Este artigo foi publicado como parte do Data Science Blogathon.
Introdução
Olá! Hoje farei o meu melhor para explicar intuitivamente como funcionam as redes neurais convolucionais recorrentes (CRNN). Quando tentei aprender como o CRNN funciona pela primeira vez, Eu descobri que as informações estavam divididas em vários sites e que diferentes níveis de “profundidade”, então, tentarei explicá-los de uma forma que, no final deste artigo, saberei exatamente como funcionam e por que apresentam melhor desempenho em algumas categorias do que em outras.
Neste artigo, Vou supor que você já sabe um pouco sobre como funciona uma rede neural simples. No caso de você precisar de uma pequena revisão de como funciona ou mesmo se você não sabe como eles funcionam, Recomendo que você assista aos vídeos bem feitos que explicam como funcionam que coloquei no link no final do artigo. Fornecerei todas as informações que você considerar necessárias para compreender intuitivamente como funciona o CRNN.
Neste artigo, cobriremos os seguintes tópicos, então fique à vontade para pular aqueles que você já conhece:
- O que são redes neurais convolucionais, como funcionam e por que precisamos deles?
- O que são redes neurais recorrentes, como funcionam e por que precisamos deles?
- · O que são e por que precisamos de redes neurais recorrentes convolucionais? + exemplo de reconhecimento de texto manuscrito
- · Mais leituras e links
O que são redes neurais convolucionais, como funcionam e por que precisamos deles?
O mais fácil de responder é a última pergunta, Por que nós precisamos deles? Para isso, vamos dar um exemplo. Digamos que queremos descobrir se temos um gato ou um cachorro na imagem. Para simplificar a explicação, Vamos primeiro pensar em uma imagem de 3 × 3. Nesta imagem, temos uma característica importante no retângulo azul (como a cara de um cachorro, uma carta ou qualquer que seja a característica importante).
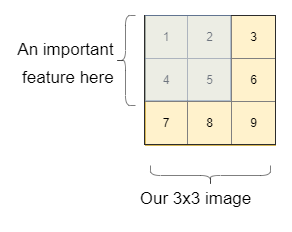
Vamos ver como uma rede neural simples reconheceria a importância e a ligação entre os pixels.
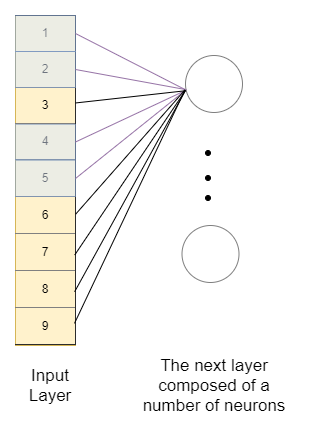
Como podemos ver, nós vamos precisar “aplanar” a imagem para alimentá-la para uma rede neural densa. Ao fazer isso, perdemos o contexto espacial na imagem do elemento completo com o fundo e também as partes do elemento entre si. Imagine como será difícil para a rede neural aprender que eles estão relacionados. O que mais, teremos muitos pesos para treinar, então vamos precisar de mais dados e, portanto, mais tempo para treiná-los.
Então, podemos ver vários problemas com esta abordagem:
- O contexto espacial está perdido
- Muito mais peso para imagens maiores
- Mais pesos resultam em mais tempo e mais dados necessários
Só se houvesse outro jeito ... Espere!! Existem! É aqui que as redes neurais convolucionais entram em ação para salvar o dia.. Sua principal função é extrair características relevantes da entrada (uma imagem, por exemplo) usando filtros. Esses filtros são escolhidos aleatoriamente primeiro e, em seguida, treinados como fazem os pesos.. Eles são modificados pela Rede Neural para extrair e encontrar as características mais relevantes.
De acordo, até agora estabelecemos que as redes neurais convolucionais, o que vou usar como CNN, use filtros para extrair recursos. Mas, O que exatamente são filtros e como eles funcionam?
Filtros são matrizes contendo diferentes valores que deslizam sobre a imagem (por exemplo) para analisar as características. Se a matriz for, por exemplo, 3x3x3, o recurso extraído terá 3x3x3 de tamanho. Se a matriz for de tamanho 5 × 5, o recurso que ele detectará terá um tamanho máximo de 5 × 5 na imagem, e assim por diante. Ao analisar uma janela de pixel, entendemos a multiplicação por elementos entre o filtro e a janela coberta.
