Este artigo foi publicado como parte do Data Science Blogathon
Introdução
A obtenção de dados completos e de alto desempenho nem sempre é o caso no Aprendizado de Máquina. Enquanto trabalhava em qualquer declaração de problema do mundo real ou tentava construir qualquer tipo de projeto como o Machine Learning Practioner, precisa dos dados.
Para atender à necessidade de dados na maioria das vezes, você precisa obter dados da API e, se o site não fornece a API, a única opção que resta é Web Scraping.
Neste tutorial, vamos aprender como você pode usar API, extrair dados e salvar como quadro de dados.

Tabela de conteúdo
- Obtendo dados de uma API
-
- O que é API
- Importância de usar API
- Como obter uma API
- Código prático para extrair dados da API
- Obtenção de dados usando bancos de dados SQL
- EndNote
Obtendo dados de uma API
O que é API
API significa Interface de Programação de Aplicativos. API basicamente funciona como uma interface entre dois softwares de comunicação. Agora vamos entender como?
Importância de usar API
Considere um exemplo, se tivermos que reservar uma passagem de trem, então temos várias opções como o site IRCTC, Yatra, faça minha viagem, etc. Agora, todas essas são organizações diferentes, e suponha que reservamos o número do assento 15 do vagão B15, se alguém visitar e tentar reservar o mesmo lugar em um software diferente, Será reservado ou não? Vai aparecer como reservado.
Embora sejam empresas diferentes, software diferente, são capazes de compartilhar esta informação. Portanto, o compartilhamento de informações ocorre entre vários sites via API, é por isso que APIs são importantes.
Cada organização fornece serviços em vários sistemas operacionais, como ios, andróide, que são integrados com um único base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos..... Portanto, eles também usam API para obter dados do banco de dados para vários aplicativos.
Agora vamos entender de forma prática como obter dados usando um quadro de dados usando Python.
Como obter uma API?
Usaremos o site oficial do TMDB, que fornece diferentes APIs para obter diferentes tipos de dados. vamos obter dados de filmes com melhor classificação em nosso quadro de dados. Para obter os dados, deve passar API.
Visite a Site TMDB e registre-se e comece sessãoo "Sessão" É um conceito-chave no campo da psicologia e da terapia. Refere-se a uma reunião agendada entre um terapeuta e um cliente, onde os pensamentos são explorados, Emoções e comportamentos. Essas sessões podem variar em duração e frequência, e seu principal objetivo é facilitar o crescimento pessoal e a resolução de problemas. A eficácia das sessões depende da relação entre o terapeuta e o terapeuta.. com sua conta do Google. Depois disso, na seção do seu perfil, configurações de visita. No painelUm painel é um grupo de especialistas que se reúne para discutir e analisar um tópico específico. Esses fóruns são comuns em conferências, Seminários e debates públicos, onde os participantes compartilham seus conhecimentos e perspectivas. Os painéis podem abordar uma variedade de áreas, Da ciência à política, e seu objetivo é incentivar a troca de ideias e a reflexão crítica entre os participantes.... Configuração à esquerda, no último segundo opção, você pode encontrar uma opção como API, basta clicar nele e gerar sua API.
Use a chave de API para obter dados de filmes com as melhores classificações
Agora que você tem sua própria chave de API, visite o site do desenvolvedor TMDB API que você pode ver na seção API no topo. Clique em Filmes e o tour receberá a classificação mais alta agora, na melhor janela de classificação, visite a opção Experimente agora, onde você pode ver no lado direito do botão de envio de solicitação, tem um link para os filmes com melhor classificação.
https://api.themoviedb.org/3/movie/top_rated?api_key =<<Chave API>>&idioma = en-US&page = 1
Copie o link e, em vez da chave API, cole a chave de API que você gerou e abra o link, Você poderá ver dados semelhantes a JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software...
Agora, para entender esses dados, existem várias ferramentas como o visualizador JSON. Se você desejar, você pode abri-lo e colar o código no visualizador. É um dicionário e as informações necessárias sobre os filmes estão presentes na chave de resultados.
Os dados totais estão presentes em 428 páginas e o número total de filmes é 8551. Portanto, temos que criar um quadro de dados que terá 8551 linhas e os campos que iremos extrair são id, título do filme, data de lançamento, descrição geral, popularidade, voto. média, contagem de votos. Portanto, o quadro de dados que receberemos terá o formato 8551 * 7.
Código prático para obter dados da API
Abra seu Jupyter Notebook para escrever o código e extrair os dados para o quadro de dados. Instale a biblioteca e as solicitações do pandas se você não tiver o uso do comando pip
pip instalar pandas pedidos de instalação de pip
Agora defina sua chave de API no link e faça uma solicitação ao site do TMDB para extrair dados e salvar a resposta em um variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.....
api_key = sua chave de API
link = "https://api.themoviedb.org/3/movie/top_rated?api_key =<<Chave API>>&idioma = en-US&page = 1"
resposta = solicitações.get(ligação)
Não se esqueça de mencionar sua chave de API no link. E depois de executar o código acima, sim imprima a resposta, você pode ver a resposta em 200, o que significa que tudo está funcionando bem e você obteve os dados na forma de JSON.
