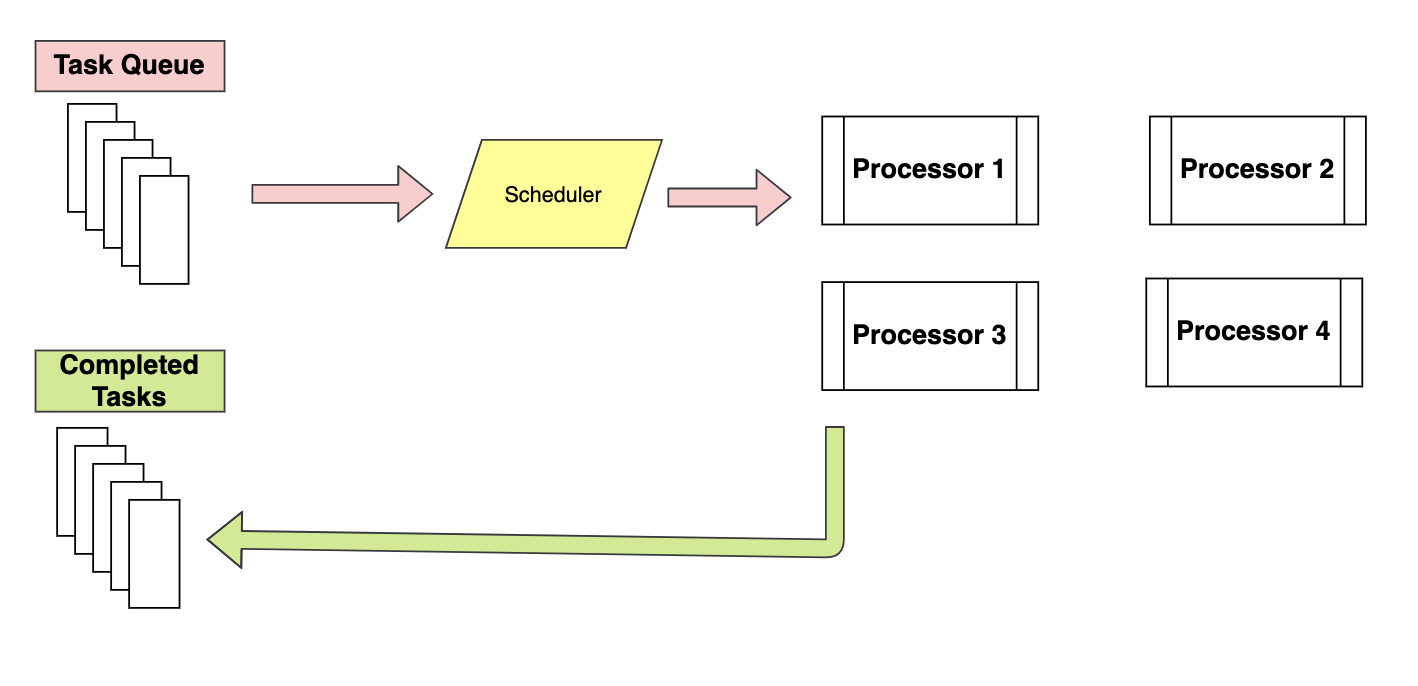
Enquanto em Processo classe, todos os processos executados na memória e execução são programados usando a política fifo.
Comparando o desempenho do tempo para calcular números perfeitos-
Até agora, jogamos com Multiprocessamento funções em dormir funções. Agora vamos tomar uma função que verifique se um número é um número perfeito ou não.. Para aqueles que não sabem, um número é um número perfeito se a soma de seus divisores positivos é igual ao próprio número. Vamos listar os números perfeitos menos ou iguais a 100000. Vamos implementá-lo a partir de 3 formas: usando um loop regular, usando multiprocesso. Processo () e multiprocesso. Piscina ().
Usando um regular para um loop
import time def is_perfect(n): sum_factors = 0 para eu no alcance(1, n): E se (n % i == 0): sum_factors = sum_factors + i if (sum_factors == n): imprimir('{} é um número perfeito'.formato(n)) tic = time.time() para n no intervalo(1,100000): is_perfect(n) toc = time.time() imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
O resultado do programa acima é mostrado abaixo.
6 é um número perfeito
28 é um número perfeito
496 é um número perfeito
8128 is a Perfect number
Done in 258.8744 Segundos
Usando uma aula de processo
import time import multiprocessing def is_perfect(n): sum_factors = 0 para eu no alcance(1, n): E se(n % i == 0): sum_factors = sum_factors + i if (sum_factors == n): imprimir('{} é um número perfeito'.formato(n)) tic = time.time() processos = [] para eu no alcance(1,100000): p = multiprocessamento. Processo(target=is_perfect, args=(eu,)) processes.append(p) p.start() para o processo em processos: process.join() toc = time.time() imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
O resultado do programa acima é mostrado abaixo.
6 é um número perfeito
28 é um número perfeito
496 é um número perfeito
8128 is a Perfect number
Done in 143.5928 Segundos
Como você pode ver, conseguimos uma redução do 44,4% no tempo em que implementamos o multiprocessamento usando Processo classe, em vez de um loop para regular.
Usando uma aula de Pool
import time import multiprocessing def is_perfect(n): sum_factors = 0 para eu no alcance(1, n): E se(n % i == 0): sum_factors = sum_factors + i if (sum_factors == n): imprimir('{} é um número perfeito'.formato(n)) tic = time.time() pool = multiprocessamento.Pool() pool.map(is_perfect, faixa(1,100000)) piscina.fechar() toc = time.time() imprimir("Feito em {:.4f} segundo'.formato(toc-tic))
O resultado do programa acima é mostrado abaixo.
6 é um número perfeito
28 é um número perfeito
496 é um número perfeito
8128 is a Perfect number
Done in 74.2217 Segundos
Como você pode ver, em comparação com um loop para regular, conseguimos uma redução do 71,3% no tempo de cálculo, e comparado com o Processo classe, conseguimos uma redução do 48,4% no tempo de cálculo.
Portanto, é muito evidente que ao implementar um método apropriado a partir do Multiprocessamento biblioteca, podemos alcançar uma redução significativa no tempo de cálculo.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