Então, por exemplo, se tivermos uma imagem com um tamanho de 6 × 6 e um filtro 3 × 3, podemos imaginar o filtro deslizando sobre a imagem, e toda vez que pousa em uma nova janela, a análise, o que podemos ver representado na imagem abaixo, apenas para as duas primeiras linhas da imagem:
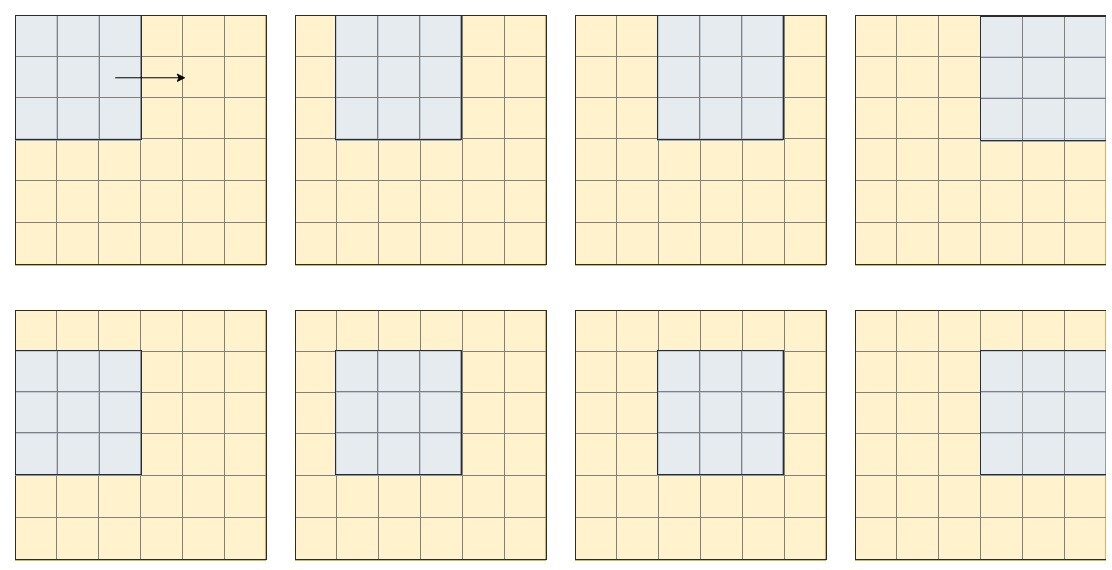
Dependendo do que precisamos extrair, podemos mudar a etapa do filtro (tanto vertical quanto horizontalmente, no exemplo acima, o filtro dá um passo em ambas as direções).
Depois de fazer a multiplicação (por elementos), o resultado se torna o novo pixel da imagem. Então, depois de “analisar” a primeira janela, obtemos o primeiro pixel da nossa imagem, e assim por diante. Vemos que no caso apresentado acima, a imagem final terá um tamanho de 5 × 5. Para ter a imagem final com o mesmo tamanho, podemos aplicar os filtros depois de preencher a imagem com imaginação (adicionar uma linha e coluna imaginárias no início e no final), mas os detalhes ficam para outro momento para discutir.
Para ver ainda melhor como funciona a convolução, podemos ver exemplos de filtros e o efeito que eles causam na imagem de saída:

Podemos ver como diferentes filtros detectam e “eles extraem” características diferentes. A função de treinar uma rede neural de convolução é encontrar os melhores filtros para extrair a característica mais relevante para nossa tarefa..
Então, para concluir a parte sobre redes neurais de convolução, podemos resumir as informações em 3 ideias simples:
- Que são: Redes neurais convolucionais são um tipo de redes neurais que usam a operação de convolução (deslizando um filtro em uma imagem) para extrair características relevantes.
- Por que nós precisamos deles: trabalhar melhor com dados (em vez de usar redes neurais densas normais) em que há uma forte correlação entre, por exemplo, pixels porque o contexto espacial não é perdido.
- Como eles funcionam: use filtros para extrair recursos. Filtros são matrizes que "deslizam" sobre a imagem. Eles são modificados no período de treinamento para extrair as características mais relevantes.
O que são redes neurais recorrentes, como funcionam e por que precisamos deles?
Enquanto as redes neurais convolucionais nos ajudam a extrair características relevantes na imagem, Redes neurais recorrentes ajudam a rede neural a levar em consideração informações do passado para fazer previsões ou analisar.
Portanto, sim, temos, por exemplo, a seguinte matriz: {2, 4, 6}, e queremos prever o que virá a seguir, podemos usar uma rede neural recorrente, Porque, em cada passo, levará em consideração o que era antes disso.