Os dados que queremos estão nos principais resultados, então tente imprimir a chave de resultado.
response.json()["resultados"]
Para criar o quadro de dados das colunas necessárias, podemos usar o quadro de dados do pandas e ele obterá o quadro de dados de 20 classifica que tem os melhores filmes na página 1.
data = pd.DataFrame(response.json()["resultados"])[['Eu iria','título','visão global','popularidade','data de lançamento','vote_average','vote_count']]
Queremos os dados do 428 páginas inteiras, então colocaremos o código no loop for e solicitaremos o site repetidamente para páginas diferentes e, a cada vez, obteremos 20 linhas e sete colunas.
para eu no alcance(1, 429):
resposta = solicitações.get("https://api.themoviedb.org/3/movie/top_rated?api_key =<Chave API>&idioma = en-US&page ={}".formato(eu))
temp_df = pd.DataFrame(response.json()["resultados"])[['Eu iria','título','visão global','popularidade','data de lançamento','vote_average','vote_count']]
data.append(temp_df, ignore_index = False)
Portanto, temos o quadro de dados completo com 8551 filas. formatamos um número de página para solicitar uma página diferente a cada vez. E mencione sua chave de API no link removendo a tag HTML. Vai demorar pelo menos 2 minutos para correr. O quadro de dados que obtivemos é parecido com este.
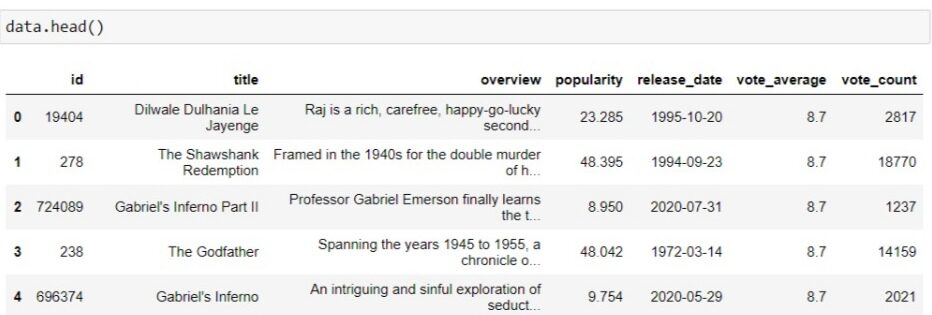
Salve os dados em um arquivo CSV para que você possa usá-lo para analisar, processar e criar um projeto nele.
Obtenha dados de um banco de dados SQL
Trabalhar com bancos de dados SQL é fácil com Python. Python fornece várias bibliotecas para se conectar ao banco de dados e ler consultas SQL e extrair dados da tabela SQL para o Pandas Dataframe.
Para fins de demonstração, estamos usando um conjunto de dados populacionais de distritos e cidades do mundo carregado no Kaggle em formato de consulta SQL. Você pode acessar o conjunto de dados de aqui.
Baixe o arquivo e envie-o para seu banco de dados local. Você pode usar MySQL, XAMPP, SQLite ou qualquer banco de dados de sua escolha. TODOS os bancos de dados oferecem opção de importação, apenas clique nele, selecione o arquivo baixado e carregue-o.
Agora estamos prontos para conectar o Python ao banco de dados e extrair os dados SQL para o Dataframe do Pandas. Para fazer uma conexão, instalar biblioteca de conectores MySQL.
!pip install mysql.connector
Depois de instalar, importe as bibliotecas necessárias e direcione a conexão ao banco de dados usando o método de conexão.
importar numpy como np importar pandas como pd import mysql.connector conn = mysql.connector.connect(host ="localhost", usuário ="raiz", senha ="", banco de dados ="Mundo")
Depois de conectar com o banco de dados com sucesso, podemos consultar um banco de dados e extrair dados em um quadro de dados.
city_data = pd.read_sql_query("SELECIONE * DA cidade", con)
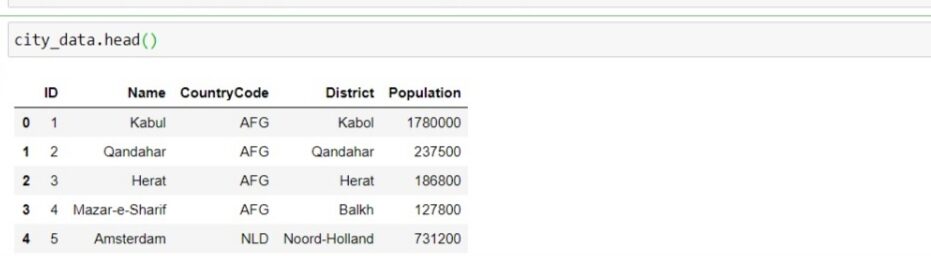
Portanto, extraímos os dados para o dataframe com sucesso e é fácil trabalhar com bancos de dados com a ajuda de python. Você também pode extrair dados filtrando com consultas SQL.
EndNote
Espero que tenha sido um artigo incrível que o ajude a aprender como extrair dados de diferentes fontes. A obtenção de dados com a ajuda da API é usada principalmente pelo Data Scientist para coletar dados do grande e vasto conjunto de dados para uma melhor análise e melhor desempenho do modelo..
Como um iniciante, na maioria das vezes você obtém o arquivo de dados preciso, mas este não é o caso o tempo todo, você precisa trazer os dados de diferentes fontes que serão barulhentos e trabalhar neles para tomar melhores decisões de negócios.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





