Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Estatisticas, aprendizado de máquina, modelagem matemática e inteligência artificial é conhecida como análise preditiva. Com a ajuda de dados anteriores, faz previsões. Usamos análises preditivas em nosso dia a dia sem pensar muito. Por exemplo, prever as vendas de um item (por exemplo, flores) em um mercado para um determinado dia. Se for dia dos namorados, As vendas de rosas seriam altas! Podemos facilmente dizer que as vendas de flores seriam maiores nos feriados do que em dias normais.
Na análise preditiva, encontramos os fatores responsáveis, nós coletamos dados, aplicamos técnicas de aprendizado de máquina, mineração de dados, modelagem preditiva e outras técnicas analíticas para prever o futuro. As percepções de dados incluem padrões, a relação entre diferentes fatores que podem ser previamente desconhecidos. Desvendar esses conhecimentos ocultos vale mais do que você pensa. As empresas usam análises preditivas para melhorar seus processos e atingir seus objetivos. As informações obtidas a partir de dados estruturados e não estruturados podem ser usadas para análises preditivas.
Como as estatísticas de dados ajudam?
Nos últimos anos, As organizações optaram por coletar grandes quantidades de dados assumindo que, se eles coletarem uma quantia suficiente, acabará por levar a informações comerciais relevantes. Até o Instagram e o Facebook fornecem informações sobre contas comerciais. Mas, dados em sua forma bruta são inúteis, não importa o quão grande. Quanto mais dados para analisar, mais difícil é separar informações comerciais valiosas de irrelevantes. Uma estratégia de percepção de dados baseia-se no potencial real dos dados, você deve primeiro determinar por que os está usando e que valor comercial espera obter deles. A seguir, explica como obter informações valiosas dos dados e como usá-las.
1. Definição da declaração do problema / Objetivo de negócios.
Defina os resultados do projeto, Os entregáveis, o escopo do esforço, objetivos de negócios, preparar um questionário para os dados a serem obtidos com base no objetivo do negócio.
2. Coleta de dados com base nas respostas às perguntas criadas com base na declaração do problema.
Com base no questionário, coletar respostas como conjuntos de dados.
3. Integre dados de várias fontes.
A mineração de dados para análise preditiva prepara dados de várias fontes para análise. Isso fornece uma visão abrangente das interações do cliente.
4. Análise de dados com ferramentas / software de analítica. Podemos visualizar os dados para observar padrões e relações entre vários fatores.
A análise de dados é o processo de inspeção, limpar, transformar e modelar dados a fim de descobrir informações úteis para chegar a uma conclusão.
5. Validar suposições, hipóteses e testá-las usando modelos estatísticos.
A análise estatística permite validar os pressupostos, hipóteses e testá-las usando modelos estatísticos. As suposições são baseadas na declaração do problema, formado durante EDA.
6. Geração de modelos
O modelo é gerado com algoritmos para automatizar o processo com os novos dados combinados com os dados existentes. Vários modelos também podem ser combinados para melhores resultados.
7. Implementar o modelo para gerar previsões e monitorar sua precisão.
A implementação do modelo preditivo oferece a opção de implementar os resultados analíticos no processo de tomada de decisão diária para obtenção de resultados., relatórios e resultados automatizando decisões baseadas em modelagem.
O que mais, gerenciamos e monitoramos o desempenho do modelo para garantir que ele está entregando os resultados esperados.
Dados incorretos ou incompletos podem levar a modelos ruins e precisão, causando caos. Por isso é extremamente necessário ter um conjunto de dados adequado para obter informações e treinar o modelo.. A análise preditiva tem seus próprios desafios, mas pode levar a resultados de negócios inestimáveis, incluindo a aquisição de clientes antes de eles saírem, otimização do orçamento comercial e satisfação da demanda do cliente.
Modelos e algoritmos
Várias técnicas de domínio, incluindo aprendizado de máquina, Mineração de dados, as estatísticas, análise e modelagem, são usados em análises preditivas. Os algoritmos preditivos podem ser amplamente classificados em dois grupos: modelos de aprendizado de máquina e modelos de aprendizado profundo. Alguns deles são descritos neste artigo. Embora tenham seus próprios méritos e deméritos, um grande mérito de todos eles é que são reutilizáveis e podem ser treinados utilizando algoritmos com regras específicas da empresa. A análise preditiva é um processo iterativo que envolve a coleta, pré-processando, modelagem e implementação de dados para obter resultados. Podemos automatizar o processo para nos fornecer novas previsões com base nos novos dados que são fornecidos regularmente ao longo do tempo..
Depois que um modelo é treinado, podemos inserir novos dados para obter previsões e não há necessidade de treinar continuamente, mas uma desvantagem é que ele precisa de muitos dados para ser treinado. Uma vez que a análise preditiva é baseada em algoritmos de aprendizado de máquina, requer classificação adequada de dados em rótulos, o que, pelo contrário, causaria baixo desempenho e precisão. A generalização é um problema, uma vez que o modelo tem pouca capacidade de transferir suas descobertas de um caso para outro. Embora existam alguns problemas de aplicabilidade quando se trata de descobertas derivadas de um modelo de análise preditiva, pode ser resolvido por certos métodos, como transferência de aprendizagem.