Podemos visualizar uma célula recorrente simples, como mostrado na imagem a seguir:
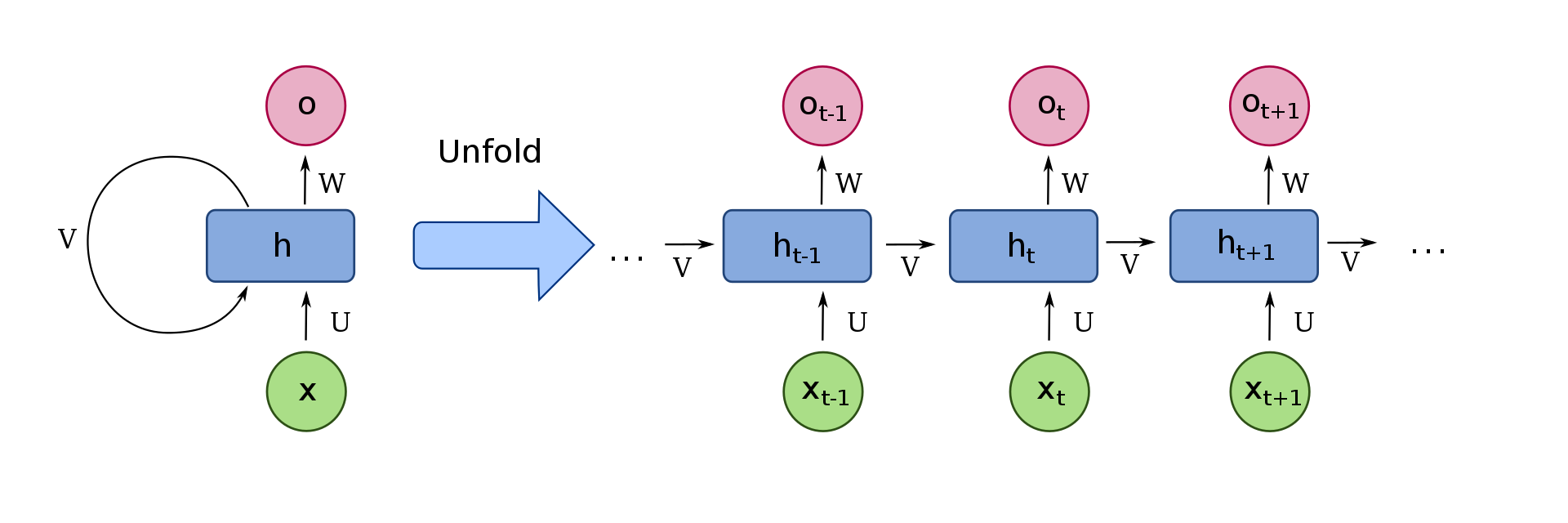
Primeiro, vamos nos concentrar no lado direito da imagem. Aqui, xt são as entradas recebidas na etapa de tempo t. Para seguir o mesmo exemplo, estes podem ser os números da matriz mencionada acima, x0 = 2, x1 = 4, x2 = 6. Para levar em consideração o que era antes da passagem do tempo, a propriedade que os torna parte de uma rede neural recorrente, temos que receber informações da etapa de tempo anterior, que nesta imagem representamos como v Cada célula tem uma chamada “Estado”, que contém intuitivamente as informações que são enviadas para a próxima célula.
Então, para recapitular, xt é a entrada da célula. Mais tarde, a célula decide quais são as informações importantes, levando em consideração as informações das etapas de tempo anteriores, recebido através do "v", e envie para a próxima célula. O que mais, temos a opção se quisermos retornar esta informação importante que a célula considerou, através da “o” na imagem, saída de célula.
Para representar o processo acima mencionado de uma forma mais compacta, nós podemos “dobrar” as células, representado no lado esquerdo da imagem.
Não entraremos em detalhes sobre o tipo exato de células recorrentes, uma vez que existem muitas opções, e explicar em detalhes como eles funcionam levaria muito tempo. Se você estiver interessado, Deixei alguns links que achei muito úteis no final do artigo.
O que são e por que precisamos de redes neurais recorrentes convolucionais?
+ exemplo de reconhecimento de texto manuscrito
Agora temos todas as informações importantes para entender como funciona uma rede recorrente convolucional.
A maioria das vezes, rede neural convolucional analisa a imagem e a envia para a parte recorrente das características importantes detectadas. O recorrente analisa essas características para, levando em consideração as informações anteriores para descobrir quais são algumas ligações importantes entre essas características que influenciam a produção.
Para entender um pouco mais sobre como um CRNN funciona em algumas tarefas, Vamos pegar o reconhecimento de texto manuscrito como exemplo.
Vamos imaginar que temos imagens que contêm palavras e queremos treinar a NNet para nos dar qual palavra está inicialmente na imagem..
Em primeiro lugar, gostaríamos que nossa rede neural fosse capaz de extrair características importantes para letras diferentes, como loops de “g” o “eu”, ou mesmo círculos de “uma” você “o”. Para isso, podemos usar uma rede neural convolucional. Como explicado acima, CNN usa filtros para extrair os recursos importantes (vimos como diferentes filtros têm diferentes efeitos na imagem inicial). Claro, esses filtros irão, na prática, detectar mais recursos abstratos que não podemos realmente entender, mas intuitivamente podemos pensar em recursos mais simples, como acima mencionado.
Então, gostaríamos de analisar essas características. Vejamos por que não podemos decidir qual letra se baseia apenas em suas próprias características.. Na imagem abaixo, vemos que a letra é "a" (de para") você "o" (de para).
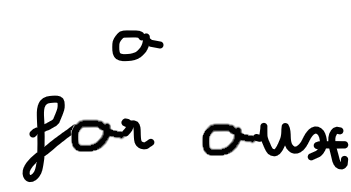
A diferença está na forma como a letra está ligada às outras letras. Então precisaríamos saber informações de lugares anteriores na imagem para sermos capazes de determinar a letra. Soa familiar? É aqui que entra a parte RNN. Analisar recursivamente as informações extraídas pela CNN, onde a entrada para cada célula pode ser os recursos detectados em um segmento específico da imagem, como descrito abaixo, com solo 10 segmentos (menos do que usaríamos em modelos reais):
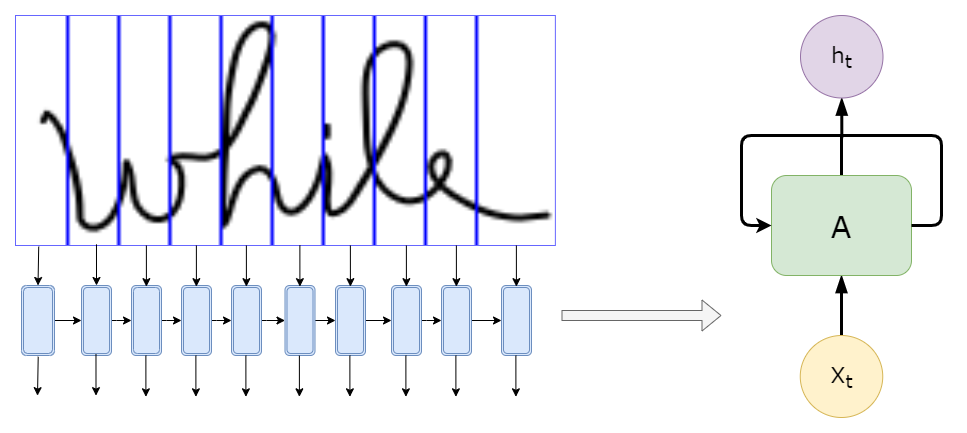
Não alimentamos o RNN com a própria imagem, como mostrado na imagem acima, mas com as características extraídas daquele “segmento”.
Também pudemos ver que processar a imagem para frente é tão importante quanto processar a imagem para trás., para que possamos adicionar uma camada de células que processam os recursos de outra maneira, levando ambos em consideração ao calcular a produção. Ou mesmo verticalmente, dependendo da tarefa a ser realizada.
Viva! Finalmente temos a imagem analisada: as características extraídas e analisadas em relação umas às outras. Tudo o que temos que fazer agora é adicionar uma camada que calcula a perda e um algoritmo que decodifica a saída, para isto, podemos querer usar um CTC (Classificação temporal conexionista) para reconhecimento de texto manuscrito, mas esse é um tópico interessante por si só. e acho que merece outro artigo.
Conclusões
Neste artigo, discutimos brevemente como as redes neurais recorrentes convolucionais funcionam, como eles analisam e extraem recursos e um exemplo de como eles podem ser usados.
A rede neural convolucional extrai as características aplicando filtros relevantes e a rede neural recorrente analisa essas características, levando em consideração as informações recebidas nas etapas de tempo anteriores.