Modelos de análise preditiva
-
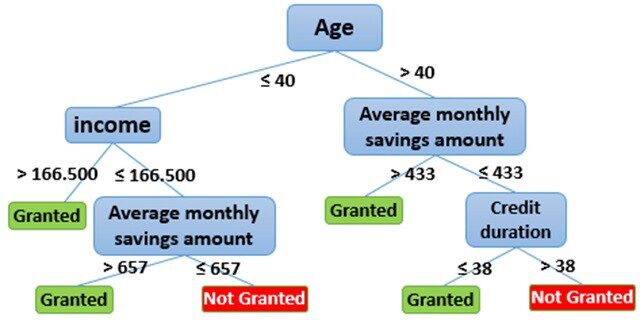
Modelo de classificação
É um dos modelos mais simples. Classifique os novos dados com base no que você aprendeu com os dados históricos. Eles são melhores para classificação binária ao responder perguntas binárias como Sim / Não, Verdade / Falso, mas também podem ser usados para classificação multiclasse. Árvores de decisão, máquinas de vetores de suporte são alguns algoritmos de classificação.
P.ej. : A aprovação do empréstimo é um caso de uso clássico de um modelo de classificação. Outro exemplo são as mensagens / e-mails de detecção de spam.
-
Modelo de clustering
Um modelo de agrupamento classifica os pontos de dados em grupos com base na similaridade de atributos. Existem muitos algoritmos de agrupamento, mas nenhum algoritmo pode ser considerado o melhor para todos os casos de uso. É um algoritmo de aprendizagem não supervisionado, ao contrário da classificação supervisionada.
Por exemplo: Agrupe alunos de uma escola com base em sua localização na cidade para serviços de transporte. Agrupe clientes com base em suas preferências de item para recomendar produtos relacionados aos seus interesses.
-
Modelo de previsão
Sendo um dos modelos de análise preditiva mais usados, lida com a previsão de valores métricos, estimar um valor numérico para novos dados com base no que foi aprendido com dados históricos. Pode ser aplicado sempre que houver dados numéricos disponíveis.
Não .: Previsão de trânsito na via principal de uma cidade durante diferentes períodos. Lojas estimando a disponibilidade de produtos em seu armazém.
-
Modelo outlier
Como o nome sugere, depende de entradas de dados anômalos em seu conjunto de dados. Um outlier pode ser um erro de entrada de dados, Erro de medição, erro experimental, intencional, erro de processamento de dados, erro de amostragem ou erro natural. Embora outliers possam causar baixo desempenho e precisão, alguns nos ajudam a encontrar novidades ou observar novas inferências.
Não .: Roubo de cartão de crédito / débito.
-
Modelo de série temporal
Pode ser usado para qualquer sequência de pontos de dados com um período de tempo como parâmetro de entrada. Use dados anteriores para desenvolver uma métrica numérica e prever dados futuros usando essa métrica.
Não .: previsão do tempo, mercado de ações / previsão de preço de criptomoeda.
Alguns algoritmos preditivos comuns são Florestas Aleatórias, modelo linear generalizado, padrão de gradiente reforçado, agrupamento de K-means e Profeta. A floresta aleatória é uma combinação de árvores de decisão, em que eles tentam alcançar o menor erro possível usando a técnica de “embolsado” o “impulso”. O modelo linear generalizado é uma variante mais complexa do modelo linear geral que treina muito rapidamente. A variável de resposta pode ter qualquer forma de tipo de distribuição exponencial que forneça uma compreensão clara de como os preditores influenciam o resultado..
Embora sejam resistentes a sobreajuste, requerem um grande conjunto de dados para treinamento e são suscetíveis a outliers. O Gradient Boosted Model é um modelo de previsão baseado em um conjunto de árvores de decisão. Ao contrário de florestas aleatórias, construa uma árvore de cada vez e corrija os bugs anteriores enquanto constrói uma nova árvore. K-means é útil quando se procura implementar um plano personalizado em um grande conjunto de dados. Usado em modelos de agrupamento. O profeta é um algoritmo usado em séries temporais e modelos de previsão. Não é só automático, também incorpora heurísticas e suposições úteis. É popular por ser rápido, confiável e robusto.
Algum você
A Análise Preditiva, como disse, já tem muitas aplicações em diferentes domínios. Por mencionar alguns,
- Cuidados de saúde
- Análise de coleção
- Detecção de fraude
- Gestão de riscos
- Marketing direto
- Cruz-
Então, Como exatamente eles ajudam em seus domínios? Recebemos alertas quando fazemos login em nossa conta do Gmail a partir de um novo dispositivo. Recebemos alertas quando usamos nossos cartões de crédito / débito em novos lugares. Como eles detectam isso? Com análise preditiva, Os examinadores de fraude pegam alguns conjuntos de variáveis predeterminadas que são conhecidas por estarem envolvidas em eventos de fraude anteriores e colocam essas variáveis em processos para determinar a probabilidade de que os resultados ou eventos futuros sejam ou não fraude. Suponha que você use regularmente seus cartões de crédito em Kerala, quando seu cartão de crédito é usado em Nova Delhi, é um possível caso de fraude. O Commonwealth Bank usa análises para prever a probabilidade de atividade fraudulenta para qualquer transação antes de ser autorizada., dentro do 40 milissegundos após o início da transação.
Além de detectar fraude em sinistros, o setor de seguro saúde está tomando medidas para identificar os pacientes com maior risco de doenças crônicas e encontrar as melhores intervenções. Scripts expressos, uma grande empresa de benefícios farmacêuticos, usa testes para identificar aqueles que não aderem aos tratamentos prescritos, que gera economia significativa. Aplicativos de análise preditiva analisam gastos, uso e outro comportamento do cliente, levando a uma venda cruzada eficiente ou venda de produtos adicionais para clientes existentes para uma organização que oferece vários produtos.
Sobre o autor
Eu sou keerthana, um estudante de ciência de dados fascinado por matemática e suas aplicações em outros domínios. Também estou interessado em escrever artigos relacionados à matemática e ciência de dados. Você pode se conectar comigo em LinkedIn e Instagram. Confira meus outros itens aqui.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





